一句话+两张图搞定JDK1.7HashMap,剩下凑字数
JDK1.7 HashMap一探究竟
HashMap很简单,原理一看散列表,实际数组+链表;Hash找索引.索引若为null,while下一个.Hash对对碰,链表依次查.加载因子.75,剩下无脑扩数组.
开局两张图,剩下全靠编
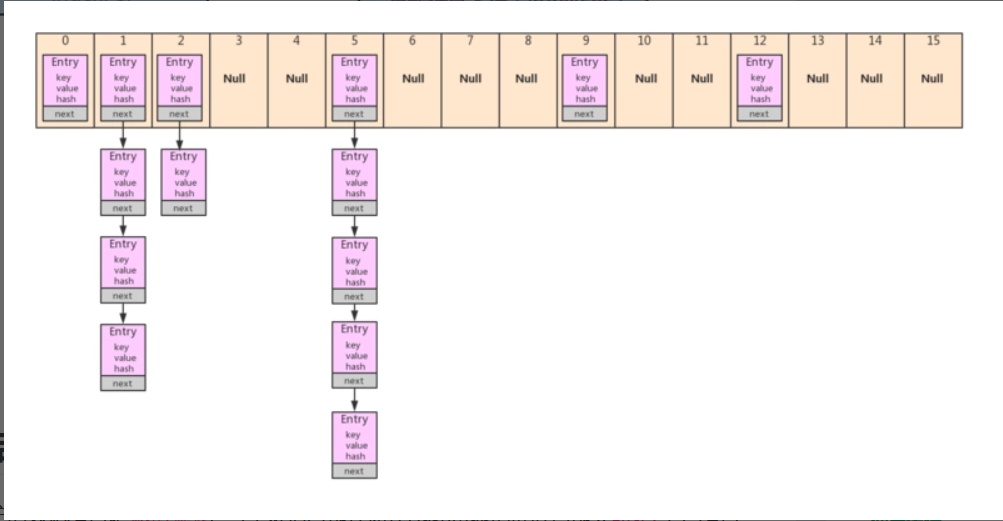
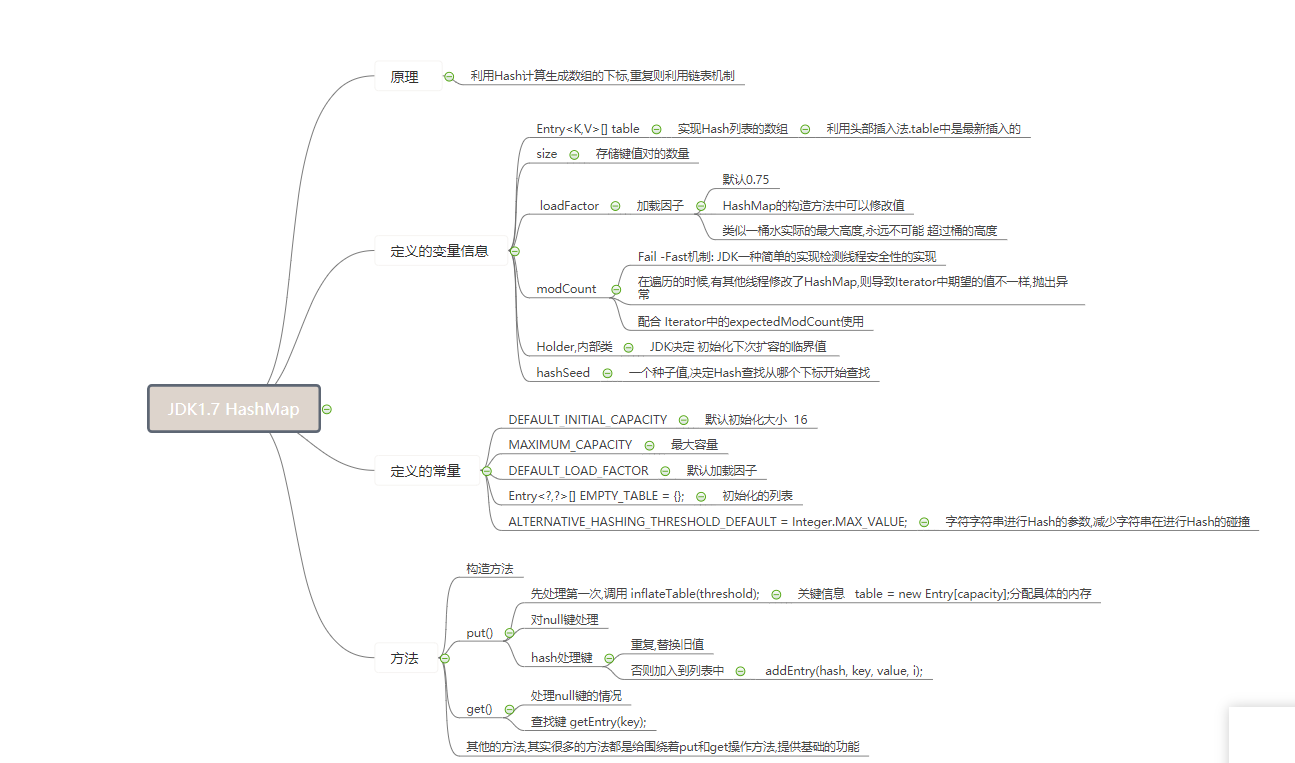
JDK1.7的HashMap
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
- AbstractMap<k,V> 对一些简单的功能的实现
- Map接口,定义了一组通用的Map操作的方法
- Cloneable接口,可以拷贝
- Serializable 可序列化
定义的常量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 默认初始化大小 10000B
static final int MAXIMUM_CAPACITY = 1 << 30; //最大的容量 2的20次方
static final float DEFAULT_LOAD_FACTOR = 0.75f; //影响因子 0.75 影响因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目 数超出了加载因子与当前容量的乘积时,通过调用 rehash 方法将容量翻倍。
static final Entry<?,?>[] EMPTY_TABLE = {};// 字面意思哈希表的入口数组.
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE; //表示在对字符串键(即key为String类型)的HashMap应用备选哈希函数时HashMap的条目数量的默认阈值。备选哈希函数的使用可以减少由于对字符串键进行弱哈希码计算时的碰撞概率。
定义的变量
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //不可序列化的哈希表,初始化为上面空的哈希表
transient int size; //哈希表中存储的数据
int threshold; // 下次扩容的临界值,size>=threshold就会扩容
final float loadFactor; //影响因子
transient int modCount; //修改的次数
private static class Holder {...} //它的作用是在虚拟机启动后根据jdk.map.althashing.threshold和ALTERNATIVE_HASHING_THRESHOLD_DEFAULT初始化ALTERNATIVE_HASHING_THRESHOLD
transient int hashSeed = 0; //seed 种子值
HashMap的构造方法
public HashMap(int initialCapacity, float loadFactor){
this.loadFactor = loadFactor;
threshold = initialCapacity; //threshold 下次扩容的临界值也设置为 initialCapacity
init(); //一个空方法的实现
}
public HashMap(int initialCapacity){
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(Map<? extends K, ? extends V> m) { //用Map初始化
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m); //通过forEach,将复制到新的HashMap中
}
Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY) //保证了map构成新的HashMap的时候容量,计算Factor后小于对应的默认因子.
真正存放键值的内部类
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next; //一个典型的链表的实现.单向链表
int hash;
// 构造函数
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
//... 一些比较普遍方法的实现
//Entry中的自己的Hash的实现
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
}
哈希的计算方法
final int hash(Object k) {
int h = hashSeed; //h为Hash的随机种子值
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
} //生成对应字符串的哈希值
h ^= k.hashCode(); //hashCode之后异或
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12); //最前面的12位和最后面的12位进行异或. 在与h异或,得到仍是一个32位的值
return h ^ (h >>> 7) ^ (h >>> 4);
}
计算存储下标(indexFor)
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1); //对hash进行与运算,得到对应的存储的下标
}
get方法的实现
public V get(Object key) {
if (key == null) //对应键为null的情况
return getForNullKey();
//普通的情况
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
对null键处理的函数
这是一个私有方法,方便其他函数的调用
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
获得键值对
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
put方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold); //inflateTable方法就是建立哈希表,分配表内存空间的操作(inflate翻译为“膨胀”的意思,后面会详述)。但是指定初始容量和负载因子的构造方法并没有马上调用inflateTable。
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//出现重复的值会覆盖
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
put中的子方法addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 容器当前存放的键值对数量是否达到了设定的扩容阈值,如果达到了就扩容2倍。扩容后重新计算哈希码,并根据新哈希码和新数组长度重新计算存储位置。做好潜质处理后,就调用createEntry新增一个Entry
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
transfer 方法 实现链表的扩容中的具体复制
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length; //扩容后的处理
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next; //链表成为了倒序
}
}
}
addEntry 中的createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; //入口
table[bucketIndex] = new Entry<>(hash, key, value, e); //让该节点替代入口地址,原来的链表连接在后面.就是所谓的头插法
size++;
}
对 threshold的处理
链表的容量扩充为2的幂次. 调整 threshold 方法
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); //实现了增长为2的幂运算. 实现也比较简单
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
HashMap的遍历
上面HashMap的基本操作已经完成了.下面就是一些对于Iterator接口的实现
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
}
Fail-Fast 机制
我们知道 java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。这一策略在源码中的实现是通过 modCount 域,modCount 顾名思义就是修改次数,对HashMap 内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map:注意到 modCount 声明为 volatile,保证线程之间修改的可见性。
构造方法
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
; //在Hash计算的时候会有部分的表为空,找到一个不为空的值
}
}
hasNext() 和 nextEntry()
public final boolean hasNext() {
return next != null; //第一次判断的是否不为空
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
; //同样利用循环找到写一个对应的链表节点
}
current = e;
return e;
}
关于多线程的问题
假设线程A和线程B对一个共享的HashMap同时put一个值. put后发现需要扩容,扩容后进行内存拷贝执行transfer方法.那么必定出现循环链表.以后get() 的时候出现死循环.
参考博客
理解HashMap 老哥写的比我好lt.com/a/1190000018520768) 老哥写的比我好
一句话+两张图搞定JDK1.7HashMap,剩下凑字数的更多相关文章
- 一张图搞定OAuth2.0 在Office应用中打开WPF窗体并且让子窗体显示在Office应用上 彻底关闭Excle进程的几个方法 (七)Net Core项目使用Controller之二
一张图搞定OAuth2.0 目录 1.引言 2.OAuth2.0是什么 3.OAuth2.0怎么写 回到顶部 1.引言 本篇文章是介绍OAuth2.0中最经典最常用的一种授权模式:授权码模式 非常 ...
- 两张图搞清楚Eclipse上的Web项目目录
从MyEclipse转到Eclipse起初有点不习惯eclipse的目录结构,顺手一查看到的文章帮助很大,转载一下: 原文链接:https://www.jianshu.com/p/91050dfcbe ...
- 一张图搞定OAuth2.0
1.引言 本篇文章是介绍OAuth2.0中最经典最常用的一种授权模式:授权码模式 非常简单的一件事情,网上一堆神乎其神的讲解,让我不得不写一篇文章来终结它们. 一项新的技术,无非就是了解它是什么,为什 ...
- 一张图搞定 .NET Framework, .NET Core 和 .NET Standard 的区别
最近开始研究.NET Core,有张图一看就能明白他们之前的关系. 上图己经能够说明.NET Framework和.NET Core其实是实现了 .NET Standard相关的东西,或者说Frame ...
- 个人电脑配置FTP服务器,四张图搞定。项目需要,并自己写了个客户端实现下载和上传的功能!
测试结果:
- 一张图搞定Java设计模式——工厂模式! 就问你要不要学!
小编今天分享的内容是Java设计模式之工厂模式. 收藏之前,务必点个赞,这对小编能否在头条继续给大家分享Java的知识很重要,谢谢!文末有投票,你想了解Java的哪一部分内容,请反馈给我. 获取学习资 ...
- 【移动开发】一张图搞定Activity和Fragment的生命周期
- 【Storm】一张图搞定Storm的运行架构
- 一张图搞懂Spring bean的完整生命周期
一张图搞懂Spring bean的生命周期,从Spring容器启动到容器销毁bean的全过程,包括下面一系列的流程,了解这些流程对我们想在其中任何一个环节怎么操作bean的生成及修饰是非常有帮助的. ...
随机推荐
- 二进制部署kubernetes集群_kube-apiserver提示"watch chan error: etcdserver: mvcc: required revision has been compacted'
查看kube-apiserver状态 [root@yxz-cluster01 ~]# systemctl status kube-apiserver -l ● kube-apiserver.servi ...
- 基于MySQL Binlog的Elasticsearch数据同步实践
一.为什么要做 随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品.订单等数据的多维度检索. 使用 Elasticsearch 存储业务数 ...
- TensorFlow-keras 100分类
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' from tensorflow.python.keras.datasets import cifa ...
- XSS语义分析的阶段性总结(二)
本文首发于“合天智汇”微信公众号,作者:Kale 前言 上次分享了javascript语义分析,并且简单介绍了新型xss扫描器的一些想法,如何在不进行大量fuzz的情况下又能准确的检测出xss漏洞,这 ...
- Java创建对象时的简单内存分析
简单创建对象的内存分析 主程序: 1 public class Application { 2 public static void main(String[] args) { 3 Animal do ...
- mysql面试(1)
一一个 SQL 执行行行的很慢,我们要分两种情况讨论:1.大大多数情况下很正常,偶尔很慢,则有如下原因(1).数据库在刷新脏⻚页,例例如 redo log 写满了了需要同步到磁盘.(2).执行行行的时 ...
- 【React踩坑记五】React项目中引入并使用react-ace代码编辑插件(自定义列表提示)
最近有一个引入sql编辑器插件的需求,要求代码高亮显示,代码智能提示,以及支持自定义代码提示列表等功能.中途在自定义代码提示列表中由于没有相关demo,所以踩了一些坑,遂将其整理如下,以便日后查看. ...
- WLAN 无线网络 03 - RF 基础
射频(Radio frequency),又称无线电频率.无线射频.高周波,常被用来当成无线电的同义词,为在3 kHz至300 GHz这个范围内的震荡频率,这个频率相当于无线电波的频率,以及携带着无线电 ...
- innobackupex 出现Unrecognized character \x01; marked by
centos 7.2 mysql 5.7.16 innobackupex version 2.4.6 [root@Devops-mysql-150-115 sh]# innobackupex --de ...
- 瑞银预计小扎的十年规划可获大回报 上调Facebook股票目标价
瑞银认为马克·扎克伯格(Mark Zuckerberg)为Facebook定制的十年规划将带来丰厚回报,它已将Facebook股票的目标价由之前的155美元上调至165美元. Facebook首席执行 ...