第24课 - #pragma 使用分析
第24课 - #pragma 使用分析

1. #pragma简介
(1)#pragma 是一条预处理器指令
(2)#pragma 指令比较依赖于具体的编译器,在不同的编译器之间不具有可移植性,表现为两点:
① 编译器A支持的 #pragma 指令在编译器B中也许并不支持,如果编译器B碰到这条不认识的指令就会忽略它。比如下文中介绍的 #pragma once指令,gcc编译器和VS编译器是支持的,但bcc编译器就不支持。
② 同一条 #pragma指令,不同的编译器可能会有不同的解读。
(3)一般用法:#pragma parameter // 注意,不同的 parameter参数 语法和含义是不同的
2. #pragma message指令
(1)message参数在大多数的编译器中都有相似的实现
(2)message参数在编译时输出消息到编译输出窗口中
(3)message用于条件编译可提示代码的版本信息
(4)与 #error 和 #warning不同,#pragma message仅仅代表一条编译消息,不代表程序错误。
【#pragma使用示例】
#include <stdio.h> #if defined(ANDROID20)
#pragma message("Compile Android SDK 2.0...")
#define VERSION "Android 2.0"
#elif defined(ANDROID23)
#pragma message("Compile Android SDK 2.3...")
#define VERSION "Android 2.3"
#elif defined(ANDROID40)
#pragma message("Compile Android SDK 4.0...")
#define VERSION "Android 4.0"
#else
#error Compile Version is not provided!
#endif int main()
{
printf("%s\n", VERSION); return ;
}
使用 gcc 编译并观察输出结果

使用VS2010的编译器和BCC编译器分别对上述的示例代码进行编译,可以看到结果和gcc编译器的稍有不同,这也验证了上面说的,不同的编译器对同一条 #pragma 指令会有不同的解读。

使用 gcc -E 24-1.c -DANDROID40 编译代码,发现 #pragma message 并不是在预处理的时候输出的。
# "24-1.c"
# "<built-in>"
# "<command-line>"
# "/usr/include/stdc-predef.h"
# "<command-line>"
# "24-1.c"
# "24-1.c" # "24-1.c"
#pragma message("Compile Android SDK 4.0...")
# "24-1.c" int main()
{ return ;
}
此时使用 gcc -S 24-1.c -DANDROID40 编译代码,发现编译报错,说明#pragma message是由编译器(狭义)输出的。
-.c::: note: #pragma message: Compile Android SDK 4.0...
#pragma message("Compile Android SDK 4.0...")
^
如果程序中有多个 #pragma message,由于编译器对每个c文件是自上而下编译的,所以会自上而下输出。
在做上面这个测试时,很疑惑为什么 #pragma经过预处理器处理后是原样输出,这样为啥还叫预处理指令?
咨询了唐老师,其实是自己钻了牛角尖,这里预处理器的处理方式就是将#pragma原封不动的交给编译器(狭义),不能机械的认为预处理指令完全要预处理器处理。
3. #pragma once指令
(1)#pragma once用于保证头文件只被编译一次
(2)#pragma once是编译器相关的,不一定被支持(下面的示例程序,gcc编译器和VS2010编译器可以编译通过,但BCC32编译器却编译失败)
(3)在第22课分析条件编译时,我们介绍了使用条件编译来防止头文件被多次包含。那 #pragma once 和条件编译有什么区别呢?
参考博客:https://www.hhcycj.com/post/item/383.html (博客截图)

// test.c
#include <stdio.h>
#include "global.h"
#include "global.h" int main()
{
printf("g_value = %d\n", g_value); return ;
}
// global.h
#pragma once int g_value = ;
使用 gcc 编译 ==> 编译通过
swj@ubuntu:~/c_course/ch_24$ gcc test.c
swj@ubuntu:~/c_course/ch_24$ ./a.out
g_value =
使用 VS2010 编译 ==> 编译通过
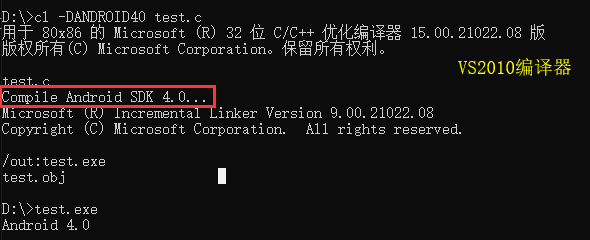
D:\>cl test.c
用于 80x86 的 Microsoft (R) 位 C/C++ 优化编译器 15.00.21022.08 版
版权所有(C) Microsoft Corporation。保留所有权利。 test.c
Microsoft (R) Incremental Linker Version 9.00.21022.08
Copyright (C) Microsoft Corporation. All rights reserved. /out:test.exe
test.obj D:\>test.exe
g_value =
使用 BCC32 编译 ==> 编译失败
D:\>bcc32 test.c
Borland C++ 5.5. for Win32 Copyright (c) , Borland
test.c:
Error E2445 global.h : Variable 'g_value' is initialized more than once // g_value重定义
*** errors in Compile ***
BCC32编译器不支持 #pragma once,遇到 #pragma once之后直接忽略它。
在实际工程中,如果既想有效率又想有移植性,那怎么做呢?一般使用如下的做法。
#pragma once ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_ // source code #endif
4. #pragma pack指令
(1)什么是内存对齐?
不同类型的数据在内存中按照一定的规则排列,而不一定是顺序的一个接一个的排列。
我们看下面这个例子,struct Test1 和 struct Test2 的成员都是相同的,只是在结构体中的位置不同,那两个结构体占用的内存大小相同吗?
#include <stdio.h> #pragma pack(2)
struct Test1
{
char c1;
short s;
char c2;
int i;
};
#pragma pack() #pragma pack(4)
struct Test2
{
char c1;
char c2;
short s;
int i;
};
#pragma pack() int main() {
printf("sizeof(Test1) = %zu\n", sizeof(struct Test1));
printf("sizeof(Test2) = %zu\n", sizeof(struct Test2)); return ;
}
程序的输出结果如下,可见两个结构体的大小并不相同!!!

(2)为什么需要内存对齐?
① CPU对内存的读取不是连续的,而是分成块读取的,块的大小只能是1、2、4、8、16...字节
② 当读取操作的数据未对齐,则需要两次总线周期来访问内存,此性能会大打折扣
③ 某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则产生硬件异常
(3)#pragma pack( )的功能
#pragma pack( ) 可以改变编译器的默认对齐方式(编译器默认为4字节对齐)
下面我们介绍结构体内存对齐的规则(重要!重要!重要!)
- 第一个成员起始于 0偏移处
- 对齐参数:每个结构体成员按照 其类型大小 和 pack参数 中较小的一个进行对齐(如果该成员也为结构体,那就取其内部长度最大的数据成员作为其大小)
- 偏移地址必须能够被对齐参数整除 (0可以被任何非0的整数整除)
- 结构体总长度必须为所有对齐参数的整数倍
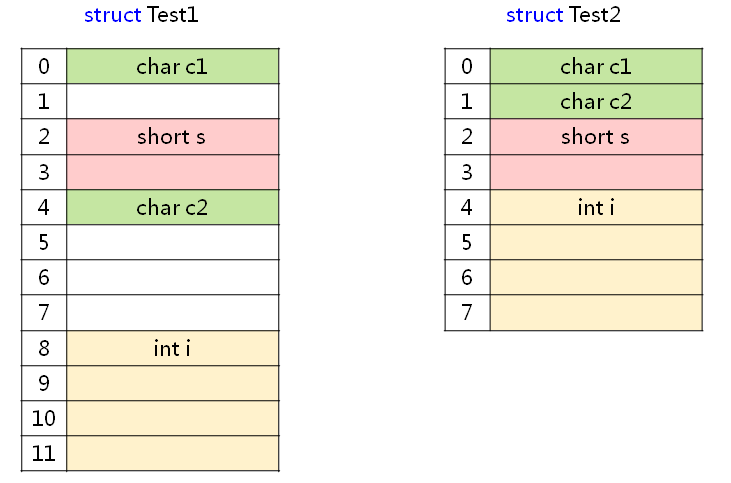
我们根据这个规则来分析一下前面 struct Test1 和 struct Test2 结构体
#pragma pack(2) // 以2字节对齐
struct Test1
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 2 6 4
}; // 在2字节对齐下,该结构体大小为10字节
#pragma pack() #pragma pack(4) // 以4字节对齐
struct Test2
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4
}; // 在4字节对齐下,该结构体大小为8字节
#pragma pack()
分析结果和前面程序的输出结果相同,结构体成员在内存中的位置如下图所示:
上面这个例子比较简单,我们再来看一下微软的一道笔试题
#include <stdio.h> #pragma pack(8) // 以8字节对齐
struct S1
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 8 8 8
}; // 在8字节对齐下,该结构体大小为16字节 struct S2 // 结构体中包含了一个结构体成员,取其内部长度最大的数据成员作为其大小
{ // 对齐参数 偏移地址 大小
char c; // 1 0 1
struct S1 d; // 8 8 16
double e; // 8 24 8
}; // 在8字节对齐下,该结构体大小为32字节
#pragma pack() int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2)); return ;
}
使用gcc编译,程序执行结果如下,和我们分析的结果相同

【这里和唐老师课程中的结果不同,唐老师使用的编译器不支持8字节对齐,即 #pragma pack(8),我的这个gcc支持。】
我们再使用 VS2010编译器 和 BCC32编译器 测试一下上面的代码
VS2010编译器
D:\>cl test.c
用于 80x86 的 Microsoft (R) 位 C/C++ 优化编译器 15.00.21022.08 版
版权所有(C) Microsoft Corporation。保留所有权利。 test.c
Microsoft (R) Incremental Linker Version 9.00.21022.08
Copyright (C) Microsoft Corporation. All rights reserved. /out:test.exe
test.obj D:\>test.exe // 这里和gcc结果不同是因为在该平台下sizeof(long) = 4
BCC32编译器
D:\>bcc32 test.c
Borland C++ 5.5. for Win32 Copyright (c) , Borland
test.c:
Turbo Incremental Link 5.00 Copyright (c) , Borland D:\>test.exe // 这里和gcc结果不同是因为在该平台下sizeof(long) = 4
第24课 - #pragma 使用分析的更多相关文章
- 第24课 #pragma使用分析
#pragma是C语言留给编译器厂商进行扩展用的. 这个关键字在不同的编译器之间也许是不能够移植的. #pragma简介 #pragma message #pragma message打印的消息并不代 ...
- 跟我一起学编程—《Scratch编程》第24课:幸运大转盘
同学你好,欢迎来到<跟我一起学编程>,我是包老师.这是<Scratch3.0编程>课程的第24课,我这节课教你做一个抽奖游戏:幸运大转盘. 学习目标: 1. 能够熟练使用造型工 ...
- Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation
原文:Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. ...
- 第50课 C++对象模型分析(上)
1. 回归本质 (1)class是一种特殊的结构体 ①在内存中class依旧可以看作变量的集合 ②class与struct遵循相同的内存对齐规则 ③class中的成员函数与成员变量是分开存放的.即每个 ...
- #pragma使用分析
#pragma简介 #pragma用于指示编译器完成一些特定的动作 #pragma所定义的很多指示字是编译器特有的 #pragma在不同的编译器间是不可移植的 预处理器将忽略它不认识的#pragma指 ...
- 第51课 C++对象模型分析(下)
1. 单继承对象模型 (1)单一继承 [编程实验]继承对象模型初探 #include <iostream> using namespace std; class Demo { protec ...
- [转][Swust OJ 24]--Max Area(画图分析)
转载自:http://www.cnblogs.com/hate13/p/4160751.html Max Area 题目描述:(链接:http://acm.swust.edu.cn/problem/2 ...
- JAVA_SE基础——24.面向对象的内存分析
黑马程序员入学blog ... 接着上一章的代码: //车类 class Car{ //事物的公共属性使用成员变量描述. String name; //名字的属性 String color; //颜色 ...
- 24.Linux-Nand Flash驱动(分析MTD层并制作NAND驱动)
1.本节使用的nand flash型号为K9F2G08U0M,它的命令如下: 1.1我们以上图的read id(读ID)为例,它的时序图如下: 首先需要使能CE片选 1)使能CLE 2)发送0X90命 ...
随机推荐
- 计算itable的大小
在ClassFileParser::parseClassFile()函数中计算vtable和itable所需要的大小,之前已经介绍过vtable大小的计算,这一篇将详细介绍itable大小的计算过程. ...
- excel表格,根据某一列的值对整行进行颜色填充
1.选中要影响的表格范围,选择 “条件格式”,选择 “新建规则” (2)选择 “使用公式确定要设置格式的单元格”,录入公式,选择 “ 格式”,注意: 公式为:=$H1="待解决" ...
- swagger2配置详解
1.写在controller上的注解 1.1 @Api 代码 @Api(tags = "用户相关接口", description = "提供用户相关的 Rest API& ...
- linux服务器核心知识
电脑:辅助人脑的工具 现在的人们几乎无时无刻都会碰电脑!不管是桌上型电脑(桌机).笔记型电脑(笔电).平板电脑.智慧型手机等等,这些东西都算是电脑.虽然接触的这么多,但是,你了解电脑里面的元件有什么吗 ...
- Robust and Communication-Efficient Federated Learning from Non-IID Data
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 以下是对本文关键部分的摘抄翻译,详情请参见原文. arXiv:1903.02891v1 [cs.LG] 7 Mar 2019 Abstra ...
- pandas电子表格的读取(pandas中的read_excel)
上面那篇文章中,初步介绍了一个文本文件的读取:接下来介绍另外一种常见的本地数据格式,那就是Excel电子表格,如果读者在学习或者工作中需要使用Python分析某个Excel表格数据,改如何完成第一个的 ...
- Java多线程_Semaphore信号量
概念: Semaphore是信号量,又称为信号灯,它可以控制某个共享资源可被同时访问的次数,即可以维护当前访问某一共享资源的线程个数,并提供了同步机制.当Semaphore的个数变成1时,即代表只允许 ...
- 安装openssl后yum不能使用的解决办法
重新编译安装ioenssl后,发现yum命令不能使用,找到如下解决办法 提示错误是 openssl: /usr/lib/x86_64-linux-gnu/libssl.so.1.1: version ...
- Java面试题(设计模式篇+Spring/Spring MVC篇)
设计模式 88.说一下你熟悉的设计模式? 自行熟悉. 89.简单工厂和抽象工厂有什么区别? 简单理解简单工厂:对 一个对象的创建进行封装.抽象工厂:对 一组对象的创建进行封装. 比如生产 陶瓷马 和 ...
- 传统servelt项目之分页操作
需求说明: • 演示最终分页效果 • 提供分页素材 • 分页的作用 • 数据量大,一页容不下 • 后台查询部分数据而不是全部数据 • 降低带宽使用,提高访问速度 • 分页的实现思路 • ...