学习笔记:spark Streaming的入门
spark Streaming的入门
1.概述
spark streaming 是spark core api的一个扩展,可实现实时数据的可扩展,高吞吐量,容错流处理。

从上图可以看出,数据可以有很多来源,如kafka,flume,Twitter,HDFS/S3,Kinesis用的比较少;这些采集回来的数据可以使用以高级的函数(map,reduce等)表达的复杂算法进行处理,经过sparkstreaming框架处理后的数据可以推送到文件系统,数据板或是实时仪表板上;除此之外,我们还可以在数据流上应用spark的机器学习算法和图像处理算法。
spark streaming简单的个人定义:将不同数据源的数据经过spark Streaming框架处理之后将结果输出到外部文件系统。
特点:
低延迟
能从错误中高效的恢复:fault-tolerant
能够运行在成百上千的节点上
能将批处理、机器学习、图计算等子框架和spark streaming综合起来使用
2.应用场景:
实时反映电子设备实时监测
交易过程中实时的金融欺诈
电商行业的推荐信息
3.集成spark生态系统的使用
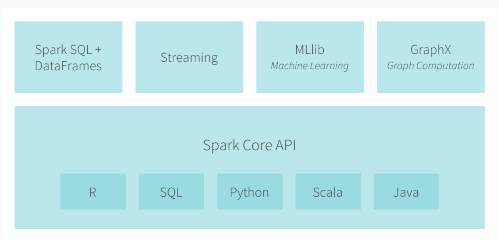
spark SQL、spark streaming、MLlib和GraphX都是基于spark core的扩展和开发,那它们是如何进行交互的?(后期补充)
4.spark的发展史

5.从词频统计功能着手Spark Streaming入门
- spark-submit执行(开发)
package org.apache.spark.examples.streaming import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
*
* Usage: NetworkWordCount <hostname> <port>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
*/
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < ) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit()
} StreamingExamples.setStreamingLogLevels() // Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds()) // Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(), args().toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, )).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
} 使用spark-submit方式提交的命令如下(不懂看代码前面的解析):
./spark-submit --master local[] --class org.apache.spark.examples.streaming.NetworkWordCount --name NetworkWordCount /home/hadoop/app/spark/eaxmple/jars/spark-example_2.-2.2..jar hadoop0000 - spark-shell执行(测试)
val ssc = new StreamingContext(sparkConf, Seconds())
val lines = ssc.socketTextStream("hadoop000", )
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, )).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()只需要运行./spark-shell --master loacal[2],之后直接把代码拷贝上去运行即可。
- spark-submit执行(开发)
6.工作原理
粗粒度:spark streaming接受实时数据流,把数据按照指定的时间段切成一片片小的数据块(spark streaming把每个小的数据块当成RDD来处理),然后把这些数据块传给Spark Engine处理,处理完之后的结果也是分批次的返回。

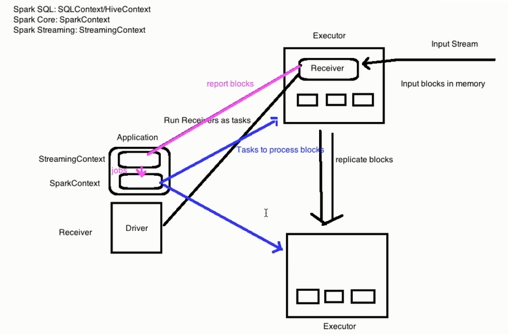
细粒度:application中有两个context,SparkContext和StreamingContext,使用receiver来接收数据。run receivers as taskes去executor上请求数据,当executor接收到数据后会将数据按时间段进行切分并存放在内存中,如设置了多副本将会拷贝到其他的Exceutor上进行数据的备份(replicate blocks), exceutor的receiver会将blocks的信息告诉StreamingContext, 每到指定的周期 StreamingContext 将会通知SparkContext启动jobs并把这些jobs分发到exceutor上执行。
学习笔记:spark Streaming的入门的更多相关文章
- Spark学习笔记——Spark Streaming
许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用, 还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它允许用户 ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- jQuery学习笔记 - 基础知识扫盲入门篇
jQuery学习笔记 - 基础知识扫盲入门篇 2013-06-16 18:42 by 全新时代, 11 阅读, 0 评论, 收藏, 编辑 1.为什么要使用jQuery? 提供了强大的功能函数解决浏览器 ...
- Oracle RAC学习笔记:基本概念及入门
Oracle RAC学习笔记:基本概念及入门 2010年04月19日 10:39 来源:书童的博客 作者:书童 编辑:晓熊 [技术开发 技术文章] oracle 10g real applica ...
- Linux内核学习笔记-1.简介和入门
原创文章,转载请注明:Linux内核学习笔记-1.简介和入门 By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- 【转载】【时序约束学习笔记1】Vivado入门与提高--第12讲 时序分析中的基本概念和术语
时序分析中的基本概念和术语 Basic concept and Terminology of Timing Analysis 原文标题及网址: [时序约束学习笔记1]Vivado入门与提高--第12讲 ...
- 卷积神经网络(CNN)学习笔记1:基础入门
卷积神经网络(CNN)学习笔记1:基础入门 Posted on 2016-03-01 | In Machine Learning | 9 Comments | 14935 Vie ...
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Java IO学习笔记八:Netty入门
作者:Grey 原文地址:Java IO学习笔记八:Netty入门 多路复用多线程方式还是有点麻烦,Netty帮我们做了封装,大大简化了编码的复杂度,接下来熟悉一下netty的基本使用. Netty+ ...
随机推荐
- python -- 小数据池 is和 == 再谈编码
1.小数据池 python程序是由代码块构成的,一个代码块的文本作为python程序的执行单元. 代码块:一个模块,一个函数,一个类,甚至一个command命令都是一个代码块,一个文件也是一个代码块, ...
- 搜索引擎中index、attribute和summary概念
index:倒排索引 attribute: 正排索引 summary:数据集合,用于数据结果展示.
- Tsinghua 2018 DSA PA3简要题解
CST2018 3-1-1 Sum (15%) 简单的线段树,单点修改,区间求和. 很简单. CST2018 3-1-2 Max (20%) 高级的线段树. 维护区间最大和,区间和,左边最大和,右边最 ...
- centos 日志文件
以下介绍的是20个位于/var/log/ 目录之下的日志文件.其中一些只有特定版本采用,如dpkg.log只能在基于Debian的系统中看到./var/log/messages — 包括整体系统信息, ...
- 数据库SQL优化大总结1之- 百万级数据库优化方案
转载自:https://blog.csdn.net/wuhuagu_wuhuaguo/article/details/72875054
- 导航菜单点击图片切换--jquery
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 浅谈利用同步机制解决Java中的线程安全问题
我们知道大多数程序都不会是单线程程序,单线程程序的功能非常有限,我们假设一下所有的程序都是单线程程序,那么会带来怎样的结果呢?假如淘宝是单线程程序,一直都只能一个一个用户去访问,你要在网上买东西还得等 ...
- runtime统计页面数据或者统计按钮的点击次数
一.按钮的点击统计 有的时候我们遇见这样的需求,让我们统计用户点击我们页面的动作的次数给与用户以统计,供以后给客户端推送不同的页面数据,这时候我们就会用到iOS的黑魔法(runtime). 首先我们不 ...
- websocket的属性readyState
webSocket的readyState属性用来定义连接状态,该属性的值有下面几种: 0 :对应常量CONNECTING (numeric value 0), 正在建立连接连接,还没有完成.The c ...
- Java语法基础学习DayTwentyOne(网络编程)
一.IP地址和端口号 1.作用 通过IP地址,唯一的定位互联网上一台主机. 端口号标识正在计算机上运行的进程,不同进程有不同的端口号,被规定为一个16位的整数0~65535,其中0~1023被预先定义 ...