学习笔记78—三大统计相关系数:Pearson、Spearman秩相关系数、kendall等级相关系数
******************************************************
如有谬误,请联系指正。转载请注明出处。
联系方式:
e-mail: heyi9069@gmail.com
QQ: 3309198330
******************************************************
统计相关系数简介
由于使用的统计相关系数比较频繁,所以这里就利用几篇文章简单介绍一下这些系数。
相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
Pearson(皮尔逊)相关系数
1、简介
皮尔逊相关也称为积差相关(或积矩相关)是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
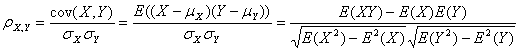
公式二:

公式三:
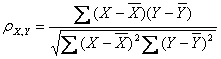
公式四:

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
2、适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
Matlab实现
3、皮尔逊相关系数的Matlab实现(依据公式四实现):
function coeff = myPearson(X , Y)
% 本函数实现了皮尔逊相关系数的计算操作
%
% 输入:
% X:输入的数值序列
% Y:输入的数值序列
%
% 输出:
% coeff:两个输入数值序列X,Y的相关系数
%
if length(X) ~= length(Y)
error('两个数值数列的维数不相等');
return;
end
fenzi = sum(X .* Y) - (sum(X) * sum(Y)) / length(X);
fenmu = sqrt((sum(X .^2) - sum(X)^2 / length(X)) * (sum(Y .^2) - sum(Y)^2 / length(X)));
coeff = fenzi / fenmu;
end %函数myPearson结束
也可以使用Matlab中已有的函数计算皮尔逊相关系数:
coeff = corr(X , Y);
Spearman Rank(斯皮尔曼等级)相关系数
1、简介
在统计学中,斯皮尔曼等级相关系数以Charles Spearman命名,并经常用希腊字母ρ(rho)表示其值。斯皮尔曼等级相关系数用来估计两个变量X、Y之间的相关性,其中变量间的相关性可以使用单调函数来描述。如果两个变量取值的两个集合中均不存在相同的两个元素,那么,当其中一个变量可以表示为另一个变量的很好的单调函数时(即两个变量的变化趋势相同),两个变量之间的ρ可以达到+1或-1。
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。对X、Y进行排序(同时为升序或降序),得到两个元素排行集合x、y,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行。将集合x、y中的元素对应相减得到一个排行差分集合d,其中di=xi-yi,1<=i<=N。随机变量X、Y之间的斯皮尔曼等级相关系数可以由x、y或者d计算得到,其计算方式如下所示:
由排行差分集合d计算而得(公式一):
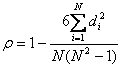
由排行集合x、y计算而得(斯皮尔曼等级相关系数同时也被认为是经过排行的两个随即变量的皮尔逊相关系数,以下实际是计算x、y的皮尔逊相关系数)(公式二):

以下是一个计算集合中元素排行的例子(仅适用于斯皮尔曼等级相关系数的计算)
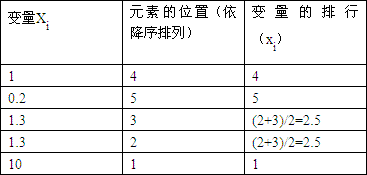
这里需要注意:当变量的两个值相同时,它们的排行是通过对它们位置进行平均而得到的。
2、适用范围
斯皮尔曼等级相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。
3、Matlab实现
源程序一:
斯皮尔曼等级相关系数的Matlab实现(依据排行差分集合d计算,使用上面的公式一)
function coeff = mySpearman(X , Y)
% 本函数用于实现斯皮尔曼等级相关系数的计算操作
%
% 输入:
% X:输入的数值序列
% Y:输入的数值序列
%
% 输出:
% coeff:两个输入数值序列X,Y的相关系数
if length(X) ~= length(Y)
error('两个数值数列的维数不相等');
return;
end
N = length(X); %得到序列的长度
Xrank = zeros(1 , N); %存储X中各元素的排行
Yrank = zeros(1 , N); %存储Y中各元素的排行
%计算Xrank中的各个值
for i = 1 : N
cont1 = 1; %记录大于特定元素的元素个数
cont2 = -1; %记录与特定元素相同的元素个数
for j = 1 : N
if X(i) < X(j)
cont1 = cont1 + 1;
elseif X(i) == X(j)
cont2 = cont2 + 1;
end
end
Xrank(i) = cont1 + mean([0 : cont2]);
end
%计算Yrank中的各个值
for i = 1 : N
cont1 = 1; %记录大于特定元素的元素个数
cont2 = -1; %记录与特定元素相同的元素个数
for j = 1 : N
if Y(i) < Y(j)
cont1 = cont1 + 1;
elseif Y(i) == Y(j)
cont2 = cont2 + 1;
end
end
Yrank(i) = cont1 + mean([0 : cont2]);
end
%利用差分等级(或排行)序列计算斯皮尔曼等级相关系数
fenzi = 6 * sum((Xrank - Yrank).^2);
fenmu = N * (N^2 - 1);
coeff = 1 - fenzi / fenmu;
end %函数mySpearman结束
源程序二:
使用Matlab中已有的函数计算斯皮尔曼等级相关系数(使用上面的公式二)
coeff = corr(X , Y , 'type' , 'Spearman');
注意:使用Matlab自带函数计算斯皮尔曼等级相关系数时,需要保证X、Y均为列向量;Matlab自带的函数是通过公式二计算序列的斯皮尔曼等级相关系数的。一般情况下,使用上面给出的源程序一是可以得到所要的结果的,但是当序列X或Y中出现具有相同值的元素时,源程序一给出的结果就会与Matlab中corr函数计算的结果不同,这是因为当序列X或Y中有相同的元素时,公式一和公式二计算的结果会有偏差。这里可以通过将源程序一中的以下三行
Kendall Rank(肯德尔等级)相关系数
1、简介
在统计学中,肯德尔相关系数是以Maurice Kendall命名的,并经常用希腊字母τ(tau)表示其值。肯德尔相关系数是一个用来测量两个随机变量相关性的统计值。一个肯德尔检验是一个无参数假设检验,它使用计算而得的相关系数去检验两个随机变量的统计依赖性。肯德尔相关系数的取值范围在-1到1之间,当τ为1时,表示两个随机变量拥有一致的等级相关性;当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;当τ为0时,表示两个随机变量是相互独立的。
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。X与Y中的对应元素组成一个元素对集合XY,其包含的元素为(Xi,
Yi)(1<=i<=N)。当集合XY中任意两个元素(Xi, Yi)与(Xj,
Yj)的排行相同时(也就是说当出现情况1或2时;情况1:Xi>Xj且Yi>Yj,情况2:Xi<Xj且Yi<Yj),这两个元素就被认为是一致的。当出现情况3或4时(情况3:Xi>Xj且Yi<Yj,情况4:Xi<Xj且Yi>Yj),这两个元素被认为是不一致的。当出现情况5或6时(情况5:Xi=Xj,情况6:Yi=Yj),这两个元素既不是一致的也不是不一致的。
这里有三个公式计算肯德尔相关系数的值
公式一:
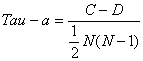
其中C表示XY中拥有一致性的元素对数(两个元素为一对);D表示XY中拥有不一致性的元素对数。
注意:这一公式仅适用于集合X与Y中均不存在相同元素的情况(集合中各个元素唯一)。
公式二:
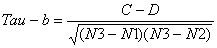
注意:这一公式适用于集合X或Y中存在相同元素的情况(当然,如果X或Y中均不存在相同的元素时,公式二便等同于公式一)。
其中C、D与公式一中相同;
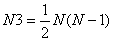 ;
;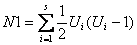 ;
;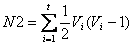
N1、N2分别是针对集合X、Y计算的,现在以计算N1为例,给出N1的由来(N2的计算可以类推):
将X中的相同元素分别组合成小集合,s表示集合X中拥有的小集合数(例如X包含元素:1 2 3 4 3 3 2,那么这里得到的s则为2,因为只有2、3有相同元素),Ui表示第i个小集合所包含的元素数。N2在集合Y的基础上计算而得。
公式三:
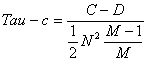
注意:这一公式中没有再考虑集合X、或Y中存在相同元素给最后的统计值带来的影响。公式三的这一计算形式仅适用于用表格表示的随机变量X、Y之间相关系数的计算(下面将会介绍)。
参数M稍后会做介绍。
以上都是围绕用集合表示的随机变量而计算肯德尔相关系数的,下面所讲的则是围绕用表格表示的随机变量而计算肯德尔相关系数的。
通常人们会将两个随机变量的取值制作成一个表格,例如有10个样本,对每个样本进行两项指标测试X、Y(指标X、Y的取值均为1到3)。根据样本的X、Y指标取值,得到以下二维表格(表1):
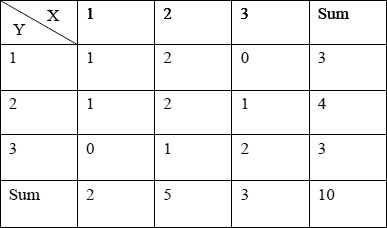
由表1可以得到X及Y的可以以集合的形式表示为:
X={1, 1, 2, 2, 2, 2, 2, 3, 3, 3};
Y={1, 2, 1, 1, 2, 2, 3, 2, 3, 3};
得到X、Y的集合形式后就可以使用以上的公式一或公式二计算X、Y的肯德尔相关系数了(注意公式一、二的适用条件)。
当然如果给定X、Y的集合形式,那么也是很容易得到它们的表格形式的。
这里需要注意的是:公式二也可以用来计算表格形式表示的二维变量的肯德尔相关系数,不过它一般用来计算由正方形表格表示的二维变量的肯德尔相关系数,公式三则只是用来计算由长方形表格表示的二维变量的Kendall相关系数。这里给出公式三中字母M的含义,M表示长方形表格中行数与列数中较小的一个。表1的行数及列数均为三。
2、适用范围
肯德尔相关系数与斯皮尔曼相关系数对数据条件的要求相同,可参见统计相关系数(2)--Spearman Rank(斯皮尔曼等级)相关系数及MATLAB实现中介绍的斯皮尔曼相关系数对数据条件的要求。
3、Matlab实现
fenzi = 6 * sum((Xrank - Yrank).^2);
fenmu = N * (N^2 - 1);
coeff = 1 - fenzi / fenmu;
改为
coeff = corr(Xrank' , Yrank'); %皮尔逊相关系数
这样便可以使源程序一在计算包含相同元素值的变量(至少有一个变量的取值集合中存在相同的元素)间的斯皮尔曼等级相关系数时,得到与Matlab自带函数一样的结果。程序一经过修改过后同样可以用来计算一般变量(两个变量的取值集合中均不存在相同的元素)等级相关间的斯皮尔曼等级系数。
参考链接:https://blog.csdn.net/zhaozhn5/article/details/78392220
学习笔记78—三大统计相关系数:Pearson、Spearman秩相关系数、kendall等级相关系数的更多相关文章
- Spearman秩相关系数和Pearson皮尔森相关系数
1.Pearson皮尔森相关系数 皮尔森相关系数也叫皮尔森积差相关系数,用来反映两个变量之间相似程度的统计量.或者说用来表示两个向量的相似度. 皮尔森相关系数计算公式如下:
- ArcGIS案例学习笔记-点群密度统计
ArcGIS案例学习笔记-点群密度统计 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 目的:对于点群,统计分布密度 数据: 方法: 1. 生成格网 2. 统计个数, ...
- ArcGIS案例学习笔记-栅格数据分区统计(平均高程,污染浓度,污染总量,降水量)
ArcGIS案例学习笔记-栅格数据分区统计(平均高程,污染浓度,污染总量,降水量) 联系方式:谢老师,135-4855-4328,xiexiaokui@qq.com 目的:针对栅格数据,利用多边形面要 ...
- 三大统计相关系数:Pearson、Spearman秩相关系数、kendall等级相关系数
统计相关系数简介 由于使用的统计相关系数比较频繁,所以这里就利用几篇文章简单介绍一下这些系数. 相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度. 如果有两个变量:X.Y,最终计算出的相 ...
- 三大相关系数: pearson, spearman, kendall(python示例实现)
三大相关系数:pearson, spearman, kendall 统计学中的三大相关性系数:pearson, spearman, kendall,他们反应的都是两个变量之间变化趋势的方向以及程度,其 ...
- [原创]java WEB学习笔记78:Hibernate学习之路---session概述,session缓存(hibernate 一级缓存),数据库的隔离级别,在 MySql 中设置隔离级别,在 Hibernate 中设置隔离级别
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- 学习笔记_Java_day13_JSP三大指令()
JSP指令 1 JSP指令概述 JSP指令的格式:<%@指令名 attr1=”” attr2=”” %>,一般都会把JSP指令放到JSP文件的最上方,但这不是必须的. JSP ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- Android(java)学习笔记78:设计模式之单例模式
单例模式代码示例: 1. 单例模式之饿汉式: package cn.itcast_03; public class Student { // 构造私有 private Student() { } // ...
随机推荐
- 使用 AudioContext 播放音频 解决 谷歌禁止自动播放音频
window.AudioContext = window.AudioContext || window.webkitAudioContext || window.mozAudioContext || ...
- HDU 1520 树形DP入门
HDU 1520 [题目链接]HDU 1520 [题目类型]树形DP &题意: 某公司要举办一次晚会,但是为了使得晚会的气氛更加活跃,每个参加晚会的人都不希望在晚会中见到他的直接上司,现在已知 ...
- linux----------CentOS的一些除了yum安装以外的基本操作命令。
1.tail -n 5 文件名字 : 查看大型文件的后五行内容 head -n 5 文件名字 : 查看文件的前五行内容 2.ls -lh 可以查看文件大小转换以后 ...
- redis maxheap 51200000
Redis无法启动 今天在启动Redis时提示以下错: C:\Java\redis2817>redis-server.exe redis.windows.conf [5268] 23 Apr 1 ...
- 关于 IIS 的 Management Service Delegation 配置 备份
在MSDN没找到关于使用APPCMD备份IIS的"Management Service Delegation"模块配置命令. 到IIS的配置文件存放目录下,几番搜索,查到%wind ...
- -bash: belts.awk: command not found
执行awk命令时,没有问题.可是执行awk脚本时,出现这个问题:-bash: belts.awk: command not found. 既然之前直接执行awk命令没有问题,说明awk已经装了,本身是 ...
- MySQL相关问题题
1.truncate.delete.drop的区别 (1)truncate.drop是不可以rollback的,但是delete是可以rollback的.DELETE语句执行删除的过程是每次从表中删除 ...
- JS实现div的抖动:缓动式抖动
代码如下: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <tit ...
- 2017-12-26--mysql(5.6.15),linux下安装使用
本文档的目的是,指导使用者安装.配置.还原所需要用到的mysql数据库.仅提供linux版本服务器的安装说明,且linux版本为64位的Centos6.4.同时,会提供的mysql安装包(MySQL- ...
- Linux退出状态码
命令成功结束 一般性未知错误 不适合的shell命令 命令不可执行 没找到命令 无效的退出参数 +x 与Linux信号x相关的严重错误 通过Ctrl+C终止的命令 正常范围之外的退出状态码