关于mysql的查询优化
由于工作原因,最近甲方客户那边多次反应了他们那边的系统查询速度慢,经过排除之后,发现他们那边的数据库完全没有用到索引,简直坑得一笔,通过慢查询日志分析,为数据表建立了适当的索引之后,查询速度明显的提高上来了,所以这次也总结一下如果进行mysql的优化查询。
1.慢查询
mysql自身是有一个慢查询时间和慢查询记录的,但是在默认情况下,我们的mysql不会记录慢查询,需要在启动mysql时候,指定记录慢查询才可以
(1)使用show variables like 'long_query_time'命令,查看慢查询时间
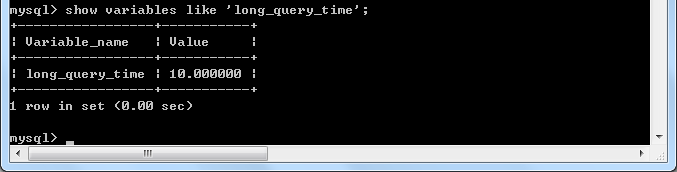
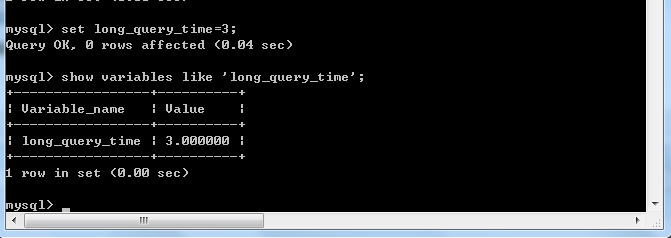
现在慢查询时间是10s,但是我们可以通过set long_query_time对其进行临时修改(关闭掉这次会话之后慢查询时间会被重置回10)
另外,我们也可以通过show variables like '%slow%'这个命令来查看慢查询的配置
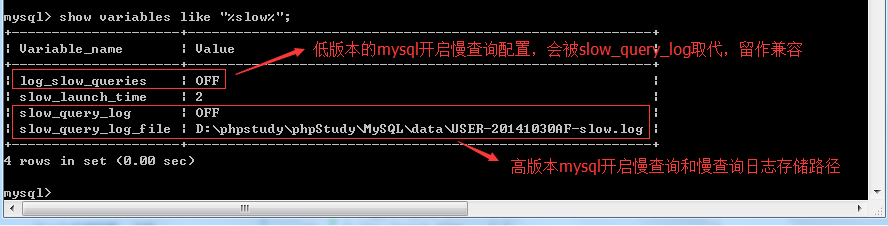
慢查询日志默认是不启用的,所以我们要打开它,有两种方法,一种是用set重新设置变量,另一种就是直接修改配置文件,这里建议用修改变量的方法(因为是临时的)
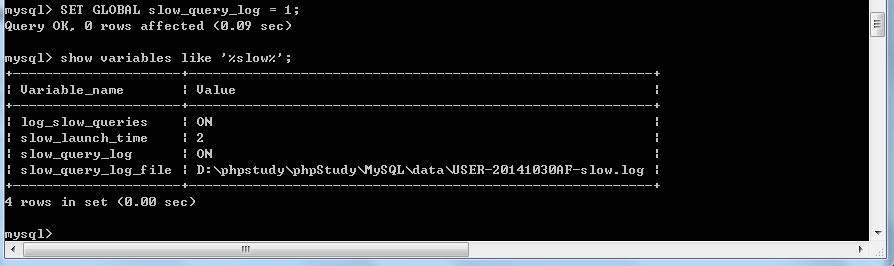
想要测试是否开启慢查询,可以使用select sleep(3),运行之后去对应的目录找到慢查询日志是否有记录就可以了,这里就不再多说了。
2.构建大数据量进行测试
因为之前优化的查询里面存储着客户的数据,这里不方便用于展示,所以我们可以自己来构建一个大数据的表,这里就用到了mysql的存储过程(使用存储过程无非就是想要插入数据运行的时间减少而已,其实我们可以通过php写代码批量插入)
存储过程怎样写我就不多说了,而且网上也能找到大量的测试数据代码,所以这里我就直接上代码了
(1)创建表
CREATE TABLE dept(
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '编号',
dname VARCHAR(20) NOT NULL DEFAULT "" COMMENT '名称',
loc VARCHAR(13) NOT NULL DEFAULT "" COMMENT '地点'
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE emp (
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '编号',
ename VARCHAR(20) NOT NULL DEFAULT "" COMMENT '名字',
job VARCHAR(9) NOT NULL DEFAULT "" COMMENT '工作',
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '上级编号',
hiredate DATE NOT NULL COMMENT '入职时间',
sal DECIMAL(7,2) NOT NULL COMMENT '薪水',
comm DECIMAL(7,2) NOT NULL COMMENT '红利',
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '部门编号'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
分别是部门表(dept)和员工表(emp),这里我是故意没有创建主键,等下留作演示用
(2)创建自定义函数
delimiter $$
创建一个自定义函数,目的是返回1-10的随机数
create function rand_num()
returns int
begin
return floor(1+rand()*10);
end$$
创建一个自定义函数,目的是返回随机字符串
create function rand_string(n INT) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end$$
为了能使存储过程正常执行,要先把mysql的语句结束符号修改成$$,创建完后用delimiter命令改回;就可以了
(3)创建插入数据的存储过程
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
(4)调用call insert_emp(100001,4000000)创建400w条数据

插入400w条数据用了8分半钟,这时我们可以去看下慢查询日志是否记录了

3.查询优化
首先,我们在没有索引的情况下,对员工表进行查询
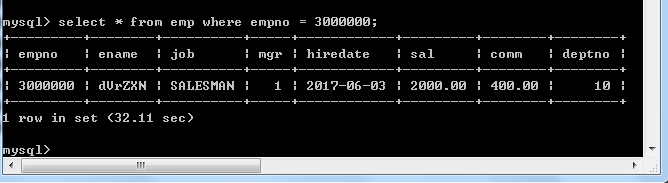
查找员工号为300w的数据,用时32.11s,这估计是谁都不能忍的事,要是被老板发现了,估计就要直接掀桌了,所以我们就用explain工具来分析一下这条查询

那么,现在我们为员工编号加上主键索引,结果又会如何呢
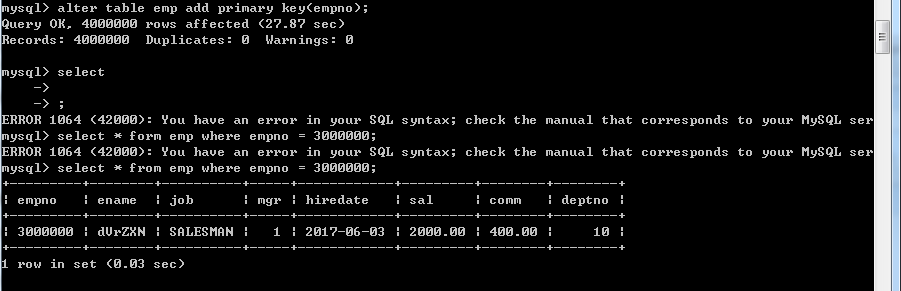
只用了0.03秒,查询效率提高了1000倍以上!
现在我们来分析一下这个查询语句吧

那么,现在我们来试试多表查询的情况,先向部门表插入几条数据,这里就不再多说了

可以发现,用了51s才查询完毕(因为数据过多,所以用ctrl+c中断输出,这里补充上查询语句select * from dept left join emp on dept.deptno=emp.deptno where dept.deptno=1;)

用explain分析可以看出两个表都是全表扫描
为emp表加上deptno的索引后,查询结果和分析结果如下
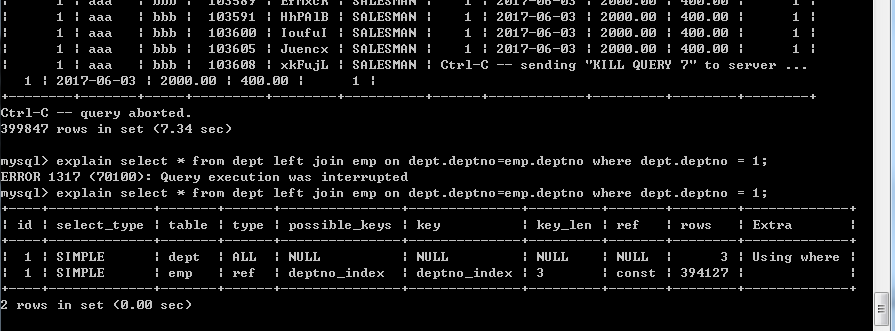
只用了7.34s,而且查询数量明显相比第一次只查询了不到40w条,查询效率提高了7倍以上
然而我们也发现了,dept表仍然没有用到索引,所以我们试试看为dept表加上主键索引
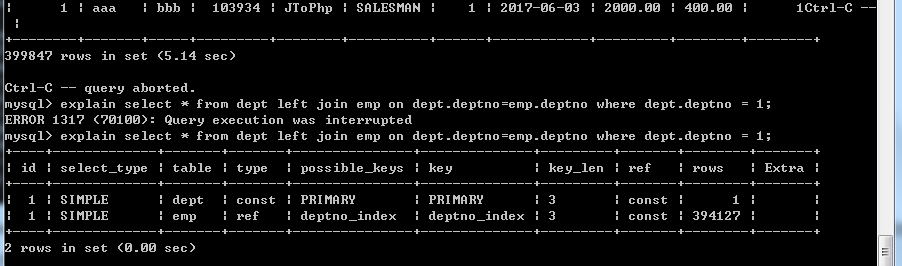
虽然有所优化,但是并不明显,其实上述实验结果也可以看出,总查询条数(rows)/总数据量的比值越小,索引优化查询的效果越明显
mysql的查询优化就暂时先介绍到这里了,想要具体的对mysql进行优化,其实还需要explain各参数的详解和使用索引的注意事项等,这些我会以后再个博客进行详细的介绍的
,这里就先挖个坑吧
explain详解:(待补充)
mysql使用索引的注意事项:(待补充)
关于mysql的查询优化的更多相关文章
- php mysql 一个查询优化的简单例子
PHP+Mysql是一个最经常使用的黄金搭档,它们俩配合使用,能够发挥出最佳性能,当然,如果配合Apache使用,就更加Perfect了. 因此,需要做好对mysql的查询优化.下面通过一个简单的例子 ...
- WebAPI调用笔记 ASP.NET CORE 学习之自定义异常处理 MySQL数据库查询优化建议 .NET操作XML文件之泛型集合的序列化与反序列化 Asp.Net Core 轻松学-多线程之Task快速上手 Asp.Net Core 轻松学-多线程之Task(补充)
WebAPI调用笔记 前言 即时通信项目中初次调用OA接口遇到了一些问题,因为本人从业后几乎一直做CS端项目,一个简单的WebAPI调用居然浪费了不少时间,特此记录. 接口描述 首先说明一下,基于 ...
- MySQL in查询优化
https://blog.csdn.net/gua___gua/article/details/47401621 MySQL in查询优化<一> 原创 2015年08月10日 17:57: ...
- 查询优化 | MySQL慢查询优化
Explain查询:rows,定位性能瓶颈. 只需要一行数据时,使用LIMIT1. 在搜索字段上建立索引. 使用ENUM而非VARCHAR. 选择区分度高的列作为索引. 采用扩展索引,而不是新建索引 ...
- MySQL 慢查询优化
为什么查询速度会慢 1.慢是指一个查询的响应时间长.一个查询的过程: 客户端发送一条查询给服务器 服务器端先检查查询缓存,如果命中了缓存,则立可返回存储在缓存中的结果.否则进入下一个阶段 服务器端进行 ...
- MySQL SQL查询优化技巧详解
MySQL SQL查询优化技巧详解 本文总结了30个mysql千万级大数据SQL查询优化技巧,特别适合大数据里的MYSQL使用. 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 ...
- 《MySQL慢查询优化》之SQL语句及索引优化
1.慢查询优化方式 服务器硬件升级优化 Mysql服务器软件优化 数据库表结构优化 SQL语句及索引优化 本文重点关注于SQL语句及索引优化,关于其他优化方式以及索引原理等,请关注本人<MySQ ...
- MySQL 的查询优化
说起 MySQL 的查询优化,相信大家收藏了一堆奇技淫巧:不能使用 SELECT *.不使用 NULL 字段.合理创建索引.为字段选择合适的数据类型..... 你是否真的理解这些优化技巧?是否理解它背 ...
- MySQL慢查询优化
MySQL数据库是常见的两个瓶颈是CPU和I/O的瓶颈,CPU在饱和的时候一般发生在大量数据进行比对或聚合时.磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应用分布在网络上,那么查询量相当大的 ...
随机推荐
- springboot学习问题一:启动springboot报错端口被占用解决办法
一:问题 二:分析原因 springboot启动默认端口为8080,现在提示被占用,那我们可以修改springboot的启动端口,换一个未被占用的端口即可 三:解决方法 打开application.p ...
- leetcode-easy-string- 38 Count and Say
mycode 91.28% 思路:题意实在太难理解了,尤其是英文又不好,只能参看下别人的资料,理解下规则.终于理解,题意是n=1时输出字符串1:n=2时,数上次字符串中的数值个数,因为上次字符串有 ...
- P5436 【XR-2】缘分
P5436 [XR-2]缘分 题解 很显然给出一个n,要想使缘分最大,一定要选 n 和 n-1 对吧 但是这里有一个特盘,当 n=1 时,缘分应该为1 而不是0 代码 #include<bits ...
- 统计学_样本量估计_python代码实现
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- Grunt打包Electron,生成exe的安装包
在之前的博客:3.electron打包生成exe文件 我们已经得到了electron打包好的应用了,目录如下,但是我们如何整合成一个安装程序,发给客户使用呢? 我们可以使用grunt-electron ...
- httpparase + httpclient 的运用
这篇文章介绍了 HtmlParser 开源包和 HttpClient 开源包的使用,在此基础上实现了一个简易的网络爬虫 (Crawler),来说明如何使用 HtmlParser 根据需要处理 Inte ...
- Redis 配置 CONFIG 命令
redis.conf 文件在 安装目录下 CONFIG 命令查看或设置配置项 先登陆 src/redis-cli -a -a 后面是密码,默认为空,没有密码直接登陆 src/redis-cli 1.查 ...
- P2814 家谱
我真没什么创意了woc.. so,为什么一道水题是蓝色的???哦哦哦,水好像就是蓝色的,emmm那就不是恶意评分了嘤嘤嘤 ... 好吧实际上可能是非c党对于字符串的处理需要进行编号和结构体,会麻烦一点 ...
- TensorFlow基础总结
1.基础概念 Tensor:类型化的多维数组,图的边:Tensor所引用的并不持有具体的值,而是保持一个计算过程,可以使用session.run()或者t.eval()对tensor的值进行计算. O ...
- layer最大话.最小化.还原回调方法
layer.open({ type: 1, title: ‘在线调试‘, content: ‘这里是内容‘, ...