在DataFrame数据表里面提取需要的行
在DataFrame数据表里面提取需要的行
代码功能:
在DataFrame表格中使用loc(),得到我们想要的行,然后根据某一列元素的值进行排序
此代码中还展示了为DataFrame添加列,即直接name_DataFrame['diff']=___即可,同时可以依据新添加的列元素的值,来对dataframe进行排序
import pandas as pd unames = ['user_id', 'gender', 'age','occupation','zip']
users = pd.read_table('users.dat', sep='::',header=None, names=unames) rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('ratings.dat', sep='::', header=None, names=rnames) mnames = ['movie_id', 'title', 'genres']
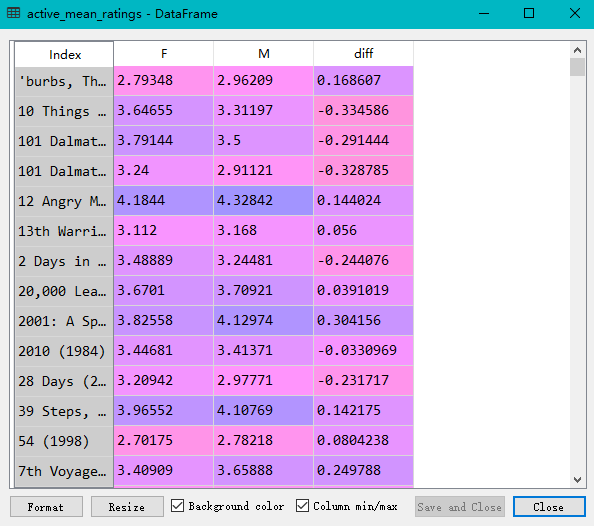
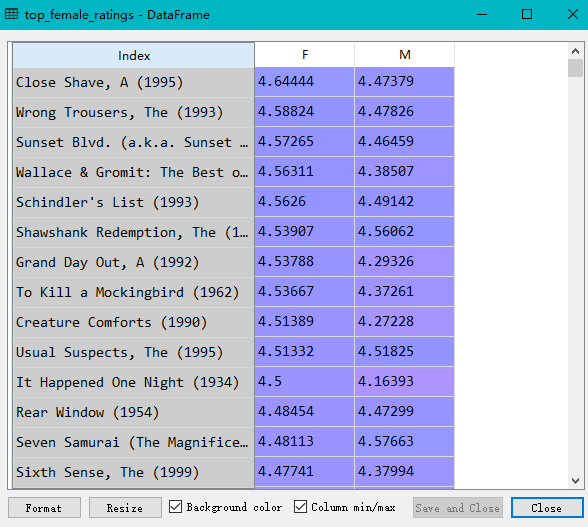
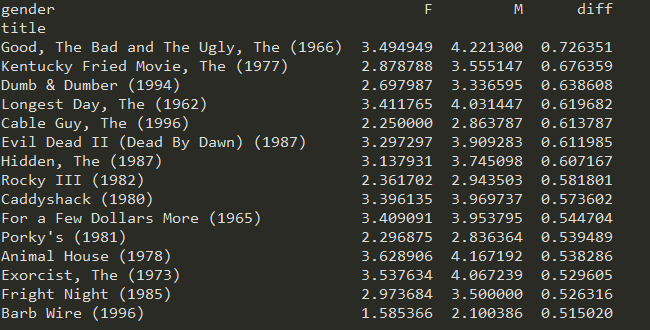
movies = pd.read_table('movies.dat', sep='::', header=None, names=mnames) data = pd.merge(pd.merge(ratings,users),movies) mean_ratings = pd.pivot_table(data,index=['title'],values='rating',columns='gender') print(mean_ratings[:10]) ratings_by_title = data.groupby('title').size() print(ratings_by_title[:10]) active_titles = ratings_by_title.index[ratings_by_title >= 250] print(active_titles) active_mean_ratings = mean_ratings.loc[active_titles] top_female_ratings = active_mean_ratings.sort_index(by='F', ascending=False) active_mean_ratings['diff'] = active_mean_ratings['M'] - active_mean_ratings['F'] sorted_by_diff = active_mean_ratings.sort_index(by='diff') print(sorted_by_diff[::-1][:15]) #注意对dataframe进行倒序访问的方法

在DataFrame数据表里面提取需要的行的更多相关文章
- spark dataframe操作集锦(提取前几行,合并,入库等)
https://blog.csdn.net/sparkexpert/article/details/51042970 spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当 ...
- 存储过程获取最后插入到数据表里面的ID
存储过程获取最后插入到数据表里面的ID SET NOCOUNT on;---不返回影响行数提高性能GOcreate proc [sp_bbs_thread_Insert] @id int output ...
- mysql的if用法解决同一张数据表里面两个字段是否相等统计数据量。
MySQL的使用用法如下所示:格式:if(Condition,A,B)意义:当Condition为true时,返回A:当Condition为false时,返回B.作用:作为条件语句使用.mysql的i ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Pandas DataFrame数据的增、删、改、查
Pandas DataFrame数据的增.删.改.查 https://blog.csdn.net/zhangchuang601/article/details/79583551 #删除列 df_2 = ...
- spark 将dataframe数据写入Hive分区表
从spark1.2 到spark1.3,spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API.Da ...
- Pandas DataFrame 数据选取和过滤
This would allow chaining operations like: pd.read_csv('imdb.txt') .sort(columns='year') .filter(lam ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(2)
上半部分内容链接 : https://www.cnblogs.com/lowmanisbusy/p/9069330.html 四.json和jsonpath的使用 JSON(JavaScript Ob ...
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
随机推荐
- tcp 与udp 的区别
1.TCP和UDP对比 TCP(Transmission Control Protocol)可靠的.面向连接的协议(eg:打电话).传输效率低全双工通信(发送缓存&接收缓存).面向字节流.使用 ...
- vue学习笔记——篇3
1.绑定计算后数据,三种方式: >1.红色框,通过method >2.黄色框,通过computed >3.蓝色框,通过watch 推荐computed,vue对computed做了缓 ...
- SPRINGMVC中的中文乱码处理
说到乱码处理,对于很多人来说是非常经常遇到的,现在来总结一下web工程中中文乱码处理的几个步骤,乱码处理大致可以分为一下几步,分别从页面到数据库: 页面传值到后台: 工程编码(最后一开始建立工程就设置 ...
- 个人洛谷账号地址——https://www.luogu.org/space/show?uid=181909 附上NOIP查分系统
个人洛谷地址: https://www.luogu.org/space/show?uid=181909 NOPI查分地址: http://bytew.net/OIer/
- nginx 配置本地https(免费证书)
Linux系统下生成证书 生成秘钥key,运行: $ openssl genrsa -des3 -out server.key 20481会有两次要求输入密码,输入同一个即可 输入密码 然后你就获得了 ...
- 剑指Offer 59. 按之字形顺序打印二叉树 (二叉树)
题目描述 请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推. 题目地址 https://www.nowco ...
- sourcetree 修改文件后提交上去,文件丢失
提交sourcetree 修改后,图片资源提交上去了,json文件没提交上去,原因是本地finder隐藏文件.gitignore_global中把一些文件类型都隐藏了不让提交. 具体使用default ...
- 3D数学基础(三)矩阵
3D引擎中对于矩阵的使用非常多,介绍这些知识也是为了告诉开发者原理,更有助于开发者编写逻辑. (1)固定流水线 各种坐标系之间的转化是通过矩阵相乘得到的,这里面就涉及到了3D固定流水线.作为3D游戏开 ...
- PC端的软件端口和adb 5037端口冲突解决方案
引用https://www.aliyun.com/jiaocheng/32552.html 阿里云 > 教程中心 > android教程 > PC端的软件端口和adb 50 ...
- leetcode 222.Count Complete Tree Nodes
完全二叉树是从左边开始一点点填充节点的,因此需要计算所有的节点的个数. 则分别从左边和右边来进行传递的,当左右是完全二叉树的时候,其节点个数就是pow(2,h)-1. /** * Definition ...