Djano之ORM多表查询操作
# 把 model 转化为 迭代器去循环
MODEL.objects.all().iterator()
# 等同于 values, values_list, 但是 only 这种方式 获取字段属性依旧使用 Model.属性
MODEL.objects.only("FIELDS", "FIELDS", ...)
查询操作的两种模式:
关系表创建时的约束属性:
(1)一对一:models.OneToOneField()
(2)多对一:models.ForeignKey()
(3)多对多:models.ManyToManyField()
正向查询:
从设置了约束属性的表开始进行查询的就是正向查询;
正向查询用属性:
基于对象的一对一和多对一的查询结果只有一条,即为对象,可以直接用.进行取值;多对多的查询结果可能有多条,即为表控制器,取值与单表操作相同
基于双下划线的正向查询用属性__进行联表,结果为queryset类型,用values取值,双下划线可以用在任意函数内
反向查询:
从没有设置约束属性的表开始查询的就是反向查询。
反向查询类名(小写):
基于对象的一对一查询结果只有一条,即为对象,可以直接用.进行取值;多对一个多对多的查询结果可能有多条,用类名小写_set得到表控制器,取值与单表操作相同
基于双下划线的反向查询用类名小写__进行联表,结果为queryset类型,用values取值,双下划线可以用在任意函数内
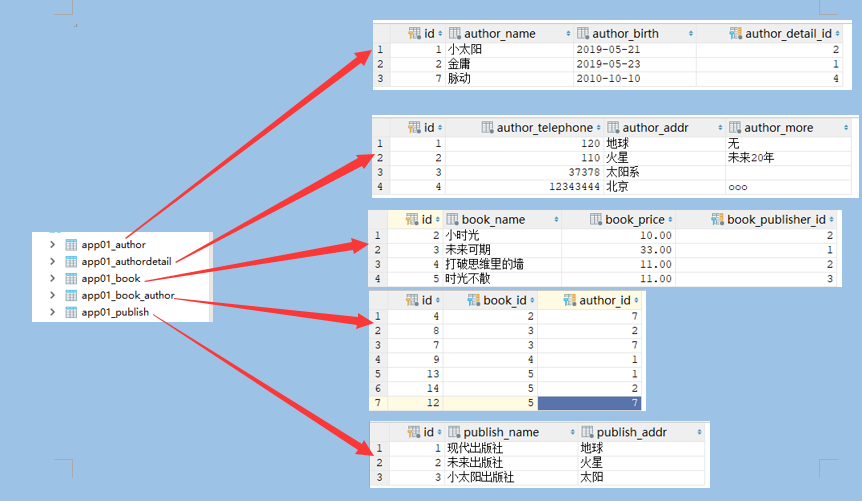
基于对象的跨表查询(sql子查询):
# 基于对象的多表查询:
正向查询用属性,结果为一条则是对象(一对一,多对一),结果可能多条类似控制器(多对多),可用单表操作方法取值
反向查询用类名小写,结果为一条的直接用类名小写则是对象(一对一),结果可能有多条的用类名小写_set(多对一,多对多)类似控制器,可用单表操作取值
#一对一
# 正向查询:作者小太阳的电话号
author_obj=models.Author.objects.filter(author_name='小太阳')[0]
ret=author_obj.author_detail.author_telephone
print(ret)#110
# 反向查询:电话为110的作者
authordetail_obj=models.AuthorDetail.objects.filter(author_telephone=110).first()
ret=authordetail_obj.author.author_name
print(ret)#小太阳
# 多对一
#正向查询:时光不散的图书的出版社名字
book_obj=models.Book.objects.get(book_name='时光不散')
ret=book_obj.book_publisher.publish_name
print(ret)#小太阳出版社
# 反向查询:未来出版社穿的图书名称
publish_obj=models.Publish.objects.filter(publish_name='未来出版社').first()
ret=publish_obj.book_set.all().values('book_name')
print(ret)#<QuerySet [{'book_name': '小时光'}, {'book_name': '打破思维里的墙'}]>
#多对多
#正向查询:时光不散的图书作者名字
book_obj = models.Book.objects.get(book_name='时光不散')
ret=book_obj.author.all().values('id','author_name')
print(ret)#<QuerySet [{'id': 1, 'author_name': '小太阳'}, {'id': 2, 'author_name': '金庸'}, {'id': 7, 'author_name': '脉动'}]>
#反向查询:小太阳写的书籍名称
author_obj=models.Author.objects.filter(author_name='小太阳').first()
ret=author_obj.book_set.all().values('book_name')
print(ret)#<QuerySet [{'book_name': '打破思维里的墙'}, {'book_name': '时光不散'}]>
基于双下划线的跨表查询(sql联表查询):
#基于双下划线的多表查询:
# 一对一
# 正向查询:作者小太阳的电话号
ret=models.Author.objects.filter(author_name='小太阳').values('author_detail__author_telephone')
print(ret)#<QuerySet [{'author_detail__author_telephone': 110}]>
#反向查询:作者小太阳的电话号
ret=models.AuthorDetail.objects.filter(author__author_name='小太阳').values('author_telephone')
print(ret)#<QuerySet [{'author_telephone': 110}]>
# 正向查询:电话为110的作者
ret=models.Author.objects.filter(author_detail__author_telephone=110).values('author_name')
print(ret)#<QuerySet [{'author_name': '小太阳'}]>
# 反向查询:电话为110的作者
ret=models.AuthorDetail.objects.filter(author_telephone=110).values('author__author_name')
print(ret)#<QuerySet [{'author__author_name': '小太阳'}]>
#多对一
# 正向查询:时光不散的图书的出版社名字
ret=models.Book.objects.filter(book_name='时光不散').values('book_publisher__publish_name')
print(ret)#<QuerySet [{'book_publisher__publish_name': '小太阳出版社'}]>
# 反向查询:时光不散的图书的出版社名字
ret=models.Publish.objects.filter(book__book_name='时光不散').values('publish_name')
print(ret)#<QuerySet [{'publish_name': '小太阳出版社'}]>
# 正向查询:未来出版社穿的图书名称
ret=models.Book.objects.filter(book_publisher__publish_name='未来出版社').values('book_name')
print(ret)#<QuerySet [{'book_name': '小时光'}, {'book_name': '打破思维里的墙'}]>
# 反向查询:未来出版社穿的图书名称
ret=models.Publish.objects.filter(publish_name='未来出版社').values('book__book_name')
print(ret)#<QuerySet [{'book__book_name': '小时光'}, {'book__book_name': '打破思维里的墙'}]>
#多对多
# 正向查询:时光不散的图书作者名字
ret=models.Book.objects.filter(book_name='时光不散').values('author__author_name')
print(ret)#<QuerySet [{'author__author_name': '小太阳'}, {'author__author_name': '金庸'}, {'author__author_name': '脉动'}]>
# 正向查询:时光不散的图书作者名字
ret=models.Author.objects.filter(book__book_name='时光不散').values('author_name')
print(ret)#<QuerySet [{'author_name': '小太阳'}, {'author_name': '金庸'}, {'author_name': '脉动'}]>
# 正向查询:小太阳写的书籍名称
ret=models.Book.objects.filter(author__author_name='小太阳').values('book_name')
print(ret)#<QuerySet [{'book_name': '打破思维里的墙'}, {'book_name': '时光不散'}]>
# 反向查询:小太阳写的书籍名称
ret=models.Author.objects.filter(author_name='小太阳').values('book__book_name')
print(ret)#<QuerySet [{'book__book_name': '打破思维里的墙'}, {'book__book_name': '时光不散'}]>
基于双下划线的跨多表查询(有几个表就有几种查询方式):
# 正向查询:小太阳出版社出版的图书和对应作者名字
ret=models.Book.objects.filter(book_publisher__publish_name='小太阳出版社').values('book_name','author__author_name')
print(ret)#<QuerySet [{'book_name': '时光不散', 'author__author_name': '小太阳'}, {'book_name': '时光不散', 'author__author_name': '金庸'}, {'book_name': '时光不散', 'author__author_name': '脉动'}]>
# 反向查询:小太阳出版社出版的图书和对应作者名字
ret=models.Publish.objects.filter(publish_name='小太阳出版社').values('book__book_name','book__author__author_name')
print(ret)#<QuerySet [{'book__book_name': '时光不散', 'book__author__author_name': '小太阳'}, {'book__book_name': '时光不散', 'book__author__author_name': '金庸'}, {'book__book_name': '时光不散', 'book__author__author_name': '脉动'}]>
ret=models.Author.objects.filter(book__book_publisher__publish_name='小太阳出版社').values('book__book_name','author_name')
print(ret)#<QuerySet [{'book__book_name': '时光不散', 'author_name': '小太阳'}, {'book__book_name': '时光不散', 'author_name': '金庸'}, {'book__book_name': '时光不散', 'author_name': '脉动'}]>
聚合查询、分组查询、F查询和Q查询
#聚合查询
# 聚合查询使用的聚合类(类似sql中聚合函数)必须先通过模块导入
# 聚合需要调用aggregate()函数
# 聚合类条件是查询语句结束的标志,一般那放在最后
# 聚合查询得到的结果是字典(聚合值必须取别名)
# aggregate可以被控制器直接调用,也可被queryset调用
from django.db.models import Avg,Max,Min,Sum,Count
# 查询所有图书的平均价格
ret=models.Book.objects.aggregate(a=Avg('book_price'))
print(ret)#{'a': 16.25}
# 查询所有图书的均价,最高价,最低价,总和以及总数
ret=models.Book.objects.all().aggregate(avg=Avg('book_price'),max=Max('book_price'),min=Min('book_price'),count=Count('id'))
print(ret)#{'avg': 16.25, 'max': Decimal('33.00'), 'min': Decimal('10.00'), 'count': 4}
# 分组查询
#分组查询类似sql中的group by分组
# 分组查询需要调用annotate()函数
#分组依据为annotate前使用的字段(可多个),参数一般使用聚合函数(别名可有可无)
# 分组前使用的结果性字段和分组参数统计结果共同返回为分组查询的字典queryset类型,可进一步进行相关操作
from django.db.models import Avg, Max, Min, Sum, Count
# 查询不同价格的图书个数
ret=models.Book.objects.values('book_price').annotate(n=Count('id'))
print(ret)#<QuerySet [{'book_price': Decimal('10.00'), 'n': 1}, {'book_price': Decimal('33.00'), 'n': 1}, {'book_price': Decimal('11.00'), 'n': 2}]>
# 查询不止一个作者的图书名
ret=models.Book.objects.annotate(n=Count('author__author_name')).filter(n__gt=2).values('book_name')
print(ret)#<QuerySet [{'book_name': '时光不散'}]>
# 查询不同出版社出版的图书的个数
ret=models.Publish.objects.values('publish_name').annotate(n=Count('book__id'))
print(ret)#<QuerySet [{'publish_name': '现代出版社', 'n': 1}, {'publish_name': '未来出版社', 'n': 2}, {'publish_name': '小太阳出版社', 'n': 1}]>
ret=models.Book.objects.values('book_publisher__publish_name').annotate(n=Count('id'))
print(ret)#<QuerySet [{'book_publisher__publish_name': '现代出版社', 'n': 1}, {'book_publisher__publish_name': '未来出版社', 'n': 2}, {'book_publisher__publish_name': '小太阳出版社', 'n': 1}]>
# F查询
#F查询使用F类必须从模块导入
#查询中需要同行记录两个字段的值进行比较
#F查询调用F类,传递相应的字段,即可获取同行记录的该字段值
from django.db.models import F
# 查询有图书id大于作者id的图书名称
ret=models.Book.objects.filter(id__gt=F('author__id')).values_list('book_name').distinct()
print(ret)#<QuerySet [('未来可期',), ('打破思维里的墙',), ('时光不散',)]>
#Q查询
# Q查询使用Q类必须从模块导入
# 查询中需要进行过滤条件的选择
# Q查询进行条件选择可以使用&、|、~(与或非)
# 每个条件都必须放在Q()中充当类参数
#Q查询中的|选择条件必须放在所有逗号隔开的单个并列条件之前
from django.db.models import Q
# 查询图书价格大于5且作者为小太阳的书籍名称
# ret=models.Book.objects.filter(author__author_name='小太阳',book_price__gt=11).values('book_name')
ret=models.Book.objects.filter(Q(book_price__gt=11)&Q(author__author_name='小太阳')).values('book_name')
print(ret)#<QuerySet [{'book_name': '打破思维里的墙'}, {'book_name': '时光不散'}]>
#查询作者为小太阳,且图书价格大于5或者图书id大于4的书籍名称
ret=models.Book.objects.filter(Q(author__author_name='小太阳')&Q(Q(book_price__gt=5)|Q(id__gt=4))).values('book_name')
# ret = models.Book.objects.filter(Q(book_price__gt=5) | Q(id__gt=4),author__author_name='小太阳').values('book_name')
print(ret)#<QuerySet [{'book_name': '打破思维里的墙'}, {'book_name': '时光不散'}]>
Djano之ORM多表查询操作的更多相关文章
- python 之 Django框架(orm单表查询、orm多表查询、聚合查询、分组查询、F查询、 Q查询、事务、Django ORM执行原生SQL)
12.329 orm单表查询 import os if __name__ == '__main__': # 指定当前py脚本需要加载的Django项目配置信息 os.environ.setdefaul ...
- ORM单表查询,跨表查询,分组查询
ORM单表查询,跨表查询,分组查询 单表查询之下划线 models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值models ...
- 在MyBatis中查询数据、涉及多参数的数据访问操作、插入数据时获取数据自增长的id、关联表查询操作、动态SQL、关于配置MyBatis映射没有代码提示的解决方案
1. 单元测试 在单元测试中,每个测试方法都需要执行相同的前置代码和后置代码,则可以自定义2个方法,分别在这2个方法中执行前置代码和后置代码,并为这2个方法添加@Before和@After注解,然后, ...
- MySQL/MariaDB数据库的多表查询操作
MySQL/MariaDB数据库的多表查询操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.单表查询小试牛刀 [root@node105.yinzhengjie.org.cn ...
- 第十七篇 ORM跨表查询和分组查询---二次剖析
ORM跨表查询和分组查询---二次剖析 阅读目录(Content) 创建表(建立模型) 基于对象的跨表查询 一对多查询(Publish与Book) 多对多查询 (Author 与 Book) 一对一查 ...
- Django ORM多表查询练习
ORM多表查询 创建表结构: from django.db import models # 创建表结构 # Create your models here. class Class_grade(mod ...
- 57 ORM多表查询
多表查询from django.db import models# Create your models here. class Author(models.Model): nid = models. ...
- 55-56 ORM多表查询
多表查询: KEY ====> 通过ORM引擎如何跨表: 正向查询按字段,反向查询按表名小写 模型的创建: from django.db import models # Create yo ...
- ORM多表查询下
一.多表查询 1.基于双下划线的跨表查询 Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系.要做跨关系查询,就使用两个下划线来链接 ...
随机推荐
- Libra教程之:Libra协议的关键概念
文章目录 Libra协议 交易和状态 交易详解 账本状态详解 版本数据库 账户 账户地址 Proof 验证节点 存储 Libra协议 Libra协议是Libra区块链的基础,本文主要讲解Libra协议 ...
- asp.net下载大文件代码
public void Down(string filepath, HttpResponse aResponse) { System.IO.Stream iStream = null; // Buff ...
- [转]Git详解之四 服务器上的Git
服务器上的 Git 到目前为止,你应该已经学会了使用 Git 来完成日常工作.然而,如果想与他人合作,还需要一个远程的 Git 仓库.尽管技术上可以从个人的仓库里推送和拉取修改内容,但我们不鼓励这样做 ...
- Eclipse Mac OS 安装 最新版 Subversion插件subclipse
subclipse 目前全部转移到github 官方地址 https://github.com/subclipse/subclipse/wiki Eclipse mac版 安装 最新版svn插件sub ...
- MySQL数据库的套接字文件和pid文件
MySQL数据库的套接字文件和pid文件 socket文件:当用Unix域套接字方式进行连接时需要的文件. pid文件:MySQL实例的进程ID文件. MySQL表结构文件:用来存放MySQL表结构定 ...
- 简要理解CommonJS规范
写在前面: 一个文件就是一个模块. 另外本文中的示例代码需要在node.js环境中方可正常运行,否则将出现错误.事实上ES6已经出现了模块规范,如果使用ES6的模块规范是无需node.js环境的.因此 ...
- MYSQl 全表扫描以及查询性能
MYSQl 全表扫描以及查询性能 -- 本文章仅用于学习,记录 一. Mysql在一些情况下全表检索比索引查询更快: 1.表格数据很少,使用全表检索会比使用索引检索更快.一般当表格总数据小于10行并且 ...
- CompressIt
结构 压缩软件的核心在于压缩算法.基于Huffman编码的压缩算法思路: 以二进制方式读取源文件,按照每8bits作为一个字符: 统计每个字符的出现频率即为叶子结点的权值,按照Huffman算法得到每 ...
- Codeforce-Ozon Tech Challenge 2020-B. Kuroni and Simple Strings(贪心)
B. Kuroni and Simple Strings time limit per test1 second memory limit per test256 megabytes inputsta ...
- 《C程序设计语言》 练习1-21
问题描述 编写程序entab,将空格串替换为最少数量的制表符和空格,但要保持单词之间的间隔不变.假设制表符终止位的位置与练习1 - 20的detab程序的情况相同.当使用一个制表符或者一个空格都可以到 ...