Baolu CSV Data Set Config
1.背景
大家在平常使用JMeter测试工具时,对CSV Data Set Config 配置元件肯定不会陌生。如果我们的压测场景涉及到数据库更新操作(如:转账接接口)则需要对参数化数据进行分块,可就犯难了。如果不进行数据分块那么数据库会出现大量锁等待,造成我们测试结果可信度大大降低。今天宝路就聊下JMeter如何优雅的做到数据分块。
2.初衷
前面说到数据分块,大家可能会优先想到传统商业压测工具LoadRunner,因为LR是比较完美的支持数据分块的。
看了今天的文章的主题,相信大家心中应该就有答案了。其实早在宝路刚转这个行不久时就已经开发了这个功能,只不过当时是在官方源码的基础改动,每当升级JMeter版后,还要把这些新增代码移植到新版上,甚是麻烦。。。。。。关于实现逻辑大家可以参考下我早期写的 CSV Data Set Config 拓展开发 这篇文章。
最近宝路把这个功能做成了插件,代码也进行了重构优化,插件下载详见“宝路测试手记”微信公众号,下面我们就来揭开它的神秘面纱。
3.实战
插件截图:
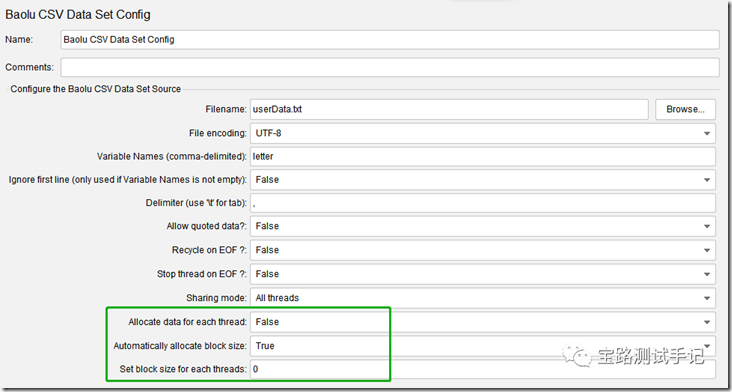
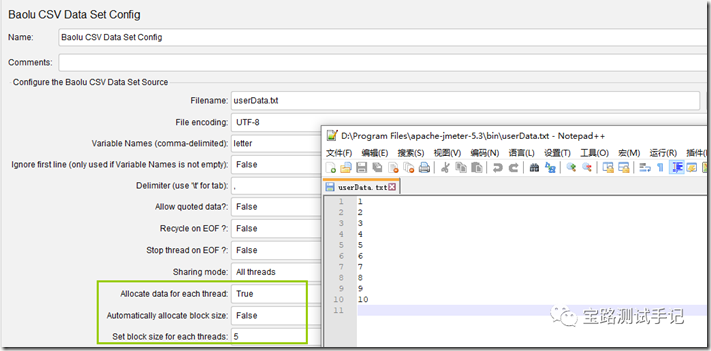
本插件是在JMeter源生的 CSV Data Set Config 进了拓展开发,新增参数说明:
|
参数 |
说明 |
| Allocate data for each thread | When it is true (default false), the parameterized file is partitioned by threads, and each thread is allocated with different block data |
| Automatically allocate block size | Only Allocate data for each thread set true |
| Set block size for each threads | Only Allocate data for each thread set true and automatically allocate block size set false |
重要的事情说三遍,插件支持中文释义、插件支持中文释义、插件支持中文释义。。。

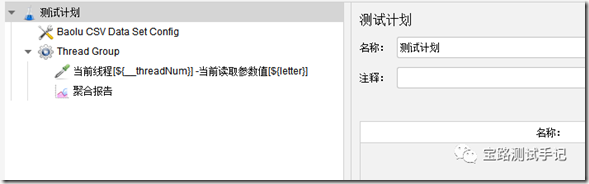
实战验证--脚本结构图:
实战验证--测试结果(一):
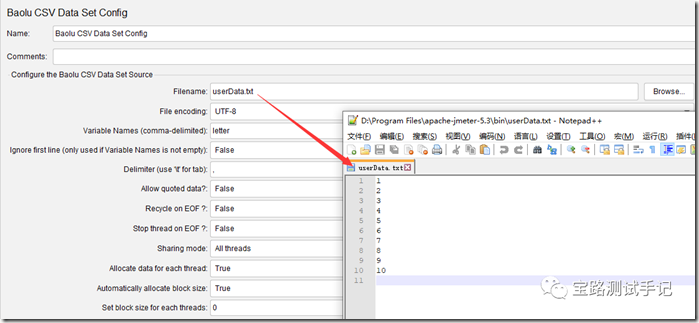
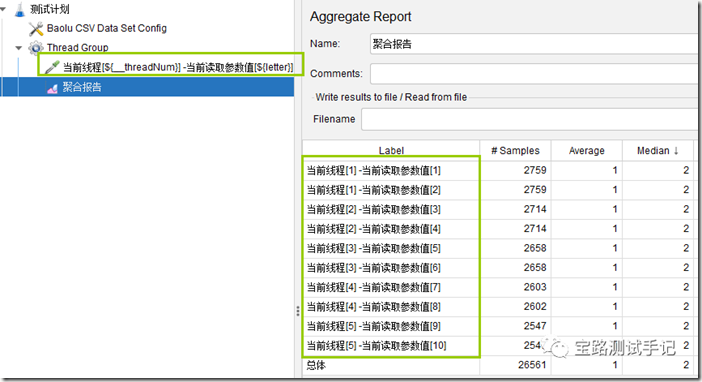
从结果图可以看出,当采用自动分配数据块时,宝路设置线程组共启动5个线程,此时每个线程固定分2条数据。那么我们再把线程大小调整到10看看运行结果。
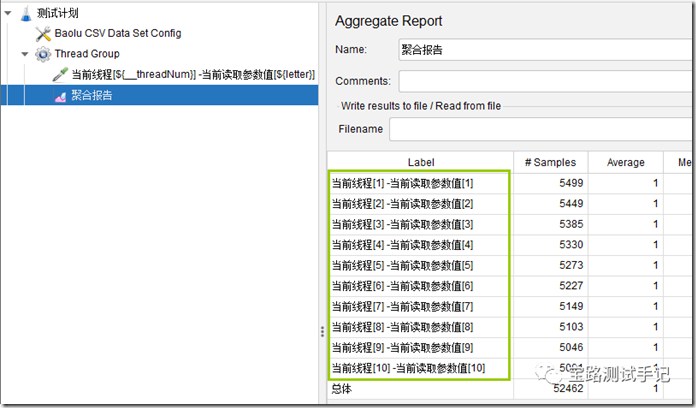
嗯!此时每个线程固定分配1条数据。
实战验证--测试结果(二):
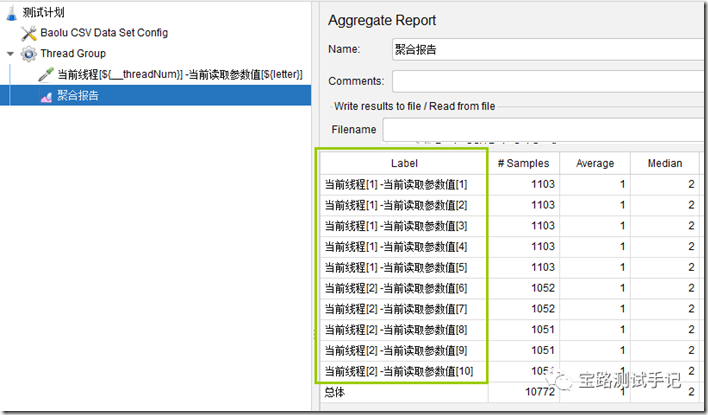
从结果图可以看出,当采用手动指定线程分配数据块时,宝路设置线程组共启动2个线程,设置每个线程分配5条数据,此时第一个线程只会读取前5条数据,第二个线程仅会读取后5条数据。
如果保持线程组仍启动2个线程,设置每个线程分配6条数据,会是什么样的结果呢?
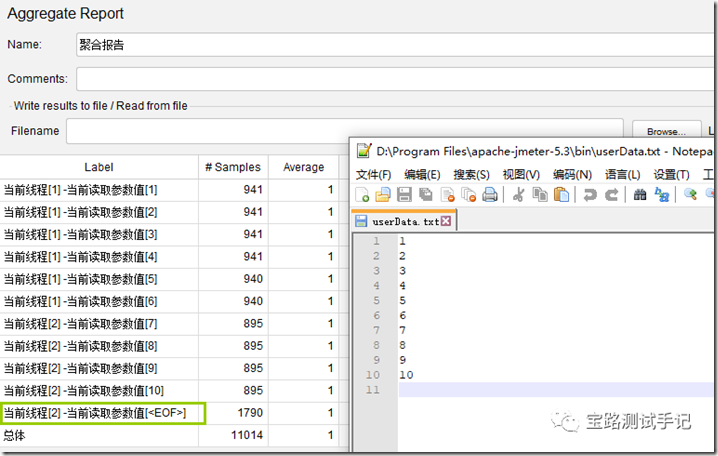
可以看到出现了<EOF>值,其实不难看出是因为数据不够分了。。。。宝路这边采用EOF标记来提示。
插件下载以及后续优化方向:
由于JMeter分布式压测试模式的原因,目前仍需手动将参数化文件copy到指定slave机目录,后续宝路考虑可能会加入同步salve机参数化文件的功能,或者单独开发一个同步文件插件。
实际使用中可能还有从指定行开始读取数据的场景,比如:某个参数化文件里面存放的是消耗型数据,在某次场景执行完毕后消耗了100行,那么后续再次执行场景时,应该从101行开始读取数据,这样就不用测试人员花大量时间去准备好多参数化文件。
关于Baolu CSV Data Set Config插件,大家如果有任何疑问或建议,欢迎给宝路留言。
Baolu CSV Data Set Config的更多相关文章
- JMeter学习-010-JMeter 配置元件实例之 - CSV Data Set Config 参数化配置
众所周知,在进行接口测试的过程中,需要创建不同的场景(不同条件的输入,来验证不同的入参的返回结果).因而,在日常的自动化接口监控或商品监控等线上监控过程中,需要配置大量的入参来监控接口的返回是否正确. ...
- Jmeter—6 CSV Data Set Config 通过文件导入数据
线程组循环次数大于1的时候,请求里每次提交的数据都相同.有的系统限制了不能提交相同数据,我们通过 CSV Data Set Config 加载csv文件数据. 1 创建一个文本文件,输入参数值保存为. ...
- Jmeter组件1. CSV Data Set Config
位置:Test Plan | Add | Config Element | CSV Data Set Config 意义: 脚本参数化 节省CPU跟内存(可以准备好数据文件去代替动态生成数据,节约CP ...
- JMeter脚本参数化和断言设置( CSV Data Set Config )
用Badboy录制了Jmeter的脚本,用Jmeter打开后形成了原始的脚本.但是在实际应用中,为了增强脚本的多样性,就要使脚本参数化.这里我以登录为例,参数化用户账号与用户密码. 图1 :原始脚本 ...
- jmeter参数化之CSV Data Set Config
在jmeter中,可以用CSV Data Set Config实现参数化. 1.准备参数化数据
- 转:Jmeter之使用CSV Data Set Config实现参数化登录
在使用Jemeter做压力测试的时候,往往需要参数化用户名,密码以到达到多用户使用不同的用户名密码登录的目的.这个时候我们就可以使用CSV Data Set Config实现参数化登录: 首先通过Te ...
- 转:CSV Data Set Config 中文乱码问题
从csv读取中文一直乱码. CSV Data Set Config的File encoding为GB2312,对应参数化文件编码也为GB2312,但读取出变量值一直为乱码,后发现是Allow quot ...
- 配置 CSV Data Set Config 来参数化新增客户信息操作
1.首先根据新增客户信息的http请求,来确定需要参数化的变量,选取符合测试需求且经常变化或未来会变化的变量为需要参数化的变量,如本文中的客户端名称(sys_name).描述(description) ...
- jmeter笔记(5)--参数化--CSV Data Set Config
为了保证脚本的可移植性,我们需要把数据提取出来作为变量,变量可以分为两类: 公用变量:IP.端口.附件路径.CSV文件路径等: 测试变量:用户名.密码.用户ID.商品ID等 使用CSV Data Se ...
随机推荐
- [剑指Offer]17-打印从1到最大的n位数(递归)
题目 如题,输入n,则从1打印至99. 题解 考虑到n比较大会有大数问题,所以使用字符数组存储数. 由题可用递归求n位全排列,即为所得. 具体地,用临时字符数组用来存答案,每次递归填好一位,都填好后输 ...
- zookeeper源码之服务端
zookeeper服务端主要包括一下几个模块: 1.启动模块. 2.核心执行模块 3.数据管理模块. 启动模块 读取配置文件,启动程序.详见:zookeeper源码之服务端启动模块. 核心执行 ...
- CRM、用户管理权限
CRM目录结构 from django.shortcuts import HttpResponse,render,redirect from django.conf.urls import url f ...
- python-scrapy框架初探
内置支持 selecting and extracting 使用扩展的CSS选择器和XPath表达式从HTML/XML源中获取数据,并使用正则表达式提取助手方法. interactive shell ...
- spring中配事务的工具配置
<!--配置事务--><bean id="transactionManager" class="org.springframework.jdbc.dat ...
- Spring Boot学习(一)初识Spring Boot
Spring Boot 概述 Spring Boot 是所有基于 Spring 开发的项目的起点.Spring Boot 的设计是为了让你尽可能快的跑起来 Spring 应用程序并且尽可能减少你的配置 ...
- 论文阅读 SNAPSHOT ENSEMBLES
引入 1. 随机梯度下降的特点 随机梯度下降法(Stochastic Gradient Descent)作为深度学习中主流使用的最优化方法, 有以下的优点: 躲避和逃离假的鞍点和局部极小点的能力 这篇 ...
- Linux Wait Queue 等待队列
一.引言 linux 内核的等待队列和进程调度息息相关,进程在某些情况下必须等待某些事件的发生,例如:等待一个磁盘操作的终止,等待释放系统资源,或等待指定的时间间隔. 等待队列实现了在事件上的条件等待 ...
- C++实现职工管理系统(下)
C++实现职工管理系统(下) 大家好,今天是在博客园的第十五天,博主今天给大家带来的是职工管理系统(C++)(下) 这次的随笔记录是实现(中)结语处说的几个功能,另外新增一个修改功能 此次要实现的功能 ...
- modelviewset settings 配置
# 过滤器 # 1,安装 django-filter # 2,注册应用 # 3,配置settings, 在view里配置可过滤的字段 # 4,使用 查询字符串携带过滤信息 REST_FRAMEWORK ...