HBase篇--初始Hbase
一.前述
1.HBase,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库。
2.利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务。
3.主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)。
二.Hbase数据模型
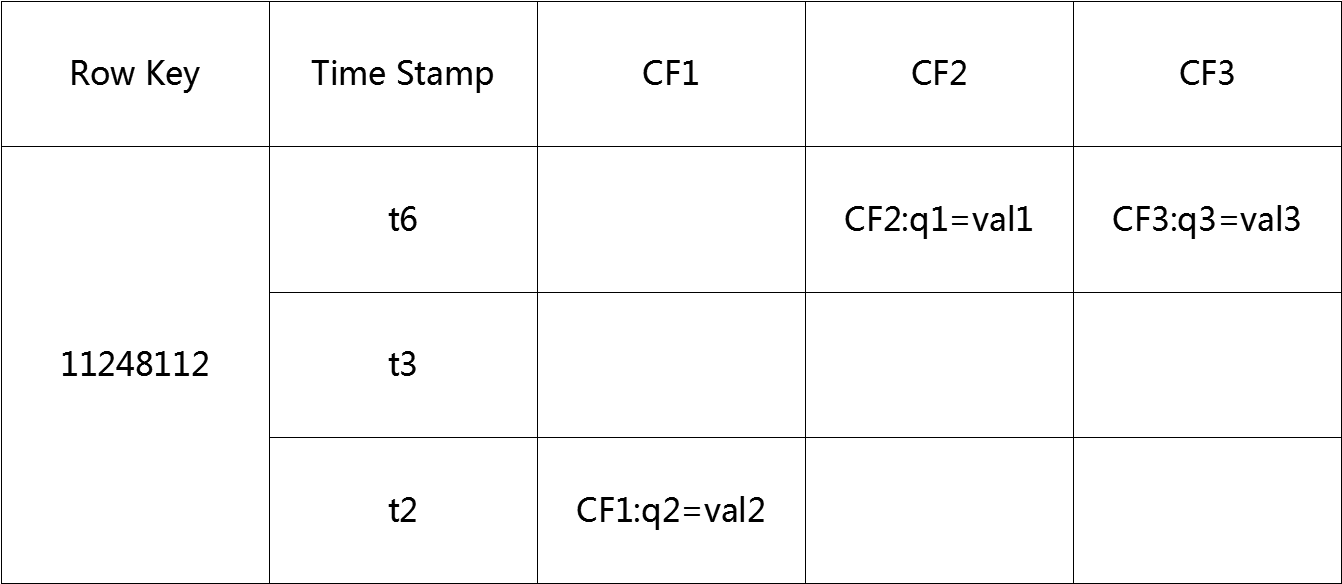
2.1 ROW KEY(相当于关系型数据库中的ID)
决定一行数据
按照字典顺序排序的。
Row key只能存储64k的字节数据
2.2 Column Family列族 & qualifier列
HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math, course:english, 新的列族成员(列)可以随后按需、动态加入;
权限控制、存储以及调优都是在列族层面进行的(相当于最小单位是列族!!!)
HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
2.3 Timestamp时间戳(相当于版本!!!)
在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
时间戳的类型是 64位整型。
时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
2.4 Cell单元格
由行和列的坐标交叉决定;
单元格是有版本的;
单元格的内容是未解析的字节数组;
由{row key, column( =<family> +<qualifier>), version} 唯一确定的单元。!!!
cell中的数据是没有类型的,全部是字节码形式存贮。!!!
三.Hbase架构
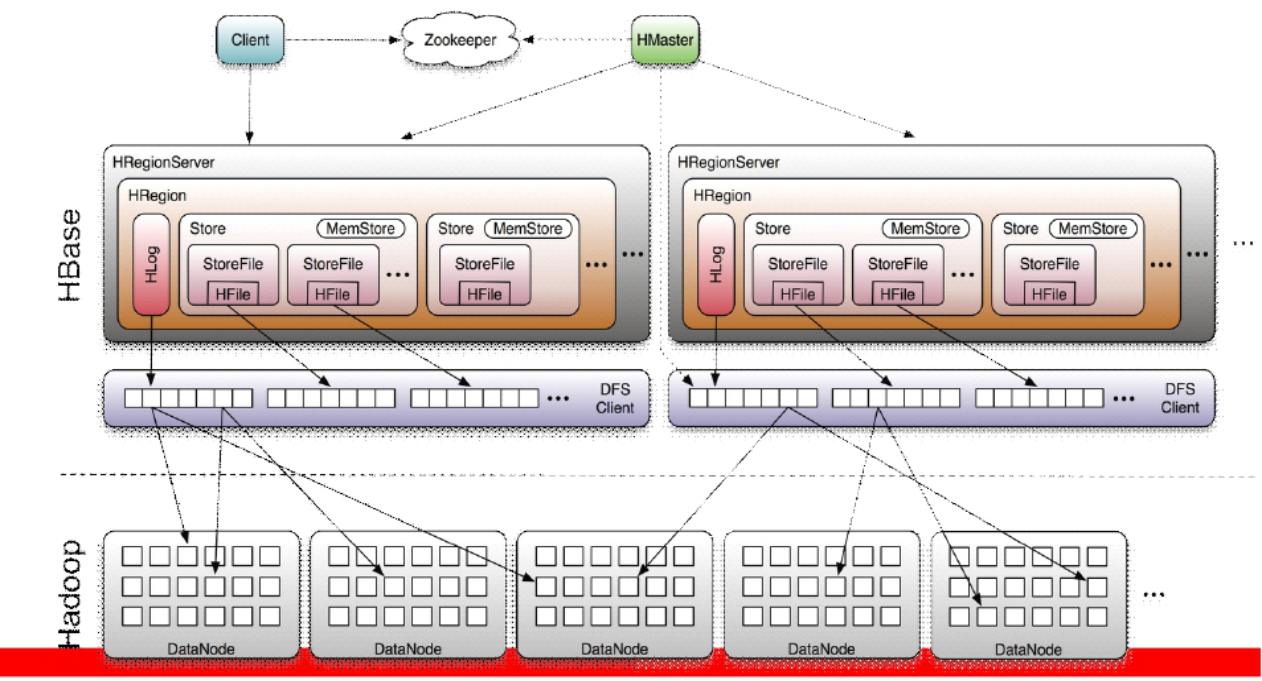
3.1 Client
包含访问HBase的接口并维护cache来加快对HBase的访问
3.2 Zookeeper
保证任何时候,集群中只有一个master(HA)
存贮所有Region的寻址入口。(同时存储数据)
实时监控Region server的上线和下线信息。并实时通知Master(当某一个Region server挂掉时,通知Hmaster去将其上的数据分发给其他的region Server)
存储HBase的schema和table元数据(存储元数据信息)
3.3 Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改操作(是管理操作!!!)
3.4 RegionServer
Region server维护当前节点的region,处理对这些region的IO请求
Region server负责切分在运行过程中变得过大的region
3.5 Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据
每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变)
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
3.6 Memstore 与 storefile
一个region由多个store组成,一个store对应一个CF(列族)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile(有些类似Hadoop中的Mapper阶段的写数据)
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
客户端检索数据,先在memstore找,找不到再找storefile
注意:1.major会把HStore所有的HFile都compact为一个HFile,并同时忽略标记为delete的KeyValue(被删除的KeyValue只有在compact过程中才真正被"删除"),可以想象major会产生大量的IO操作,对HBase的读写性能产生影响。minor则只会选择数个HFile文件compact为一个HFile。
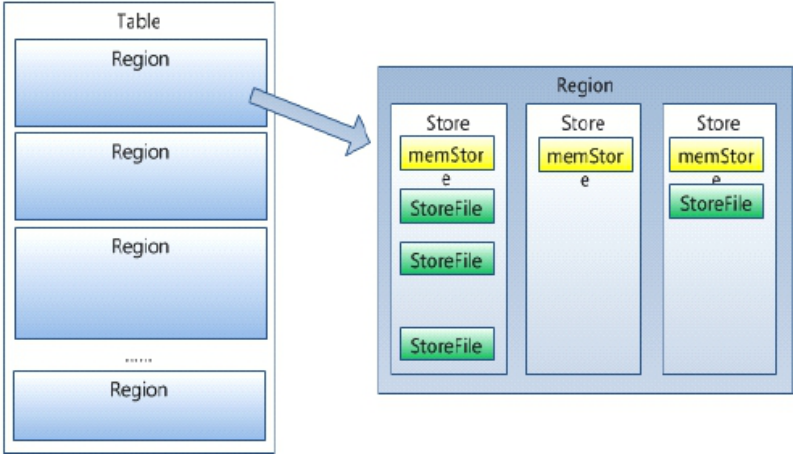
2.HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。(HFile只是另一个叫法而已,对应于HDFS上)
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

HBase篇--初始Hbase的更多相关文章
- HBase篇--搭建HBase完全分布式集群
一.前述. 完全分布式基于hadoop集群和Zookeeper集群.所以在搭建之前保证hadoop集群和Zookeeper集群可用.可参考本人博客地址 https://www.cnblogs.com/ ...
- Hbase篇--HBase中一对多和多对多的表设计
一.前述 今天分享一篇关于HBase的一对多和多对多的案例的分析. 二.具体案例 案例一.多对多 人员-角色 人员有多个角色 角色优先级 角色有多个人员 人员 删除添加角色 角 ...
- 大数据篇:Hbase
大数据篇:Hbase Hbase是什么 Hbase是一个分布式.可扩展.支持海量数据存储的NoSQL数据库,物理结构存储结构(K-V). 如果没有Hbase 如何在大数据场景中,做到上亿数据秒级返回. ...
- HBase篇--HBase常用优化
一.前述 HBase优化能够让我们对调优有一定的理解,当然企业并不是所有的优化全都用,优化还要根据业务具体实施. 二.具体优化 1.表的设计 1.1 预分区 默认情况下,在创建HBase表的时候会自 ...
- HBase 实战(1)--HBase的数据导入方式
前言: 作为Hadoop生态系统中重要的一员, HBase作为分布式列式存储, 在线实时处理的特性, 备受瞩目, 将来能在很多应用场景, 取代传统关系型数据库的江湖地位. 本篇博文重点讲解HBase的 ...
- 4 hbase表结构 + hbase集群架构及表存储机制
本博文的主要内容有 .hbase读取数据过程 .HBase表结构 .附带PPT http://hbase.apache.org/ 读写的时候,就需要用hbase了,换句话说,就是读写的时候. ...
- HBase 2、HBase安装与初试牛刀
官方帮助文档:http://hbase.apache.org/book.html PDF:http://hbase.apache.org/apache_hbase_reference_guide.p ...
- HBase案例:HBase 在人工智能场景的使用
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用.人工智能的主要场景又包括图像能力.语音能力.自然语言处理能力和用户画像能力等等.这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储 ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
随机推荐
- nginx学习.第一部分
1.nginx的版本发布历史 2015年支持thread pool提供stream四层反向代理支持reuseport特性,支持http v2协议.完全可以替代LVS 2016年支持动态模块 2.ngi ...
- 解决使用redis作为session缓存 报错 Error: no such key 的问题
spring的issue https://github.com/spring-projects/spring-session/issues/954 原答案是 Updated my codes to 2 ...
- ImCash:币安下架BSV之辩:规则、中立与去中心化
一种看法是:一个引用价格数据和执行交易的加密货币交易所,其业务决策往往是在链外发生的,不受制于严格的.类似于准宪法的链上规则的约束,加密货币交易所可以拒绝任何人喜欢的价格和交易,而且这样做并不会损害底 ...
- ArcGIS Server学习之问题:ArcGIS Server10.5发布地图显示空白
一.安装ArcGIS10.5 参考ArcGIS 10.5 for Desktop 完整安装教程(含win7/8/10 32/64位+下载地址+亲测可用) | 麻辣GIS 二.安装ArcGIS Serv ...
- 通过excel获取一串连续的数字
输入一个格式的数字 点击按住右下角 拖动即可
- SpringBoot整合使用JdbcTemplate
JdbcTemplate是Spring框架自带的对JDBC操作的封装,目的是提供统一的模板方法使对数据库的操作更加方便.友好,效率也不错. 整合使用JdbcTemplate实现对图书的添加功能小案例 ...
- 对象关系映射 ORM
1.1 作用 MTV框架中包括一个重要的部分,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因 ...
- 09-Python入门学习-函数基础与参数
一.函数基础 1.定义函数的三种形式 1.1 无参函数 def foo(): print('from foo') foo() 1.2 有参函数 def bar(x,y): print(x,y) bar ...
- 更换MariaDB数据库
https://downloads.mariadb.org/mariadb/repositories/#mirror=neusoft&distro=Ubuntu&distro_rele ...
- Idea下的springboot mysql8.0等报错解决随笔
cannot load jdbc class path:mysql8.0装载失败,可能原因,驱动名称错误,连接字符串中需要加入时区UTC,否则8.0一定会报错无法连接,关闭SSL 在applicati ...