PageRank算法实现
基本原理
在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。这就是PageRank的核心思想。
引用来自《数学之美》的简单例子:
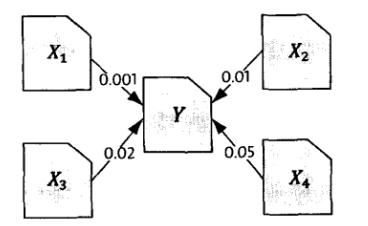
网页Y的排名应该来自于所有指向这个网页的其他网页的权重之和,在上图中Y的网页排名就是0.001 + 0.01 + 0.02 + 0.05 = 0.081。
如此,就可以把互联网简化成一个有向图,每个结点就代表一个网页,边就代表网页之间的链接关系。
接下来以具体的例子来介绍如何计算:
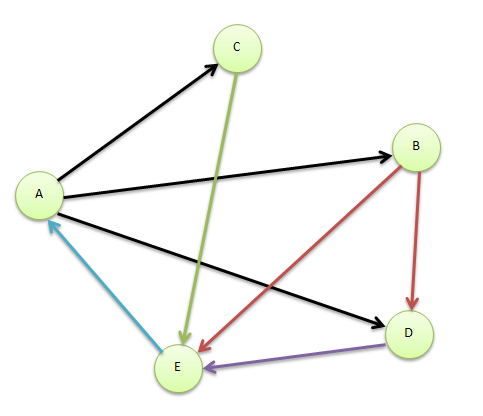
令 $PR = \left (PR_{1}\ ,\ PR_{2} \ ,\cdots ,PR_{N}\right )^{T}$为各个网页的排名,上图的网络用邻接矩阵来表示就是:
$S = \begin{pmatrix}
0 & 0& 0& 0& 1\\
1/3 & 0& 0& 0 &0 \\
1/3 & 0& 0& 0& 0\\
1/3 & 1/2& 0& 0 &0 \\
0& 1/2& 1& 1& 0
\end{pmatrix}$
注意,每一列的元素和为1。
需要额外注意的是,该算法要实现的前提之一是图必须是强连通的,所以如果网络中存在没有出链的结点,那么就需要处理一下。处理方法是让该结点对所有其他结点都有出链(包括它自身)。
PageRank算法是通过迭代来实现的,假定$PR_{i}$是第$i$次迭代的结果,那么
$PR_{i} = S\cdot PR_{i-1}$
当经过多次迭代后,最后得到一个稳定的PR值。
现在因为我们一开始不知道网页的初始排名,所以令$PR_{i} = \left (\frac{1}{N}\ ,\ \frac{1}{N} \ ,\cdots ,\frac{1}{N}\right )^{T}$。
上文说到图必须是强连通的,除了存在没有出链的结点,还存在只对自己出链的结点,若是访问了此结点,那就一直在该结点处循环。当然了,我们可不会一直很傻的在该网页停留,在现实中,我们也会通过输入一个新的地址来访问别的网页,这个网页是随机的,和当前网页可以没有关系。
为此引入一个新的变量$\alpha $,表示用户以$\alpha $的概率访问该网页所链接的网页,以$1-\alpha $的概率随机访问图中任意网页。
新的迭代公式就是:
$PR_{i} = \frac{1-\alpha }{N}\cdot e^{T}\cdot e + \alpha *S\cdot PR_{i-1} $
其中$e^{T}$为全1的列向量。
Python算法实现
接下来就用python来计算上面的网页排名,代码如下:
import numpy as np def page_rank(graph, alpha, eps, max_step):
node = graph.shape[0] # 网络中结点个数 pr = []
for i in range(node): # 初始访问概率
pr.append(1/node) pr = np.array(pr)
pr = pr.reshape(pr.shape[0], 1) y = [] # 跳转至任意网页的概率
x = (1.0-alpha)/node
for i in range(node):
y.append(x)
y = np.array(y)
y = y.reshape(y.shape[0], 1) for i in range(max_step):
pre_pr = pr
pr = np.dot(alpha * graph, pr) + y if abs(np.min(pr - pre_pr)) < eps:
print("The algorithm converges to the %dth iteration!" % i)
print(pr)
return print("failed!") if __name__ == '__main__':
graph = np.array([[0, 0, 0, 0, 1],
[1/3, 0, 0, 0, 0],
[1/3, 0, 0, 0, 0],
[1/3, 1/2, 0, 0, 0],
[0, 1/2, 1, 1, 0]])
page_rank(graph, 0.85, 1e-6, 100)
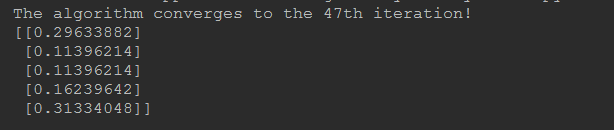
最后的运行结果:
MapReduce实现
这部分我也是用Python代码实现的,想看的可以转至我的另一篇随笔:传送文
参考:
[1] 【机器学习】【PageRank算法-1】PageRank算法原理介绍
[3] 吴军. 数学之美. PageRank——Google的民主表决式网页排名技术
PageRank算法实现的更多相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- PageRank算法简介及Map-Reduce实现
PageRank对网页排名的算法,曾是Google发家致富的法宝.以前虽然有实验过,但理解还是不透彻,这几天又看了一下,这里总结一下PageRank算法的基本原理. 一.什么是pagerank Pag ...
- PageRank算法
PageRank,网页排名,又称网页级别,传说中是PageRank算法拯救了谷歌,它是根据页面之间的超链接计算的技术,作为网页排名的要素之一.它通过网络浩瀚的超链接关系来确定一个页面的等级.Googl ...
- [转]PageRank算法
原文引自: 原文引自: http://blog.csdn.net/hguisu/article/details/7996185 感谢 1. PageRank算法概述 PageRank,即网页排名,又称 ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
- 关于pagerank算法的一点点总结
1. PageRank算法每个顶点收敛的值与每个点的初值是没有关系的,每个点随便赋初值. 2.像q=0.8这样的阻尼系数已经解决了PageRank中处在的孤立点问题.黑洞效应问题. 3.当有那个点进行 ...
- 浅析PageRank算法
很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看了一些相关的资料(PS:在动车上看看书真是一种享受),趁热打铁,将所看 ...
- PageRank算法第一篇
摘要by crazyhacking: 一 搜索引擎的核心问题就是3个:1.建立资料库,通过爬虫系统实现:2.建立一种数据结构,可以根据关键词找到含有这个词的页面.通过索引系统(倒排索引)实现.3排序系 ...
随机推荐
- C#文件增删改查
新建: private void btnnewfile_Click(object sender, EventArgs e) { //创建文件 string fileName = @"C:\T ...
- (转载)MyBatis传入多个参数的问题
原文地址:https://www.cnblogs.com/mingyue1818/p/3714162.html 一.单个参数: public List<XXBean> getXXBeanL ...
- window系统下搭建本地的NuGet Server
1. NuGet.Config文件所在的目录: C:\Users\xxx\AppData\Roaming\NuGet 2.将nupkg为结尾的文件放在 项目的Packages目录下.(注意是和web. ...
- windows----------windows10如何固定局域网ip
1. 2. 3. 4. 5.
- XML文件的读取
<?xml version="1.0" encoding="gbk"?> <!--设置编码格式为gbk--> <!DOCTYPE ...
- caffe中train过程的train数据集、val数据集、test时候的test数据集区别
val是validation的简称.training dataset 和 validation dataset都是在训练的时候起作用.而因为validation的数据集和training没有交集,所以 ...
- 运行main方法找不到类
http://blog.csdn.net/chenleixing/article/details/44816629
- Python笔记之数据类型
数据类型 计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值.但是,计算机能处理的远不止数值,还可以处理文本.图形.音频.视频.网页等各种各样的数据,不同的数据,需要定 ...
- h5页面实战——与andriod和ios的交互
首先需要我们h5页面需要做一些匹配.比如:如何判断当前手机是andriod还是ios, andriod攻城狮和ios工程师,一般会定义事件的方法.我们套用他们方法就可以了. 那么为什么我要写这个随笔呢 ...
- Caravel–一款开源OLAP+数据可视化分析前端工具,支持Druid和Kylin
参考此文:http://lxw1234.com/archives/2016/06/681.htm