浅谈MySQL数据库
什么是数据库
定义
数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。当今世界是一个充满着数据的互联网世界,充斥着大量的数据。即这个互联网世界就是数据世界。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发送的消息等等。除了文本类型的数据,图像、音乐、声音都是数据。数据一般存储在内存、硬盘。
发展现状
在数据库的发展历史上,数据库先后经历了层次数据库、网状数据库和关系数据库等各个阶段的发展,数据库技术在各个方面的快速的发展。特别是关系型数据库已经成为目前数据库产品中最重要的一员,80年代以来, 几乎所有的数据库厂商新出的数据库产品都支持关系型数据库,即使一些非关系数据库产品也几乎都有支持关系数据库的接口。这主要是传统的关系型数据库可以比较好的解决管理和存储关系型数据的问题。随着云计算的发展和大数据时代的到来,关系型数据库越来越无法满足需要,这主要是由于越来越多的半关系型和非关系型数据需要用数据库进行存储管理,以此同时,分布式技术等新技术的出现也对数据库的技术提出了新的要求,于是越来越多的非关系型数据库就开始出现,这类数据库与传统的关系型数据库在设计和数据结构有了很大的不同, 它们更强调数据库数据的高并发读写和存储大数据,这类数据库一般被称为NoSQL(Not only SQL)数据库。 而传统的关系型数据库在一些传统领域依然保持了强大的生命力。
数据库基本概念
库:多表构建一个数据库(存放多张表),本质是一个文件夹
表:多条数据构建一张表(包含多条相同结构的记录),本质就是文件
记录:存放一条条数据(包含多个key-value键值对的一条数据),本质就是文件中一条条数据记录(二进制数据)
数据库分类
关系数据库
关系型数据库,存储的格式可以直观地反映实体间的关系。关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的。 常见的关系型数据库有Mysql,SqlServer等。在轻量或者小型的应用中,使用不同的关系型数据库对系统的性能影响不大,但是在构建大型应用时,则需要根据应用的业务需求和性能需求,选择合适的关系型数据库。
关系型数据库对于结构化数据的处理更合适,如学生成绩、地址等,这样的数据一般情况下需要使用结构化的查询,例如join,这样的情况下,关系型数据库就会比NoSQL数据库性能更优,而且精确度更高。由于结构化数据的规模不算太大,数据规模的增长通常也是可预期的,所以针对结构化数据使用关系型数据库更好。关系型数据库十分注意数据操作的事务性、一致性,如果对这方面的要求关系型数据库无疑可以很好的满足。
总结:关系型数据库由表的概念,是以表中一条条记录存储数据,对于结构化数据的处理更合适。
非关系型数据库(NoSQL)
随着近些年技术方向的不断拓展,大量的NoSql数据库如MongoDB、Redis、Memcache出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计。
指的是分布式的、非关系型的、不保证遵循ACID原则的数据存储系统。NoSQL数据库技术与CAP理论、一致性哈希算法有密切关系。所谓CAP理论,简单来说就是一个分布式系统不可能满足可用性、一致性与分区容错性这三个要求,一次性满足两种要求是该系统的上限。而一致性哈希算则指的是NoSQL数据库在应用过程中,为满足工作需求而在通常情况下产生的一种数据算法,该算法能有效解决工作方面的诸多问题但也存在弊端,即工作完成质量会随着节点的变化而产生波动,当节点过多时,相关工作结果就无法那么准确。这一问题使整个系统的工作效率受到影响,导致整个数据库系统的数据乱码与出错率大大提高,甚至会出现数据节点的内容迁移,产生错误的代码信息。但尽管如此,NoSQL数据库技术还是具有非常明显的应用优势,如数据库结构相对简单,在大数据量下的读写性能好;能满足随时存储自定义数据格式需求,非常适用于大数据处理工作。
NoSQL数据库适合追求速度和可扩展性、业务多变的应用场景。 [5] 对于非结构化数据的处理更合适,如文章、评论,这些数据如全文搜索、机器学习通常只用于模糊处理,并不需要像结构化数据一样,进行精确查询,而且这类数据的数据规模往往是海量的,数据规模的增长往往也是不可能预期的,而NoSQL数据库的扩展能力几乎也是无限的,所以NoSQL数据库可以很好的满足这一类数据的存储。NoSQL数据库利用key-value可以大量的获取大量的非结构化数据,并且数据的获取效率很高,但用它查询结构化数据效果就比较差。
目前NoSQL数据库仍然没有一个统一的标准,它现在有四种大的分类:
(1)键值对存储(key-value):代表软件Redis,它的优点能够进行数据的快速查询,而缺点是需要存储数据之间的关系。 [3]
(2)列存储:代表软件Hbase,它的优点是对数据能快速查询,数据存储的扩展性强。而缺点是数据库的功能有局限性。 [3]
(3)文档数据库存储:代表软件MongoDB,它的优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好,同时缺少一种统一查询语言。 [3]
(4)图形数据库存储:代表软件InfoGrid,它的优点可以方便的利用图结构相关算法进行计算。而缺点是要想得到结果必须进行整个图的计算,而且遇到不适合的数据模型时,图形数据库很难使用。
总结:非关系数据库没有表的概念,是以key-value键值对方式存储数据
数据库启动与连接
启动服务端
在安装完成后先将文件夹下的bin的地址配置到path环境变量中
先进行搜索:服务,检索mysql服务
如果有停止服务,并移除服务(启动管理员终端输入mysqld --remove)
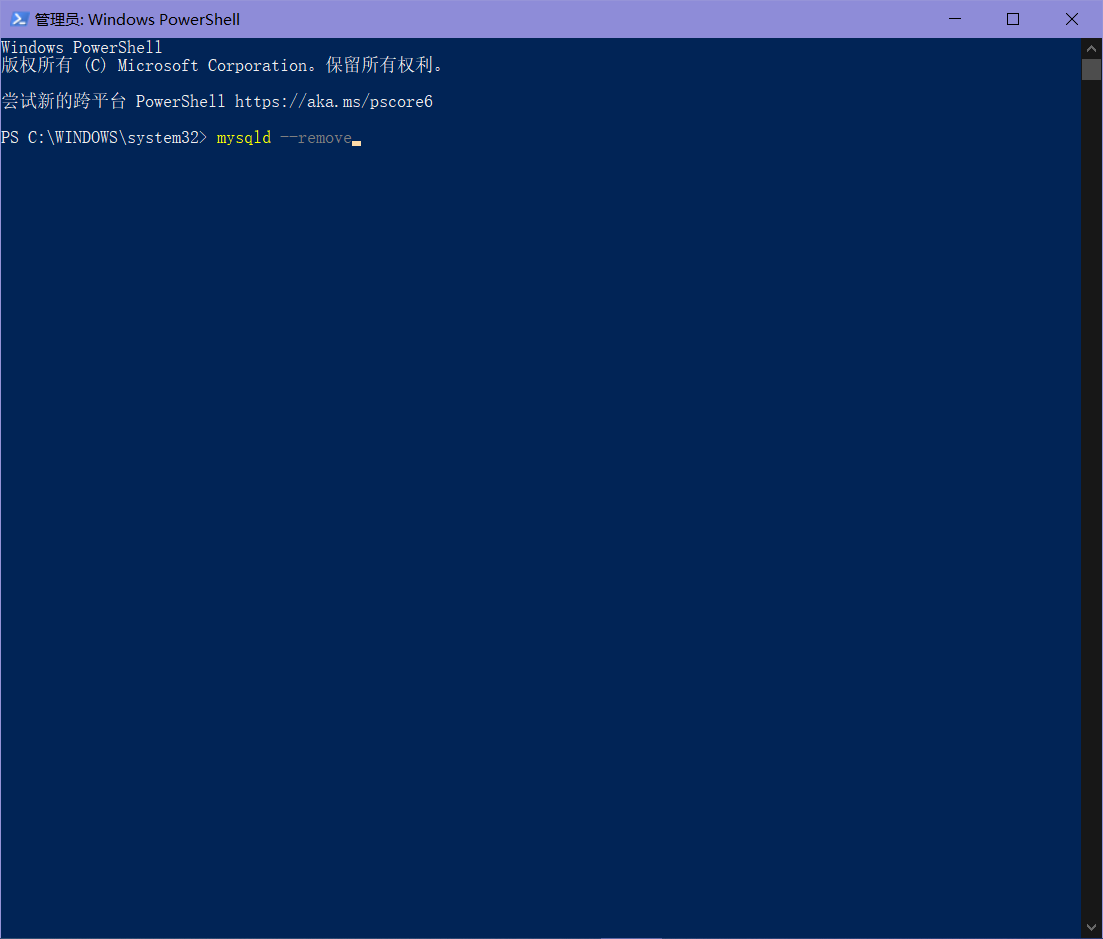
如果无,则在管理员终端输入mysqld install,再输入mysqld start
连接数据库
游客登录
>:mysql
账号密码登录
>:mysql -uroot -p
#回车后输入密码,如果没有密码就直接回车,也可先将密码写在-p后再回车(没设密码就直接回车)
连接指定服务器的MySQL
>:mysql -h ip地址 -p端口号 -u账号 -p密码
#举例:
>: mysql -hlocalhost -P3306 -uroot -p
退出数据库
>:quit
>:exit
用户信息查看
查看当前用户
>: select user();
没有登录的情况下,修改密码
>: mysqladmin -u用户名 -p旧密码 -h域名 password "新密码"
例>: mysqladmin -uroot -p12345678 -hlocalhost password "root"root权限下可以查看所有用户信息
>: select * from mysql.user;
>: select * from mysql.user \G
>: select user,password,host from mysql.user;
root登录下,删除游客(操作后要重启MySQL服务)
>: delete from mysql.user where user='';
root登录下,修改密码(操作后要重启MySQL服务)
>: update mysql.user set password=password('12345678') where host='localhost'; ```
root登录下,创建用户
>:grant 权限们 on 数据库名.表名 to 用户名@主机名 identified by '密码';
数据库的基本操作
查看已有数据库
>:show databases;
选择某个数据库
>:use 数据库名
查看当前所在数据库
>:select database();
创建数据库
>:create database 数据库名 [charset=编码格式];
查看数据库的详细内容
>:show create database 数据库名;
删除数据库
>: drop database 数据库名;
表的基本操作
前提:先选取要操作的数据库
查看已有表
>:show tables;
创建表
>:create table 表名(字段们);
查看创建表的sql
>:show create table 表名;
查看创建表的结构
>:desc 表名;
删除表
>: drop table 表名;
记录的基本操作
查看某个数据库中的某个表的所有记录(如果在对应数据库中,可以直接查看表)
>: select * from [数据库名.]表名;
给表的所有字段插入数据
>: insert [into] [数据库名.]表名 values (值1,...,值n);
根据条件修改指定内容
>: update [数据库名.]表名 set 字段1=新值1, 字段n=新值n where 字段=旧值;
根据条件删除记录
>: delete from [数据库名.]表名 where 条件;
浅谈MySQL数据库的更多相关文章
- (转)运维角度浅谈MySQL数据库优化
转自:http://lizhenliang.blog.51cto.com/7876557/1657465 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架 ...
- 运维角度浅谈MySQL数据库优化(转)
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善.这篇博文主要谈MySQL数据库发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分 ...
- 从运维角度浅谈 MySQL 数据库优化
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善.这篇博文主要谈MySQL数据库发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分 ...
- 运维角度浅谈MySQL数据库优化
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善.这篇博文主要谈MySQL数据库发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分 ...
- 浅谈MySQL 数据库性能优化
MySQL数据库是 IO 密集型的程序,和其他数据库一样,主要功能就是数据的持久化以及数据的管理工作.本文侧重通过优化MySQL 数据库缓存参数如查询缓存,表缓存,日志缓存,索引缓存,innodb缓存 ...
- 浅谈MySQL数据库面试必要掌握知识点
概述 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 MySQL官方地址 https://www.mysql.com/ MySQL 8系列最新版本为8.0.27,5系列的最 ...
- mysql分享一:运维角度浅谈MySQL数据库优化
转于:http://lizhenliang.blog.51cto.com/7876557/1657465 1.数据库表设计要合理避免慢查询.低效的查询语句.没有适当建立索引.数据库堵塞(死锁)等 2. ...
- 浅谈MySQL数据库基本操作
数据库配置 通过配置文件统一配置的目的:统一管理 服务端(mysqld) .客户端(client) 配置了 mysqld(服务端) 的编码为utf8,那么再创建的数据库,默认编码都采用utf8 配置流 ...
- 浅谈mysql主从复制的高可用解决方案
1.熟悉几个组件(部分摘自网络)1.1.drbd —— DRBD(Distributed Replicated Block Device),DRBD号称是 "网络 RAID" ...
随机推荐
- Java实现 LeetCode 283 移动零
283. 移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序. 示例: 输入: [0,1,0,3,12] 输出: [1,3,12,0,0] 说明: 必 ...
- Java实现 蓝桥杯VIP 算法提高 进制转换
算法提高 进制转换 时间限制:1.0s 内存限制:256.0MB 问题描述 程序提示用户输入三个字符,每个字符取值范围是0-9,A-F.然后程序会把这三个字符转化为相应的十六进制整数,并分别以十六进制 ...
- Java实现洛谷 P2802 回家
P2802 回家 时间限制 1.00s 内存限制 125.00MB 题目描述 小H在一个划分成了n*m个方格的长方形封锁线上. 每次他能向上下左右四个方向移动一格(当然小H不可以静止不动), 但不能离 ...
- Java实现子序列问题
一个串的子串是指该串的一个连续的局部.如果不要求连续,则可称为它的子序列. 比如对串: "abcdefg" 而言,"ab","abd",&q ...
- java实现坐标
* 已知平面上若干个点的坐标. 需要求出在所有的组合中,4 个点间平均距离的最小值(四舍五入,保留 2 位小数). 比如有 4 个点:a,b,c,d,则平均距离是指:ab, ac, ad, bc, b ...
- Java实现第九届蓝桥杯猴子分香蕉
猴子分香蕉 题目描述 5只猴子是好朋友,在海边的椰子树上睡着了.这期间,有商船把一大堆香蕉忘记在沙滩上离去. 第1只猴子醒来,把香蕉均分成5堆,还剩下1个,就吃掉并把自己的一份藏起来继续睡觉. 第2只 ...
- Pi-star MMDVM双工板介绍
Pi-star MMDVM双工板介绍(2020/2) pi-star里控制模式选择:双工模式(DUPLEX Mode)/单工模式(SIMPLE Mode) 双工板工作频率范围:144-148,219- ...
- leetcode之两数相加解题思路
问题描述 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,数组中同一个元素不能使 ...
- tensorflow2.0学习笔记第一章第五节
1.5简单神经网络实现过程全览
- 头条面试居然跟我扯了半小时的Semaphore
一个长头发.穿着清爽的小姐姐,拿着一个崭新的Mac笔记本向我走来,看着来势汹汹,我心想着肯定是技术大佬吧!但是我也是一个才华横溢的人,稳住我们能赢. 面试官:看你简历上有写熟悉并发编程,Semapho ...