python之数据类型补充、集合、深浅copy
一、编码补充
代码块: 一个函数,一个模块,一个类,一个文件,交互模式下,每一行就是一个代码块。 id()查询对象的内存地址
== 比较的是两边的数值。
is 比较的是两边的内存地址。 小数据池:
前提:int,str,bool
1,节省内存。
2,提高性能和效率。
小数据池是什么?
在内存中,创建一个'池',提前存放了 -5 ~256 的整数,一定规则的字符串和bool值。
后续程序中,如果设置的变量指向的是小数据池的内容,那么就不会再内存中重新创建。 小数据池与代码块的关系。
同一个代码块:python在执行时,遇到了初始化对象命令,他会将这个变量名和数值放到一个字典中,
再次遇到他会从这字典中寻找。
不同代码块:python在执行时,直接从小数据池中寻找,满足条件id相同。 编码:
python3x:
英文:
str: 表现形式:s1 = 'hello'
内部编码方式: unicode bytes:表现形式:s1 = b'hello'
内部编码方式: 非unicode 中文:
str: 表现形式:s1 = '小白'
内部编码方式: unicode bytes:表现形式:s1 = b'\xe2\xe2\xe2\xe2\xe2\xe2'
内部编码方式: 非unicode
只有当你想要存储一些内容到文件中,或者通过网络传输时,才要用的bytes类型 str --->bytes: encode
bytes--->str: decode
补充:
s1 = '小黑'
b1 = s1.encode('gbk')
print(b1) # gbk的bytes类型 # gbk的bytes类型 -----> utf-8的bytes类型,正常情况是这样转换:
s2 = b1.decode('gbk') # 先按照对应的编码方式 解码成字符串(unicode)
b2 = s2.encode('utf-8') # 再编码成utf-8的bytes
print(b2)
非中文的字符串还可以这样解码:
s1 = 'xiaoming'
b1 = s1.encode('gbk') #gbk的bytes类型 s2 = b1.decode('utf-8') #可以按照utf-8的形式解码
print(s2) # 上面代码能成立:因为utf-8 gbk,unicode等编码的英文字母,数字,特殊字符都是映射的ASCII码。
二、基础数据类型补充
1、元组
如果元组中只有一个数据,且没有逗号,那么该"元组"的数据类型与里面的数据类型一致
否则,该数据类型就是元组
tu1 = (1)
print(tu1,type(tu1)) # 1 <class 'int'> tu1 = (1,)
print(tu1,type(tu1)) # (1,) <class 'tuple'> tu2 = ('hello')
print(tu2,type(tu2)) # hello <class 'str'> tu2 = ('hello',)
print(tu2,type(tu2)) # ('hello',) <class 'tuple'>
2、列表
列表与列表可以相加(就是拼接)
l1 = [1,2,3]
l2 = ['aa','bb']
l3 = l1 + l2
print(l3) --->[1, 2, 3, 'aa', 'bb']
li = [11, 22, 33, 44, 55, 66, 77, 88]
将列表中索引为奇数的元素,全部删除.
也许刚接触的时候会有人这么写:
li = [11, 22, 33, 44, 55, 66, 77, 88]
# 问题代码1:
for i in li:
if li.index(i) % 2 == 1:
li.remove(i)
print(li) # 问题代码2:
for i in range(len(li)):
if i % 2 == 1:
li.pop(i)
print(li)
但是你会发现这样做并不能实现结果,要么报错,要么实现不了预想的结果,为什么呢?
这是因为:在循环一个列表时,如果对列表中的某些元素进行删除,
那么此元素后面的所有元素就会向前进一位,他们的索引和长度就会发生变化。
所以正确的方法可以这样写:
li = [11, 22, 33, 44, 55, 66, 77, 88]
# 方法一:切片+步长删除
del li[1::2]
print(li) # 方法二:
l2 = []
for i in range(len(li)):
if i % 2 == 0:
l2.append(li[i])
li = l2
print(li) # 方法三:倒着删除
for index in range(len(li)-1, -1, -1):
if index % 2 == 1:
li.pop(index)
print(li)
总结:在循环一个列表时,最好不要对此列表进行改变大小(增删)的操作。
3、字典
1.创建字典的几种方式
dic1 = {'name': 'hello', 'age': 18} # {'name': 'hello', 'age': 18}
dic2 = dict({'home': 'huizhou'}) # {'home': 'huizhou'}
dic3 = dict([('higth', 183), ('long', 18)]) # {'higth': 183, 'long': 18}
dic4 = dict((('weight', 140), ('good', 'yes'))) # {'weight': 140, 'good': 'yes'}
# 迭代创建(第一个参数是可迭代对象,str list dict等)
dic5 = dict.fromkeys([1, 2, 3], 'hi') # {1: 'hi', 2: 'hi', 3: 'hi'}
2.fromkeys的陷阱
dict.fromkeys()方法迭代创建的字典,迭代的键都是指向同一个内存地址(值相同),即键不同,但值是同一个值
(1)
dic = dict.fromkeys([1, 2, 3], 'hello')
print(dic)
print(id(dic[1]))
print(id(dic[2]))
print(id(dic[3]))
结果:
{1: 'hello', 2: 'hello', 3: 'hello'}
1604999043984
1604999043984
1604999043984 (2)
dic = dict.fromkeys([1, 2, 3], [])
print(dic)
这样创建的是值为空列表的字典:
{1: [], 2: [], 3: []} dic[1].append('nihao')
print(dic)
print(id(dic[1]))
print(id(dic[2]))
print(id(dic[3]))
结果:
{1: ['nihao'], 2: ['nihao'], 3: ['nihao']}
2347486287880
2347486287880
2347486287880 dic[2].append('I am fine')
print(dic)
print(id(dic[1]))
print(id(dic[2]))
print(id(dic[3]))
结果:
{1: ['nihao', 'I am fine'], 2: ['nihao', 'I am fine'], 3: ['nihao', 'I am fine']} 2347486287880
2347486287880
2347486287880
3.循环字典的时候,不能删除字典的键值对
dic = {'key1': 'value1', 'key2': 'value2', 'k3': 'v3', 'name': 'aaa'}
# 将dic的键中含有k元素的所有键值对删除。
# 错误代码:
for key in dic:
if 'k' in key:
dic.pop(key)
print(dic)
# 这样写会报错dictionarychangedsizeduringiteration
# 这是因为在循环一个字典时,不能改变字典的大小,否则就会报错。
# 正确方法可以:
l1 = []
for key in dic:
if 'k' in key:
l1.append(key)
for key in l1: # 第二次循环的是含有'k'的所有键组成的一个列表,并在循环列表的时候删除字典里的键值对
dic.pop(key)
print(dic)
三、数据类型的转换
'''
int str bool 三者转换
str <---> bytes
str <---> list
dict.keys() dict.values() dict.items() list()
tuple <---> list
dict ---> list
''' # str ---> list: str.split()
s1 = 'aa bb cc'
l1 = s1.split()
print(l1) # ['aa', 'bb', 'cc'] # list ---> str: "xx".join(list) 此list中的元素全部是str类型才可以转换
l1 = ['aa', 'bb', 'cc']
s2 = ' '.join(l1)
print(s2) # aa bb cc # list ---> tuple
l1 = [1, 2, 3]
tu1 = tuple(l1)
print(tu1) # (1, 2, 3) # tuple ---> list
tu2 = (0, 2, 3)
l1 = list(tu2)
print(l1) # [0, 2, 3] # dict ---> list
dic1 = {'name': 'Xai', 'age': 1000}
l1 = list(dic1) # ['name', 'age']
l2 = list(dic1.keys()) # ['name', 'age']
l3 = list(dic1.values()) # ['Xai', 1000]
l4 = list(dic1.items()) # [('name', 'Xai'), ('age', 1000)]
四、集合set
1、集合介绍
set: {'aa', 'bb', 1, 2, 3}
集合要求里面的元素必须是不可变的数据类型,但是集合本身是可变的数据类型。
集合里面的元素不重复(天然去重),无序。
主要用途:
1,去重。
2,关系测试。
set1 = {'abc', [1,2], 1,2,3} # 这个是错误的,因为集合要求里面的元素必须是不可变的数据类型,因此这里会报错(列表是可变的数据类型)
set2 = {'aa', 'bb'} # 直接定义
set3 = set({'aa', 'bb'}) # set()方法
2、集合去重
list可以利用set的特性达到去重效果
l1 = [1, 1, 2, 3, 4, 4, 3, 2, 1, 5, 5]
set1 = set(l1) # 先把列表转换成集合,自动去重
l2 = list(set1) # 再把集合转换成列表
print(l2) # [1, 2, 3, 4, 5]
3、集合的增删
set1 = {'hello', 'handsome', 'boy', 'you', 'good'}
3.1 增
set1.add('女神') # add: 增加单个元素,类似列表的append
print(set1) # {'you', 'good', 'hello', 'boy', 'handsome', '女神'}
set1.update('abc') # update:迭代着增加(类似列表的extend)
print(set1) # {'you', 'good', 'hello', 'boy', 'handsome', '女神', 'c', 'b', 'a'}
3.2 删
set1.remove('hello') # 删除一个元素
print(set1) # {'you', 'good', 'boy', 'handsome', '女神', 'c', 'b', 'a'}
set1.pop() # 随机删除一个元素
print(set1) # {'good', 'boy', 'handsome', '女神', 'c', 'b', 'a'}
set1.clear() # 清空集合
print(set1) # set()
del set1 # 删除集合
4、关系测试
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
# 交集(& 或者 intersection):同时存在set1和set2中
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
# 并集(| 或者 union)
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8}
print(set1.union(set2))
# 反交集(^ 或者 symmetric_difference): 不同时存在set1和set2中
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2))
# 差集(- 或者 difference):set1-set2 代表在set1中,但不在set2中
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2))
print(set2 - set1) # {8, 6, 7}
# 子集
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 < set2) # True
print(set1.issubset(set2)) # True
# 超集
print(set2 > set1) # True
print(set2.issuperset(set1)) # True
# frozenset不可变集合,让集合变成不可变类型。
set1 = {1, 2, 3}
set2 = frozenset(set1)
print(set2) # 不可变的数据类型。 ***
五、赋值和深浅copy
1、赋值运算
l1 = [1, 2, 3]
l2 = l1
l1.append(666)
print(l2) # [1, 2, 3, 666]
print(id(l1)) #
print(id(l2)) # 34857448, 是同一个地址,l2 = l1只是把l2指向了l1的地址,l1改变,l2也改变
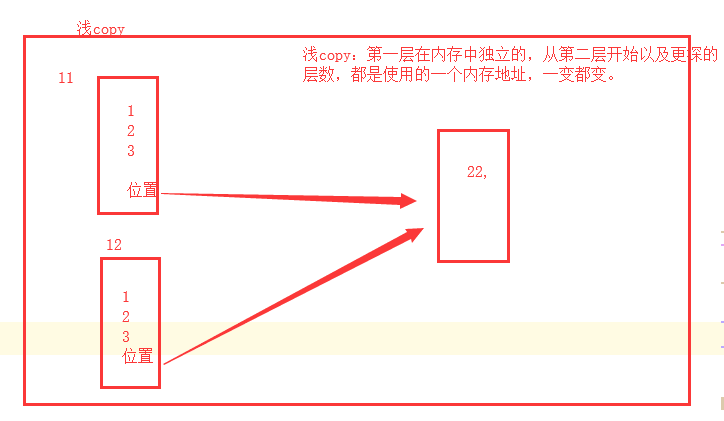
2、浅copy
浅copy(只针对列表,字典,集合):数据(列表)第二层开始可以与原数据进行公用
# 浅copy
l1 = [1, 2, 3]
l2 = l1.copy()
l1.append(666)
print(l1) # [1, 2, 3, 666]
print(l2) # [1, 2, 3],第一层是独立的 l1 = [1, 2, 3, [22, ]]
l2 = l1.copy()
l1[-1].append(666)
print(l1) # [1, 2, 3, [22, 666]]
print(l2) # [1, 2, 3, [22, 666]],第二层开始与原数据公用 print(id(l1)) #
print(id(l2)) #
print(id(l1[-1])) #
print(id(l2[-1])) # # 注意:切片属于浅copy
l1 = [1, 2, 3, [22, 33]]
l2 = l1[:]
l1[-1].append(666)
print(l2) # [1, 2, 3, [22, 33, 666]]
3、深copy
深copy(引用copy模块,任意数据类型都可深copy):完全独立的copy一份数据,与原数据没有关系
# 深copy
import copy l1 = [1, 2, 3, [22, ]]
l2 = copy.deepcopy(l1)
print(l1, l2) # [1, 2, 3, [22]] [1, 2, 3, [22]] l1[-1].append(666)
print(l1) # [1, 2, 3, [22, 666]]
print(l2) # [1, 2, 3, [22]]

python之数据类型补充、集合、深浅copy的更多相关文章
- 《Python》 基础数据类型补充和深浅copy
一.基础数据类型的补充 元组: 如果元组中只有一个数据,且没有逗号,则该‘元组’数据类型与里面的数据类型一致 列表: 列表之间可加不可减,可跟数字相乘 l1=['wang','rui'] l2=['c ...
- Python基础数据类型补充及深浅拷贝
本节主要内容:1. 基础数据类型补充2. set集合3. 深浅拷贝主要内容:一. 基础数据类型补充首先关于int和str在之前的学习中已经讲了80%以上了. 所以剩下的自己看一看就可以了.我们补充给一 ...
- Day7--Python--基础数据类型补充,集合,深浅拷贝
一.基础数据类型补充 1.join() 把列表中的每一项(必须是字符串)用字符串拼接 与split()相反 lst = ["汪峰", "吴君如", " ...
- 基本数据类型补充,深浅copy
#str s=' ' #只能是以至少一个空格组成的字符串(全空格) print(s.isspace()) #tuple 当元组只有一个元素组成,并没有",",则该元素是什么数据类型 ...
- python摸爬滚打之day07----基本数据类型补充, 集合, 深浅拷贝
1.补充 1.1 join()字符串拼接. strs = "阿妹哦你是我的丫个哩个啷" nw_strs = "_".join(strs) print(nw_s ...
- Python基础数据类型之集合
Python基础数据类型之集合 集合(set)是Python基本数据类型之一,它具有天生的去重能力,即集合中的元素不能重复.集合也是无序的,且集合中的元素必须是不可变类型. 一.如何创建一个集合 #1 ...
- python基本数据类型之集合
python基本数据类型之集合 集合是一种容器,用来存放不同元素. 集合有3大特点: 集合的元素必须是不可变类型(字符串.数字.元组): 集合中的元素不能重复: 集合是无序的. 在集合中直接存入lis ...
- python基础(9):基本数据类型四(set集合)、基础数据类型补充、深浅拷贝
1. 基础数据类型补充 li = ["李嘉诚", "麻花藤", "⻩海峰", "刘嘉玲"] s = "_&qu ...
- Python基础数据类型之集合以及其他和深浅copy
一.基础数据类型汇总补充 list 在循环一个列表时,最好不要删除列表中的元素,这样会使索引发生改变,从而报错(可以从后向前循环删除,这样不会改变未删元素的索引). 错误示范: lis = [,,, ...
随机推荐
- 控制台程序(C#)不弹出认证窗口连接到Dynamics CRM Online的Web API
摘要: 本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复271或者20180602可方便获取本文,同时可以在第一间得到我发布的最新的博文信息,follow me!我的网站是 www.luoyon ...
- 【图解】FlexGrid Explorer 全功能问世
前言 在去年的时候,我们推出了FlexGrid Demo,包含了FlexGrid的常用功能,如分组.滚动.冻结.自定义单元格类型.搜索面板.表格过滤器.树形结构.合并单元等,目前我们又在里面添加很多了 ...
- 仿9GAG制作过程(五)
有话要说: 在做完了数据展示功能之后,就想着完善整个APP.发现现在后台非常的混乱,有好多点都不具备,比方说:图片应该有略缩图和原图,段子.评论.点赞应该联动起来,段子应该有创建时间等. 于是就重新设 ...
- 从Linux上传到Git过程
1.1 实验内容 本次课程讲的是在实验楼的在线环境中,如何使用 Github 去管理在在线环境中使用的代码.配置.资源等实验相关文件,怎样去添加.同步和下拉在远程仓库中的实验文件,以此来维持自身的实验 ...
- Windows编译OpenCV4Android解决undefined reference to std错误
注意OpenCV 4.0.1 解决了这个问题请直接下载OpenCV 4.0.1 但是OpenCV 4.0.1作为模块导入Android Studio会有找不到R.styleable的问题 OpenCV ...
- Linux如何查找某个时间点后生成的空文件
今天遇到一个特殊需求,需要找到某天(例如2017-04-13)以及这之后生成的空文件.那么这个要怎么处理呢?这个当然是用find命令来解决.如下所示, -mtime -5 表示查找距现在 5*24H ...
- 使用VsCode自带的Emmet语法
新建html文件,保存之后,输入"!",按Tap(或Enter)键,自动生成HTML结构 标签只要直接输入标签名(不要输入<>),按Tap(或Enter)键自动生成完整 ...
- c/c++ linux 进程间通信系列2,使用UNIX_SOCKET
linux 进程间通信系列2,使用UNIX_SOCKET 1,使用stream,实现进程间通信 2,使用DGRAM,实现进程间通信 关键点:使用一个临时的文件,进行信息的互传. s_un.sun_fa ...
- Checkpoint 和Breakpoint
参考:http://www.cnblogs.com/qiangshu/p/5241699.htmlhttp://www.cnblogs.com/biwork/p/3366724.html 1. Che ...
- 苹果ios系统无法通过RD Client连接win10服务器远程错误0x00001307
问题描述: 1.RD Client无法远程Windows 10桌面,提示“错误 用户名或密码错误” 之前连接是没有问题的,但是更新了win10系统以后就出现问题了 [解决方法]: 最后找到了原因是因为 ...