Redis 复制原理及特性
摘要
早期的RDBMS被设计为运行在单个CPU之上,读写操作都由经单个数据库实例完成,复制技术使得数据库的读写操作可以分散在运行于不同CPU之上的独立服务器上,Redis作为一个开源的、优秀的key-value缓存及持久化存储解决方案,也提供了复制功能,本文主要介绍Redis的复制原理及特性。
Redis复制概论
数据库复制指的是发生在不同数据库实例之间,单向的信息传播的行为,通常由被复制方和复制方组成,被复制方和复制方之间建立网络连接,复制方式通常为被复制方主动将数据发送到复制方,复制方接收到数据存储在当前实例,最终目的是为了保证双方的数据一致、同步。

复制示意图
Redis复制方式
Redis的复制方式有两种,一种是主(master)-从(slave)模式,一种是从(slave)-从(slave)模式,因此Redis的复制拓扑图会丰富一些,可以像星型拓扑,也可以像个有向无环:
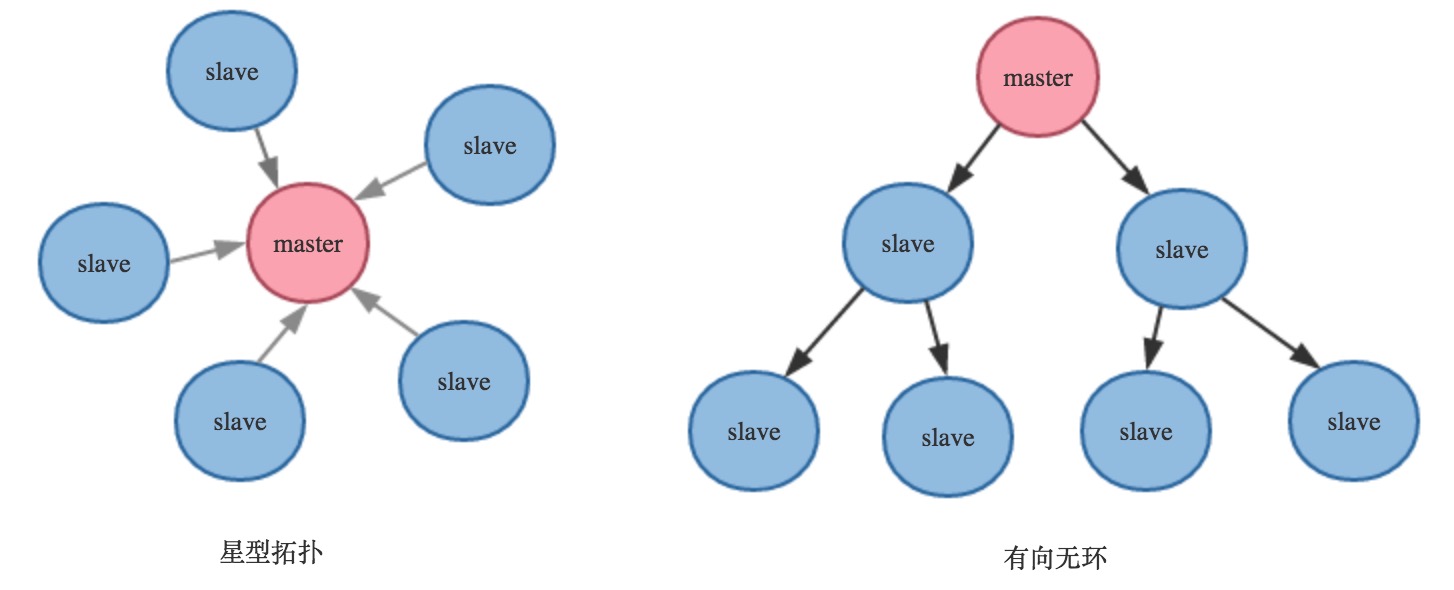
Redis集群复制结构图
通过配置多个Redis实例独立运行、定向复制,形成Redis集群,master负责写、slave负责读。
复制优点
通过配置多个Redis实例,数据备份在不同的实例上,主库专注写请求,从库负责读请求,这样的好处主要体现在下面几个方面:
1、高可用性
在一个Redis集群中,如果master宕机,slave可以介入并取代master的位置,因此对于整个Redis服务来说不至于提供不了服务,这样使得整个Redis服务足够安全。
2、高性能
在一个Redis集群中,master负责写请求,slave负责读请求,这么做一方面通过将读请求分散到其他机器从而大大减少了master服务器的压力,另一方面slave专注于提供读服务从而提高了响应和读取速度。
3、水平扩展性
通过增加slave机器可以横向(水平)扩展Redis服务的整个查询服务的能力。
复制缺点
复制提供了高可用性的解决方案,但同时引入了分布式计算的复杂度问题,认为有两个核心问题:
- 数据一致性问题,如何保证master服务器写入的数据能够及时同步到slave机器上。
- 编程复杂,如何在客户端提供读写分离的实现方案,通过客户端实现将读写请求分别路由到master和slave实例上。
上面两个问题,尤其是第一个问题是Redis服务实现一直在演变,致力于解决的一个问题。
复制实时性和数据一致性矛盾
Redis提供了提高数据一致性的解决方案,本文后面会进行介绍,一致性程度的增加虽然使得我能够更信任数据,但是更好的一致性方案通常伴随着性能的损失,从而减少了吞吐量和服务能力。然而我们希望系统的性能达到最优,则必须要牺牲一致性的程度,因此Redis的复制实时性和数据一致性是存在矛盾的。
Redis复制原理及特性
slave指向master
举个例子,我们有四台redis实例,M1,R1、R2、R3,其中M1为master,R1、R2、R3分别为三台slave redis实例。在M1启动如下:
./redis-server ../redis8000.conf --port 8000
下面分别为R1、R2、R3的启动命令:
./redis-server ../redis8001.conf --port 8001 --slaveof 127.0.0.1 8000
./redis-server ../redis8002.conf --port 8002 --slaveof 127.0.0.1 8000
./redis-server ../redis8003.conf --port 8003 --slaveof 127.0.0.1 8000
这样,我们就成功的启动了四台Redis实例,master实例的服务端口为8000,R1、R2、R3的服务端口分别为8001、8002、8003,集群图如下:
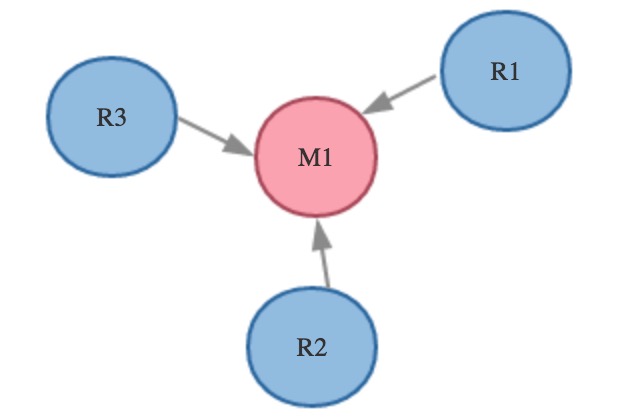
Redis集群复制拓扑
上面的命令在slave启动的时候就指定了master机器,我们也可以在slave运行的时候通过slaveof命令来指定master机器。
复制过程
Redis复制主要由SYNC命令实现,复制过程如下图:

Redis复制过程
上图为Redis复制工作过程:
- slave向master发送sync命令。
- master开启子进程来讲dataset写入rdb文件,同时将子进程完成之前接收到的写命令缓存起来。
- 子进程写完,父进程得知,开始将RDB文件发送给slave。
- master发送完RDB文件,将缓存的命令也发给slave。
- master增量的把写命令发给slave。
值得注意的是,当slave跟master的连接断开时,slave可以自动的重新连接master,在redis2.8版本之前,每当slave进程挂掉重新连接master的时候都会开始新的一轮全量复制。如果master同时接收到多个slave的同步请求,则master只需要备份一次RDB文件。
增量复制
上面复制过程介绍的最后提到,slave和master断开了、当slave和master重新连接上之后需要全量复制,这个策略是很不友好的,从Redis2.8开始,Redis提供了增量复制的机制:
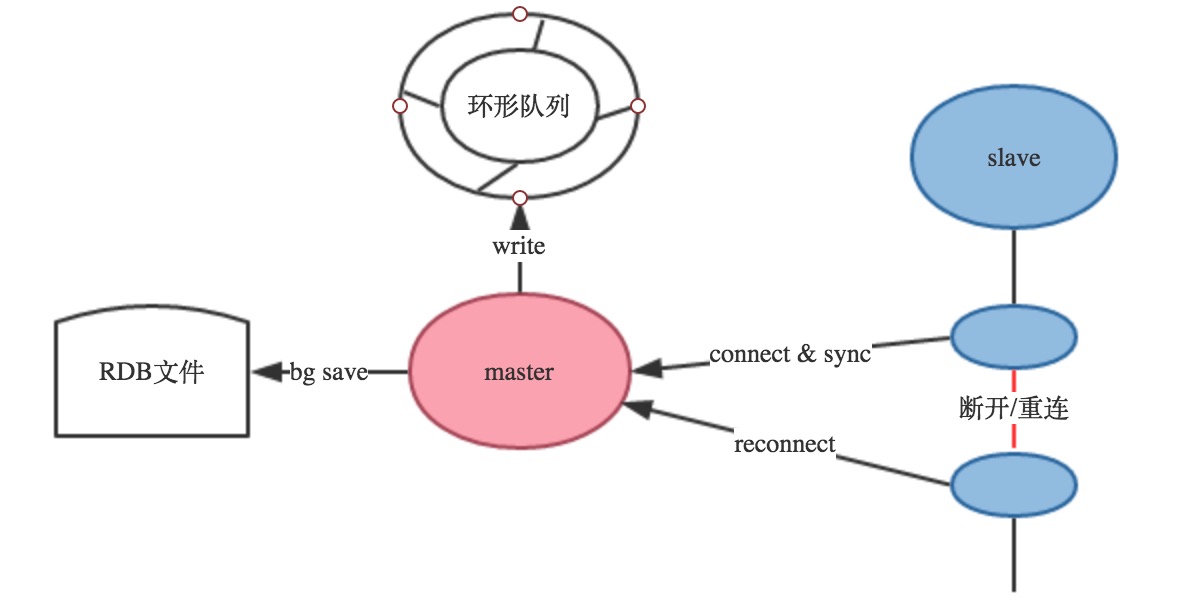
增量复制机制
master除了备份RDB文件之外还会维护者一个环形队列,以及环形队列的写索引和slave同步的全局offset,环形队列用于存储最新的操作数据,当slave和maste断开重连之后,会把slave维护的offset,也就是上一次同步到哪里的这个值告诉master,同时会告诉master上次和当前slave连接的master的runid,满足下面两个条件,Redis不会全量复制:
- slave传递的run id和master的run id一致。
- master在环形队列上可以找到对应offset的值。
满足上面两个条件,Redis就不会全量复制,这样的好处是大大的提高的性能,不做无效的功。
增量复制是由psync命令实现的,slave可以通过psync命令来让Redis进行增量复制,当然最终是否能够增量复制取决于环形队列的大小和slave的断线时间长短和重连的这个master是否是之前的master。
环形队列大小配置参数:
repl-backlog-size 1mb
Redis同时也提供了当没有slave需要同步的时候,多久可以释放环形队列:
repl-backlog-ttl 3600
免持久化复制
免持久化机制官方叫做Diskless Replication,前面基于RDB文件写磁盘的方式可以看出,Redis必须要先将RDB文件写入磁盘,才进行网络传输,那么为什么不能直接通过网络把RDB文件传送给slave呢?免持久化复制就是做这个事情的,而且在Redis2.8.18版本开始支持,当然目前还是实验阶段。
值得注意的是,一旦基于Diskless Replication的复制传送开始,新的slave请求需要等待这次传输完毕才能够得到服务。
是否开启Diskless Replication的开关配置为:
repo-diskless-sync no
为了让后续的slave能够尽量赶上本次复制,Redis提供了一个参数配置指定复制开始的时间延迟:
repl-diskless-sync-delay 5
slave只读模式
自从Redis2.6版本开始,支持对slave的只读模式的配置,默认对slave的配置也是只读。只读模式的slave将会拒绝客户端的写请求,从而避免因为从slave写入而导致的数据不一致问题。
半同步复制
和MySQL复制策略有点类似,Redis复制本身是异步的,但也提供了半同步的复制策略,半同步复制策略在Redis复制中的语义是这样的:
允许用户给出这样的配置:在maste接受写操作的时候,只有当一定时间间隔内,至少有N台slave在线,否则写入无效。上面功能的实现基于Redis下面特性:
- Redis slaves每秒钟会ping一次master,告诉master当前slave复制到哪里了。
- Redis master会记住每个slave复制到哪里了。
我们可以通过下面配置来指定时间间隔和N这个值:
min-slaves-to-write <number of slaves>
min-slaves-max-lag <number of seconds>
如果:
min-slaves-to-write 3
min-slaves-max-lag 10
那么在从服务器的数量少于3个,或者三个从服务器的延迟(lag)值都大于或等于10秒时,主服务器将拒绝执行写命令,这里的延迟值就是上面提到的INFO replication命令的lag值。
当配置了上面两个参数之后,一旦对于一个写操作没有满足上面的两个条件,则master会报错,并且将本次写操作视为无效。这有点像CAP理论中的“C”,即一致性实现,虽然半同步策略不能够完全保证master和slave的数据一致性,但是相对减少了不一致性的窗口期。
总结
本文在理解Redis复制概念和复制的优缺点的基础之上介绍了当前Redis复制工作原理以及主要特性,希望能够帮助大家。
原文链接:https://my.oschina.net/andylucc/blog/683631
Redis 复制原理及特性的更多相关文章
- 深入理解redis复制原理
原文:深入理解redis复制原理 1.复制过程 2.数据间的同步 3.全量复制 4.部分复制 5.心跳 6.异步复制 1.复制过程 从节点执行 slaveof 命令. 从节点只是保存了 slaveof ...
- Redis从出门到高可用--Redis复制原理与优化
Redis从出门到高可用–Redis复制原理与优化 单机有什么问题? 1.单机故障; 2.单机容量有瓶颈 3.单机有QPS瓶颈 主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/s ...
- redis复制原理和应用
1.前言 说到分布式高可用,必然少不了复制,一来是为了做个冗余备份防止数据丢失,二来还可以达到分流来提高性能的目的.基本架构: 下面用M表示Master(主服务器),S表示Slave(从服务器),话不 ...
- 搞懂Redis复制原理
前言 与大多数db一样,Redis也提供了复制机制,以满足故障恢复和负载均衡等需求.复制也是Redis高可用的基础,哨兵和集群都是建立在复制基础上实现高可用的.复制不仅提高了整个系统的容错能力,还可以 ...
- Redis复制原理
无论是在集群中还是主从结构中,redis新加入的节点和已有主(从)节点的消息同步都是通过sync命令的形式 下面来实践一下redis的同步机制, 新建主服务器于从服务器 主 从: 这是正常的主从结 ...
- Redis 复制原理及分析
1.测试 见master-slave测试帖 2 原理 第一次.Slave向Master同步的实现是: Slave向Master发出同步请求(发送sync命令),Master先dump出rdb文件,然后 ...
- Redis复制实现原理
摘要 我的前一篇文章<Redis 复制原理及特性>已经介绍了Redis复制相关特性,这篇文章主要在理解Redis复制相关源码的基础之上介绍Redis复制的实现原理. Redis复制实现原理 ...
- Redis 之深入江湖-复制原理
一.前言 上一篇文章Redis 之复制-初入江湖中,讲了关于Redis复制配置,如:如何建立配置.如何断开复制.关于链接的安全性等等,那么本篇文章将深入的去说一下关于Redis复制原理,如下: 复制过 ...
- redis系列--主从复制以及redis复制演进
一.前言 在之前的文章已经详细介绍了redis入门基础已经持久化相关内容包括redis4.0所提供的混合持久化. 通过持久化功能,Redis保证了即使在服务器宕机情况下数据的丢失非常少.但是如果这台服 ...
随机推荐
- Online Game Development in C++ 第五部分总结
I. 教程案例框架描述 该套教程做了一个简单的汽车控制系统,没有用到物理模拟.用油门和方向控制汽车的加速度和转向,同时还有一些空气阻力和滚动摩擦力的设置增加了真实感.汽车的位置是通过加速度和时间等计算 ...
- es的脑裂
一个正常es集群中只有一个主节点,主节点负责管理整个集群,集群的所有节点都会选择同一个节点作为主节点:所以无论访问那个节点都可以查看集群的状态信息. 而脑裂问题的出现就是因为从节点在选择主节点上出现分 ...
- Deepin 系统安装并配置PHP开发环境
Deepin是由武汉深之度科技有限公司开发的Linux发行版.Deepin团队基于Qt/C++(用于前端)和Go(用于后端)开发了的全新深度桌面环境(DDE),以及音乐播放器,视频播放器,软件中心等一 ...
- websocket 无需通过轮询服务器的方式以获得响应 同步在线用户数 上线下线 抓包 3-way-handshake web-linux-shell 开发
https://code.google.com/archive/p/phpwebsocket/source/default/source The WebSocket API (WebSockets) ...
- spring监听机制——观察者模式的应用
使用方法 spring监听模式需要三个组件: 1. 事件,需要继承ApplicationEvent,即观察者模式中的"主题",可以看做一个普通的bean类,用于保存在事件监听器的业 ...
- Linux_SquidProxyServer代理服务器
目录 目录 Squid proxy server Web proxy server operating principle Squid features Setup squid server Setu ...
- windows7 玩 WinKawaks kof2002为什么提示couldn't initialise DirectSound?
插上 耳机 或者 音响 就ok 呵呵 http://wenwen.sogou.com/z/q200172744.htm windows7 玩 WinKawaks kof2002为什么提示couldn ...
- 类InetAddress
如果一个类没有构造方法:A:成员全部是静态的(Math,Arrays,Collections)B:单例设计模式(Runtime)C:类中有静态方法返回该类的对象(InetAddress) public ...
- linux 软连接的使用
软连接是linux中一个常用命令,它的功能是为某一个文件在另外一个位置建立一个同不的链接. 具体用法是:ln -s 源文件 目标文件. 当 我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需 ...
- JavaScript文件中; !function (win, undefined) {}(window);的意义
+function (){}-function (){}!function (){}~function (){}(function (){})() 这种写法可以保证匿名函数立即运行且运行一次 传入的 ...