pd.read_csv() 、to_csv() 之 常用参数
本文简单介绍一下read_csv()和 to_csv()的参数,最常用的拿出来讲,较少用的请转到官方文档看。
一.pd.read_csv()
作用:将csv文件读入并转化为数据框形式。
pd.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=False, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=False, compact_ints=False, use_unsigned=False, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)
好多参数呀!
下面来看常用参数:
1.filepath_or_buffer:(这是唯一一个必须有的参数,其它都是按需求选用的)
文件所在处的路径
2.sep:
指定分隔符,默认为逗号','
3.delimiter : str, default None
定界符,备选分隔符(如果指定该参数,则sep参数失效)
4.header:int or list of ints, default ‘infer’
指定哪一行作为表头。默认设置为0(即第一行作为表头),如果没有表头的话,要修改参数,设置header=None
5.names:
指定列的名称,用列表表示。一般我们没有表头,即header=None时,这个用来添加列名就很有用啦!
6.index_col:
指定哪一列数据作为行索引,可以是一列,也可以多列。多列的话,会看到一个分层索引
7.prefix:
给列名添加前缀。如prefix="x",会出来"x1"、"x2"、"x3"酱纸
8.nrows : int, default None
需要读取的行数(从文件头开始算起)
9.encoding:
乱码的时候用这个就是了,官网文档看看用哪个:
https://docs.python.org/3/library/codecs.html#standard-encodings
10.skiprows : list-like or integer, default None
需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
下面是举栗子时间:
import pandas as pd
data = pd.read_csv(r"G:\data\Kaggle\Titanic\train.csv")
data.head()
.dataframe thead tr:only-child th {
text-align: right;
}
.dataframe thead th {
text-align: left;
}
.dataframe tbody tr th {
vertical-align: top;
}
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
data1 = pd.read_csv(r"G:\data\Kaggle\Titanic\train.csv",header=None) #可以看到表头都直接当作数据在用了
data1.head()
.dataframe thead tr:only-child th {
text-align: right;
}
.dataframe thead th {
text-align: left;
}
.dataframe tbody tr th {
vertical-align: top;
}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
| 1 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.25 | NaN | S |
| 2 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.925 | NaN | S |
| 4 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1 | C123 | S |
data2 = pd.read_csv(r"G:\data\Kaggle\Titanic\train.csv",index_col=["Survived","Sex"])
data2.head()
.dataframe thead tr:only-child th {
text-align: right;
}
.dataframe thead th {
text-align: left;
}
.dataframe tbody tr th {
vertical-align: top;
}
| PassengerId | Pclass | Name | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Survived | Sex | ||||||||||
| 0 | male | 1 | 3 | Braund, Mr. Owen Harris | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | female | 2 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| female | 3 | 3 | Heikkinen, Miss. Laina | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | |
| female | 4 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | |
| 0 | male | 5 | 3 | Allen, Mr. William Henry | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
data3 = pd.read_csv(r"G:\data\Kaggle\Titanic\train.csv", skiprows=3, header=None) #包括表头的前三行被跳过了
data3.head()
.dataframe thead tr:only-child th {
text-align: right;
}
.dataframe thead th {
text-align: left;
}
.dataframe tbody tr th {
vertical-align: top;
}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 1 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 2 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 3 | 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 4 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
二.pd.to_csv()
作用:将数据框写入本地电脑,保存起来
先了解一下当前工作路径
import os
father_path = os.getcwd()
father_path
'C:\\Users\\acerpc'
to_csv(path_or_buf,sep,na_rep,columns,header,index)
参数解析:
1.path_or_buf:字符串,放文件名、相对路径、文件流等;
2.sep:字符串,分隔符,跟read_csv()的一个意思
3.na_rep:字符串,将NaN转换为特定值
4.columns:列表,指定哪些列写进去
5.header:默认header=0,如果没有表头,设置header=None,表示我没有表头呀!
6.index:关于索引的,默认True,写入索引
举栗子时间到:
import numpy as np
df = pd.DataFrame({"a":[1,2,3],
"b":[6,np.nan,6],
"c":[3,4,np.nan]})
df
.dataframe thead tr:only-child th {
text-align: right;
}
.dataframe thead th {
text-align: left;
}
.dataframe tbody tr th {
vertical-align: top;
}
| a | b | c | |
|---|---|---|---|
| 0 | 1 | 6.0 | 3.0 |
| 1 | 2 | NaN | 4.0 |
| 2 | 3 | 6.0 | NaN |
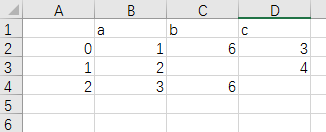
path1 = father_path + r'\df1.csv'
df.to_csv(path1)

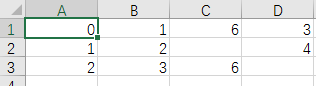
path2 = father_path + r'\df2.csv'
df.to_csv(path2,header=None)

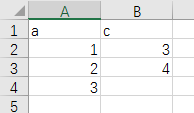
path3 = father_path + r'\df3.csv'
df.to_csv(path3, columns=["a","c"],index=False)

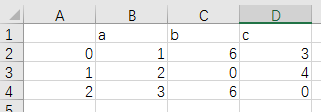
path4 = father_path + r'\df4.csv'
df.to_csv(path4, na_rep=0)

pd.read_csv() 、to_csv() 之 常用参数的更多相关文章
- pandas.read_csv to_csv参数详解
pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/pandas ...
- pd.read_csv参数解析
对pd.read_csv参数做如下解释: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', n ...
- [Python Study Notes]pd.read_csv()函数读取csv文件绘图
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ...
- pd.read_csv操作读取分隔符csv和text文件
pandas.read_csv可以读取CSV(逗号分割)文件.文本类型的文件text.log类型到DataFrame 1. pandas.read_csv常用参数整理 也支持文件的部分导入和选择迭代 ...
- 使用read、readline、readlines和pd.read_csv、pd.read_table、pd.read_fwf、pd.read_excel获取数据
从文本文件读取数据 法一: 使用read.readline.readlines读取数据 read([size]):从文件读取指定的字节数.如果未给定或为负值,则去取全部.返回数据类型为字符串(将所有行 ...
- Production环境中iptables常用参数配置
production环境中iptables常用参数配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我相信在实际生产环境中有很多运维的兄弟跟我一样,很少用到iptables的这个 ...
- chattr的常用参数详解
chattr的常用参数详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际生产环境中,有的运维工程师不得不和开发和测试打交道,在我们公司最常见的就是部署接口.每天每个人部署的 ...
- dmidecode常用参数
dmidecode常用参数详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. dmidecode这个命令真是神器啊,他能快速的获取服务器的硬件信息,而且这个命令有很多的花式玩法,今 ...
- find常用参数详解
find常用参数详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在linux系统中,在init 3模式情况下都是命令行模式,这个时候我们想要找到一个文件的就得依赖一个非常好用的 ...
随机推荐
- SRS-开源流媒体服务器
SRS 简介 SRS定位是运营级的互联网直播服务器集群,追求更好的概念完整性和最简单实现的代码.SRS提供了丰富的接入方案将RTMP流接入SRS, 包括推送RTMP到SRS.推送RTSP/UDP/FL ...
- opensuse使用zypper安装软件
安装软件(opensuse) opensuse 通过zypper可以方便的进行软件管理,类似centos的yum 软件. 命令参考 软件包操作 搜索软件 zypper search package 安 ...
- 痞子衡嵌入式:串口调试工具Jays-PyCOM诞生记(1)- 环境搭建(Python2.7.14 + pySerial3.4 + wxPython4.0.3)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是串口调试工具Jays-PyCOM诞生之环境搭建. 在写Jays-PyCOM时需要先搭好开发和调试环境,下表列出了开发过程中会用到的所有软 ...
- MySQL中 and or 查询的优先级
这个可能是容易被忽略的问题,首选我们要清楚:MySQL中,AND的执行优先级高于OR.也就是说,在没有小括号()的限制下,总是优先执行AND语句,再执行OR语句.比如: select * from t ...
- Linux设备驱动之IIO子系统——IIO框架数据读取
IIO DATA ACCESS IIO数据获取 只有两种方法可以使用IIO框架访问数据; 通过sysf通道进行一次性捕获,或通过IIO字符设备进行连续模式(触发缓冲). One-shot captur ...
- CSS宽高背景介绍
本萌新还未毕业,在一家外包公司干了一个月,因烦恼日常琐事任务,深感外包之坑,以及上班路途艰辛,特转战erp实施,继写日常随笔,望来日屌丝逆袭,走上人生巅峰. 若有错误,请前辈指点迷津,在下谢过. &l ...
- 自定义一个全屏的AlertDialog。
........... final MyDialog dialog = new MyDialog(this); LayoutInflater inflater = getLayoutInflater( ...
- Android 网络框架 OKHttp3
概述 OKHttp是一个处理网络请求的框架,其优点有,支持http2,对一台机器的所有请求共享同一个socket. 内置连接池,支持连接复用,减少延迟.通过缓存避免重复的请求,请求失败时自动重试主机的 ...
- Android注解神器 ButterKnife框架
前言: 本人是一个只有几个月工作经验的码小渣.这是我写的第一篇博客,如有不足之处还请大家不要介意,还请大佬可以指出问题. 在这几个月的实战开发中自己也遇到了很多问题,真的是举步艰难啊!!! 在实战开发 ...
- sql左外连接和右外连接的区别例子转摘
sql左外连接和右外连接的区别 两个表:A(id,name)数据:(1,张三)(2,李四)(3,王五)B(id,name)数据:(1,学生)(2,老师)(4,校长) 左连接结果:select A. ...