MapReduce基本认识
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
主要由Split、Map、Partition、Sort、Combine(需要自己写)、Merge、Reduce组成,一般来说Split、Partition、Sort、Merge不需要工程师编程但是可以改写,主要是写出Map和Reduce中对数据的操作。
概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
统计单词个数
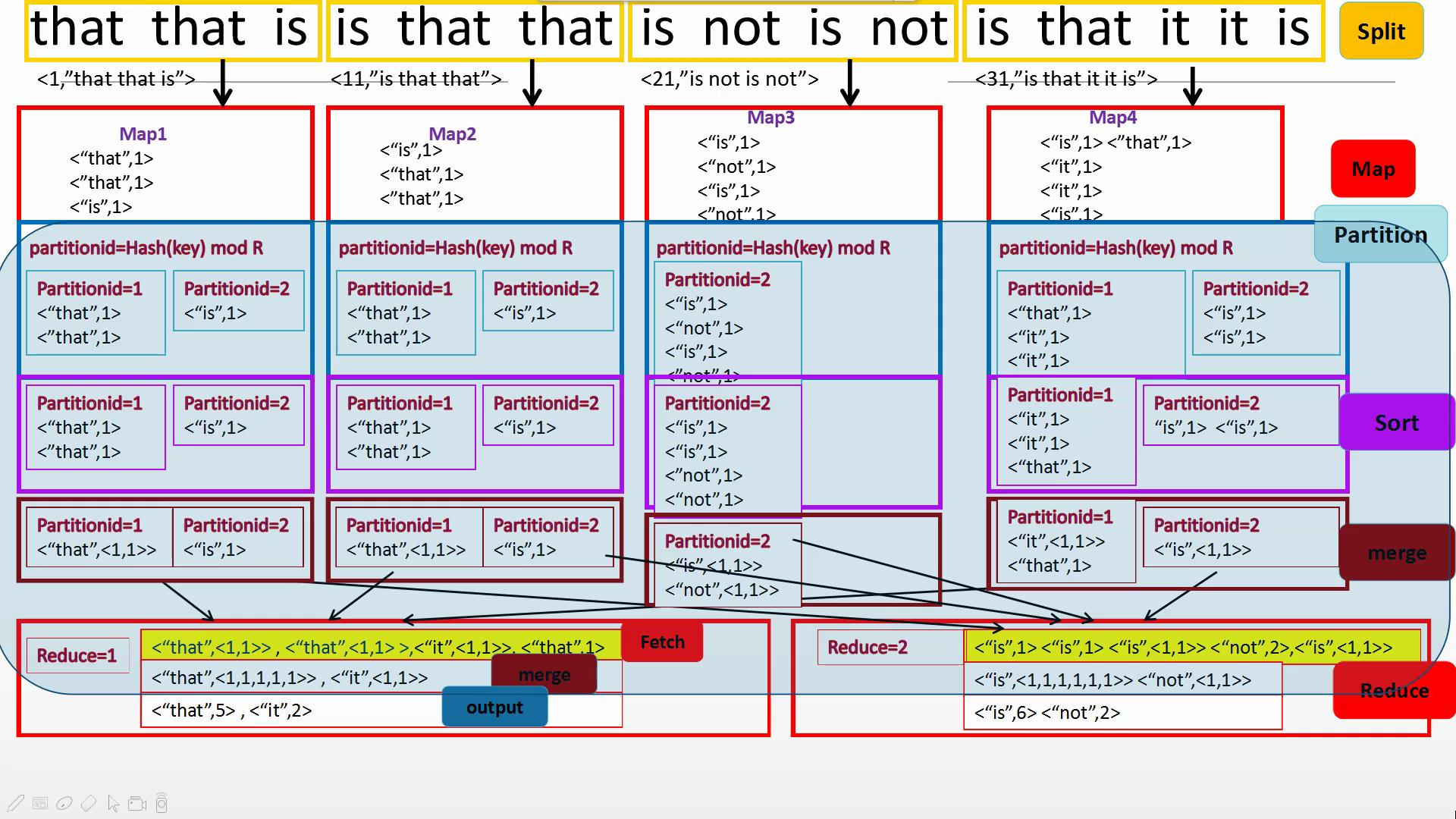
有Combine
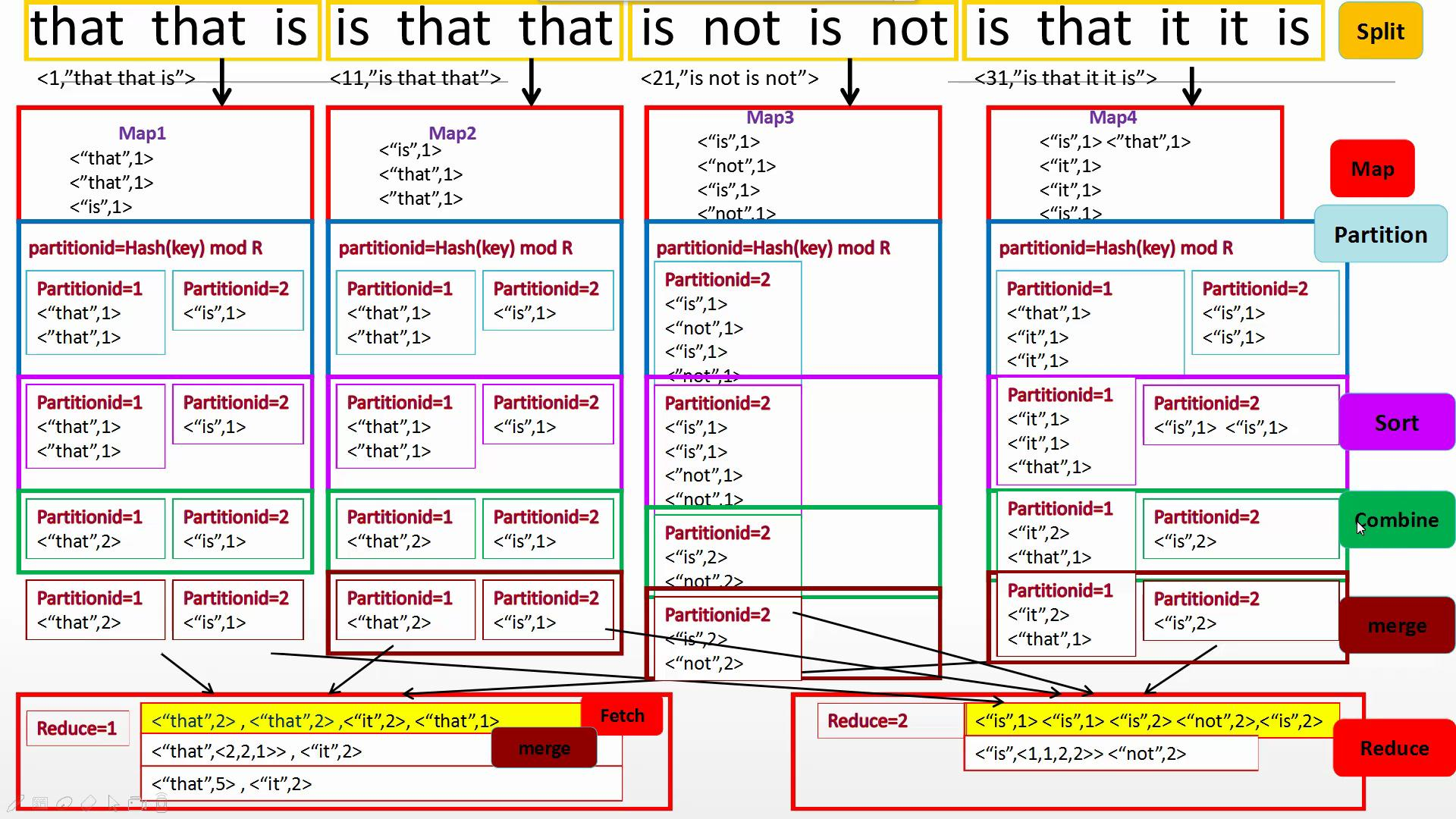
无Combine
代码:
WordCount.java
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { /**
* @param args
* @throws IOException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job=Job.getInstance(conf,"WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordMapper.class);
//job.setCombinerClass(WordCount)
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job,new Path("/input"));
FileOutputFormat.setOutputPath(job, new Path("/output")); System.exit(job.waitForCompletion(true)?0:1);
} public static class WordMapper extends Mapper<Object ,Text, Text, IntWritable>{
protected void map(Object key, Text value ,Mapper<Object ,Text, Text, IntWritable>.Context context) throws IOException, InterruptedException{
String[] words = value.toString().split(" ");
for (String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
} public static class WordReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
protected void reducer(Text key, Iterable<IntWritable> nums ,Reducer<Text, IntWritable,Text, IntWritable>.Context context) throws IOException, InterruptedException{
int sum=0;
for (IntWritable num:nums){
sum+=num.get();
}
context.write(key,new IntWritable(sum));
}
} }
MapReduce基本认识的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
随机推荐
- iOS 图片加载速度优化
FastImageCache 是 Path 团队开发的一个开源库,用于提升图片的加载和渲染速度,让基于图片的列表滑动起来更顺畅,来看看它是怎么做的. 一.优化点 iOS 从磁盘加载一张图片,使用 UI ...
- mybatis入门四 解决字段名与实体类属性名不相同的冲突
一.创建测试需要使用的表和数据 CREATE TABLE orders( order_id INT PRIMARY KEY AUTO_INCREMENT, order_no VARCHAR(20), ...
- 树莓派 Raspberry PI基础
树莓派 Raspberry PI基础 官网网址:https://www.raspberrypi.org 下载地址:https://www.raspberrypi.org/downloads/ 官方系统 ...
- 模块 sys shell参数获取
sys 参数获取 获取参数 sys模块是与python解释器交互的一个接口 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) ...
- java中的PO VO DAO BO POJO
一.PO:persistant object 持久对象,可以看成是与数据库中的表相映射的ava对象. 最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合PO中应该不包含任何对数据 ...
- Web 环境设置
修改最大打开文件数量 ulimit -n 100000 修改创建文件的最大值 #/etc/security/limits.conf * soft nofile 262140 * hard nofile ...
- Azure安装win2016的服务器,并下载安装mysql数据库心得
随便写写 第一部分:新建虚拟机创建win2016服务器 这部分内容跟着微软云提示操作即可, 基本步骤:创建一堆名字,选择一个地区的服务器,配置一些基本信息,然后azure就会自动创建虚拟机并安装你选择 ...
- LeetCode48, 如何让矩阵原地旋转90度
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode第29篇,我们来看一道简单的矩阵旋转问题. 题意 题目的要求很简单,给定一个二维方形矩阵,要求返回矩阵旋转90度之后的 ...
- linux被当矿机排查案例
1.发现服务器变的特别卡,正常服务运行很慢. 到服务器上查询一番发现top下发现 bashd的进程占用100%CPU了. find /-name bashd* //第一次查询文件占用目录kil ...
- python 判断一个字符串是否是小数
"""练习判断一个小数1.判断是否合法2.合法需要有一个小数点3.小数点左边必须是个整数,右边必须是个正整数 """ def xiaoshu ...