决策树剪枝算法-悲观剪枝算法(PEP)
前言
在机器学习经典算法中,决策树算法的重要性想必大家都是知道的。不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确了。由于完全决策树对训练样本的特征描述得“过于精确” ,无法实现对新样本的合理分析, 所以此时它不是一棵分析新数据的最佳决策树。解决这个问题的方法就是对决策树进行剪枝,剪去影响预测精度的分支。常见的剪枝策略有预剪枝(pre -pruning)技术和后剪枝(post -pruning )技术两种。预剪枝技术主要是通过建立某些规则限制决策树的充分生长, 后剪枝技术则是待决策树充分生长完毕后再进行剪枝。由于预剪枝技术运用较少,本系列将着重介绍后剪枝技术,本文将介绍的是悲观剪枝技术。
一、统计学相关知识复习
1、置信区间:
设θ'在大样本下服从E(θ') = θ, 标准误差为σ'的正态分布,那么θ的(1 - α)100%置信区间是:
θ' +/- (Zα/2) σ'
2、二项式概率分布:
均值和方差分别是u = np, σ2=npq ,其中p=每次实验成功的概率, q=1-p。
3、二项分布的正态逼近
如果np>=4 且nq>=4 ,二项概率分布p(y)逼近于正态分布。如下图

可以看到P(Y<=2)是在正态曲线下Y=2.5的左端面积。注意到Y=2的左端面积是不合适的,因为它省略了相应于Y=2的一半概率的长方形。为了修正,用连续概率分布去近似离散概率分布,在计算概率之前我们需要将2增加0.5。值0.5称为二项概率分布近似的连续性修正因子,因此
P(Y<=a) 约等于 P(Z< (a+0.5 - np/ ( npq)1/2) );
P(Y>=a) 约等于 P(Z> (a-0.5 - np/ ( npq)1/2) )
二、剪枝过程
对于后剪枝技术,在决策树形成后,最先要做的就是剪枝。后剪枝的剪枝过程是删除一些子树,然后用其叶子节点代替,这个叶子节点所标识的类别通过大多数原则(majority class criterion)确定。所谓大多数原则,是指剪枝过程中, 将一些子树删除而用叶节点代替,这个叶节点所标识的类别用这棵子树中大多数训练样本所属的类别来标识,所标识的类称为majority class ,(majority class 在很多英文文献中也多次出现)。
三、悲观剪枝--Pessimistic Error Pruning (PEP)
PEP后剪枝技术是由大师Quinlan提出的。它不需要像REP(错误率降低修剪)样,需要用部分样本作为测试数据,而是完全使用训练数据来生成决策树,又用这些训练数据来完成剪枝。决策树生成和剪枝都使用训练集, 所以会产生错分。现在我们先来介绍几个定义。
T1为决策树T的所有内部节点(非叶子节点),
T2为决策树T的所有叶子节点,
T3为T的所有节点,有T3=T1∪T2,
n(t)为t的所有样本数,
ni(t)为t中类别i的所有样本数,
e(t)为t中不属于节点t所标识类别的样本数
在剪枝时,我们使用
r(t)=e(t)/n(t)
就是当节点被剪枝后在训练集上的错误率,而
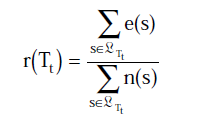 , 其中s为t节点的叶子节点。
, 其中s为t节点的叶子节点。
在此,我们把错误分布看成是二项式分布,由上面“二项分布的正态逼近”相关介绍知道,上面的式子是有偏差的,因此需要连续性修正因子来矫正数据,有
r‘(t)=[e(t) + 1/2]/n(t)
和
 , 其中s为t节点的叶子节点,你不认识的那个符号为 t的所有叶子节点的数目
, 其中s为t节点的叶子节点,你不认识的那个符号为 t的所有叶子节点的数目
为了简单,我们就只使用错误数目而不是错误率了,如下
e'(t) = [e(t) + 1/2]
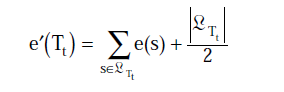
接着求e'(Tt)的标准差,由于误差近似看成是二项式分布,根据u = np, σ2=npq可以得到
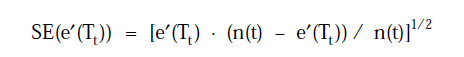
当节点t满足
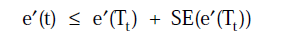
则Tt就会被裁减掉。
四、总结
在学习机器学习中,由于涉及的知识比较多,面又很广,所以大家一定要把数学,统计学,算法等相关知识学透彻,多总结归纳。而且这些知识一般比较晦涩难懂,但看别人的博客往往由于他人对知识点的理解有误,而导致对读者本人的误导,且博客是不具权威,不保证正确的,所以对机器学习这种严谨的学科更是需要多参考,多阅读特别是文献,甚至是算法原著者的论文。同时对我理解有误的地方,欢迎大家指出,再次表示感谢了。
五、推荐阅读
想了解其他剪枝算法(REP, MEP, EBP)的可以参考这篇文章http://52weis.com/articles.html?id=718_21
六、参考文献
A Comparative Analysis of Methods for Pruning Decision Trees 1997(ISSUE)
THE EFFECTS OF PRUNING METHODS ON THE PREDICTIVE ACCURACY OF INDUCED(ISSUE)
决策树后剪枝算法的研究 范 洁 杨岳湘(ISSUE)
决策树剪枝方法的比较 魏红宁 2005(ISSUE)
悲观剪枝算法在学生成绩决策树中的应用 李萍 2014(ISSUE)
所有文章均系原创,转载请注明作者和本文链接
决策树剪枝算法-悲观剪枝算法(PEP)的更多相关文章
- 就是要你明白机器学习系列--决策树算法之悲观剪枝算法(PEP)
前言 在机器学习经典算法中,决策树算法的重要性想必大家都是知道的.不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确 ...
- 决策树之PEP(悲观剪枝)
引用这2篇文章 https://blog.csdn.net/taoqick/article/details/72818496 https://www.open-open.com/lib/view/op ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 每周一道数据结构(四)A*算法&博弈树α-β剪枝
A*算法/博弈树 前阵子考试学了A*算法.博弈树和回溯,自己真是愚蠢至极,根本没就搞明白这些,所以对于这些算法问道的话就不能说清楚,也记不住,所以才有了这篇笔记.在这里感谢面试我的那位工程师~~ A* ...
- A*算法&博弈树α-β剪枝
A*算法&博弈树α-β剪枝 A*算法/博弈树 前阵子考试学了A*算法.博弈树和回溯,自己真是愚蠢至极,根本没就搞明白这些,所以对于这些算法问道的话就不能说清楚,也记不住,所以才有了这篇笔记.在 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM --别人的,拷来看看
从决策树学习谈到贝叶斯分类算法.EM.HMM 引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
从决策树学习谈到贝叶斯分类算法.EM.HMM (Machine Learning & Recommend Search交流新群:172114338) 引言 log ...
- 机器学习总结(八)决策树ID3,C4.5算法,CART算法
本文主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对比了各种算法的不同点. 决策树:是一种基本的分类和回归方法.在分类问题中,是基于特征对实例进行分类.既可以认为是if-then ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
随机推荐
- RocketMQ 消费者
本文分析 DefaultMQPushConsumer,异步发送消息,多线程消费的情形. DefaultMQPushConsumerImpl MQClientInstance 一个客户端进程只有一个 M ...
- NIO组件之buffer
Java NIO指的是new IO ,相对OIO,也称non-blocking IO,对应四种基本IO类型中的IO多路复用,主要有有三大核心组件,Channel(管道),Buffer(缓冲区),sel ...
- 系统分析与设计HW8
描述软件架构与框架之间的区别与联系 软件架构是有关软件整体结构与组件的抽象描述,用于指导大型软件系统各个方面的设计.架构模式(style)是特定领域常见问题的解决方案. 框架是特定语言和技术的架构应用 ...
- python locust 进行压力测试
最近公司项目周期比较赶, 项目是软硬结合,在缺少硬件的情况下,通过接口模拟设备上下架和购买情况,并进行压力测试, 本次主要使用三个接口 分别是3个场景: 生成商品IP, 对商品进行上架, 消费者购买商 ...
- finereport 带多参数查询
1.sql语句 ${,""," and dt.货主地区='"+comboBox0+"'")} ${,""," ...
- C盘无损扩容(傻逼拯救者128G固态分两个盘)
下载DiskGenius.exe 进行拆分分区(我从d盘拆分出20G给c盘) 然后右键此电脑,管理->磁盘管理 选中刚分出来的20G空间指向到c盘
- python+selenium元素定位之XPath学习02
XPath 语法 XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. XML 实例文档 我们将在下面的例子中使用这个 ...
- Java第一周总结
通过两周的Java学习最深刻的体会就是Java好像要比C要简单一些. 然后这两周我学习到了很多东西,李老师第一次上课就给我们介绍了Java的发展历程,同时还有Java工具jdk的发展历程. Java语 ...
- iScroll使用参考
分享是传播.学习知识最好的方法 以下这篇文章是iScroll.js官网的中文翻译,尽管自己英文不好,但觉得原作者们翻译的这个资料还是可以的,基本用法介绍清楚了.如果你英文比较好的话,可以看看官网的资料 ...
- [BZOJ 3930] [CQOI 2015]选数(莫比乌斯反演+杜教筛)
[BZOJ 3930] [CQOI 2015]选数(莫比乌斯反演+杜教筛) 题面 我们知道,从区间\([L,R]\)(L和R为整数)中选取N个整数,总共有\((R-L+1)^N\)种方案.求最大公约数 ...