FastDFS不同步怎么破
一、背景说明
FastDFS是一款开源的分布式文件系统,具体介绍就不说了,有兴趣的可以自行百度下。
以下是官方的架构图:
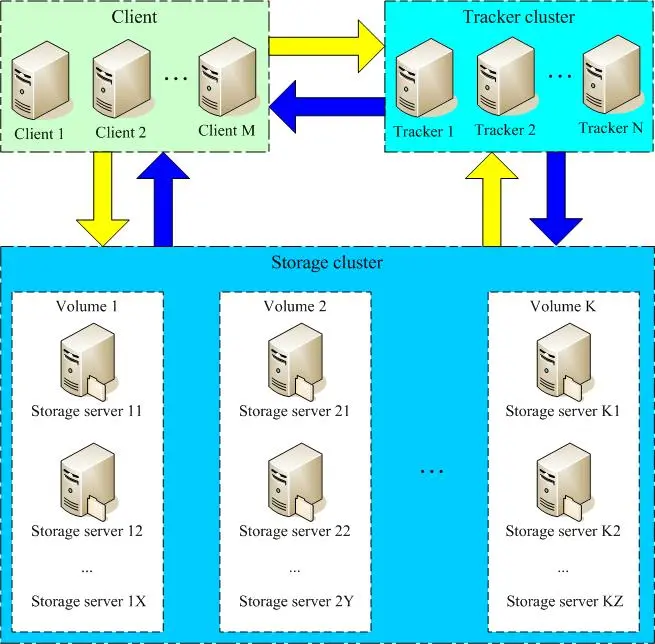
一次完整的写交互过程如下:
1、Client向Tracker查询可用的Storage;
2、Tracker随机返回一个Storage;
3、Client向Storage发起写请求;
一次完整的读交互:
1、Client向Tracker查询可用的Storage;
2、Tracker随机返回一个Storage;
3、Client向Storage发起读请求;
可以看到每个Storage都是对等的,即每个Storage上存储的文件都是全量的。
最近一朋友线上FastDFS服务器老是报文件不存在的错误,版本为5.11:
[2020-08-12 23:16:37] WARNING - file: storage_service.c, line: 6899, client ip: xx.xx.xxx.xxx, logic file: 06/75/xxxx.jpg not exist架构如下:
2台Tracker,2台Storage。
每台机器上都有上述报错。
二、FastDFS同步机制分析
我们先分析FastDFS如何实现文件在不同服务器的同步的,FastDFS是以binglog的格式同步各自上传/修改的文件的,具体位置在安装目录的data/sync目录下,文件一般叫binlog.000这样,以下为我开发机的截图:

具体内容如下:
1589182799 C M00/00/00/rBVrTV65AU-ACKi2AAARqXyG2io334.jpg
1589182885 C M00/00/00/rBVrTV65AaWAAYwKAAARqXyG2io765.jpg
1589427410 C M00/00/00/rBVrTV68vNKAbceuAAARqXyG2io657.jpg
第1列是时间戳,第2列是修改内容,示例中大部分是创建文件,所以是C,其它参考文件 storage/storage_sync.h:
|
1
2
3
4
5
6
7
|
#define STORAGE_OP_TYPE_SOURCE_CREATE_FILE 'C' //upload file#define STORAGE_OP_TYPE_SOURCE_APPEND_FILE 'A' //append file#define STORAGE_OP_TYPE_SOURCE_DELETE_FILE 'D' //delete file#define STORAGE_OP_TYPE_SOURCE_UPDATE_FILE 'U' //for whole file update such as metadata file#define STORAGE_OP_TYPE_SOURCE_MODIFY_FILE 'M' //for part modify#define STORAGE_OP_TYPE_SOURCE_TRUNCATE_FILE 'T' //truncate file#define STORAGE_OP_TYPE_SOURCE_CREATE_LINK 'L' //create symbol link |
有了binglog只是保证不同服务器可以同步数据了,真正实现还有很多东西要考虑:
1、每次是全量还是增量同步,如果是增量,如何记录最后同步的位置,同步的位置做持久化吗;
2、binlog如何保证可靠性,即FastDFS实现的时候是binlog刷磁盘即fsync后才返回给客户端吗;
关于第1点,FastDFS是实现增量同步的,最后位置保存在安装目录的data/sync目录下,扩展名是mark的文件,具体格式是这样的:
172.21.107.236_23000.mark
即 IP_端口.mark。
如果集群中有两个Storage,172.21.104.36, 172.21.104.35,则在36上有1个mark文件:172.21.104.35_23000.mark,而在35上mark文件也只有1个:
172.21.104.36_23000.mark。
mark文件具体内容如下:
binlog_index=0
binlog_offset=3422
need_sync_old=1
sync_old_done=1
until_timestamp=1596511256
scan_row_count=118
sync_row_count=62
关键参数是binlog_offset,即binlog中最后同步成功的偏移量,每同步一个文件后,都会将偏移量更新。
那binlog是异步还是同步将binlog同步给其它的Storage呢,答案是异步,具体可以参考函数:storage_sync_thread_entrance,这个函数是线程的入口,FastDFS在启动时会启动这个线程用来同步:

int storage_sync_thread_start(const FDFSStorageBrief *pStorage)
{
int result;
pthread_attr_t pattr;
pthread_t tid; //省略非关键代码 /*
//printf("start storage ip_addr: %s, g_storage_sync_thread_count=%d\n",
pStorage->ip_addr, g_storage_sync_thread_count);
*/ if ((result=pthread_create(&tid, &pattr, storage_sync_thread_entrance, \
(void *)pStorage)) != 0)
{
logError("file: "__FILE__", line: %d, " \
"create thread failed, errno: %d, " \
"error info: %s", \
__LINE__, result, STRERROR(result)); pthread_attr_destroy(&pattr);
return result;
}
在这个线程中,会周期地读取binlog,然后同步给其它的Storage:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
while (g_continue_flag && (!g_sync_part_time || \ (current_time >= start_time && \ current_time <= end_time)) && \ (pStorage->status == FDFS_STORAGE_STATUS_ACTIVE || \ pStorage->status == FDFS_STORAGE_STATUS_SYNCING)) { //读取binlog read_result = storage_binlog_read(&reader, \ &record, &record_len); //省略非关键代码 } if (read_result != 0) { //省略非关键代码 } else if ((sync_result=storage_sync_data(&reader, \ &storage_server, &record)) != 0) { //上面就是就binlog同步到其它Storage logDebug("file: "__FILE__", line: %d, " \ "binlog index: %d, current record " \ "offset: %"PRId64", next " \ "record offset: %"PRId64, \ __LINE__, reader.binlog_index, \ reader.binlog_offset, \ reader.binlog_offset + record_len); if (rewind_to_prev_rec_end(&reader) != 0) { logCrit("file: "__FILE__", line: %d, " \ "rewind_to_prev_rec_end fail, "\ "program exit!", __LINE__); g_continue_flag = false; } break; } if (reader.last_scan_rows != reader.scan_row_count) { //定稿mark文件 if (storage_write_to_mark_file(&reader) != 0) { logCrit("file: "__FILE__", line: %d, " \ "storage_write_to_mark_file fail, " \ "program exit!", __LINE__); g_continue_flag = false; break; } } |
可以看到,这个线程周期性地调用storage_binlog_read 读取binlog,然后调用storage_sync_data同步给其它Storage,然后调用storage_write_to_mark_file 将mark文件写入到磁盘持久化。
通过上面的分析,可以判断FastDFS在异步情况下是会丢数据的,因为同步binlog给其它Storage是异步的,所以还没同步之前这台机器挂了并且起不来,数据是会丢失的;
另外binlog不是每1次都刷磁盘的,有参数设置,单位为秒:
sync_binlog_buff_interval
即保证多久将将mark文件刷新到磁盘中,果设置大于0,也是会容易丢失数据的。
三、解决方案
回到问题本身,为什么出现数据不同步呢,是因为在搭建 FastDFS的时候,运维的同学直接从其它服务器上拷过来的,包括整个data目录,也包括data下面的sync目录,这样就容易出现mark文件的偏移量不准的问题。
如何解决呢,手动修改mark文件,将binlog_offset设为0,这样FastDFS就会从头同步文件,碰到已经存在的文件,系统会略过的,这是我开发机上的日志:
[2020-08-11 20:27:36] DEBUG - file: storage_sync.c, line: 143, sync data file, logic file: M00/00/00/rBVrTV8yZl6ATOQyAAAJTMk6Vgo7337.md on dest server xx.xx.xx.xx:23000 already exists, and same as mine, ignore it当然前提是日志级别开到DEBUG级别。
PS:
源代码中同步文件成功是没有日志的,写mark文件成功也是没有日志的,为了调试方便,我们都加上相关的调试日志了。
保存mark文件加日志可以在函数storage_write_to_mark_file中加入一条info日志。
if ((result=storage_write_to_fd(pReader->mark_fd, \
get_mark_filename_by_reader, pReader, buff, len)) == 0)
{
pReader->last_scan_rows = pReader->scan_row_count;
pReader->last_sync_rows = pReader->sync_row_count; logInfo("file: "__FILE__", line: %d, " \
"write server:%s mark file success, offset:%d", \
__LINE__, pReader->storage_id, pReader->binlog_offset); }
往期精彩文章:
码字不易,如果觉得这篇文章有帮助,请关注我的个人公众号:

FastDFS不同步怎么破的更多相关文章
- FastDFS文件同步
FastDFS同步相关文件: a)10.100.66.82_23000.mark 内容如下: binlog_index=0 binlog_offset=1334 need_sync_old=1 syn ...
- 360 Atlas生产环境使用心得
一.Atlas介绍 Atlas是360开源的一个Mysql Proxy,以下是官方介绍: Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目 ...
- FastDFS数据迁移
参考:https://blog.csdn.net/frvxh/article/details/56293502 FastDFS安装配置参考:https://www.cnblogs.com/minseo ...
- Linux - 搭建FastDFS分布式文件系统
1. FastDFS简介 说明:FastDFS简介部分的理论知识全部来自于博主bojiangzhou的 <用FastDFS一步步搭建文件管理系统>,在此感谢博主的无私分享.当然最最要感谢的 ...
- FastDFS 注意事项
1.nginx集成FastDFS模块时,配置文件问题 检测到nginx日志: /home/soft/fastdfs-nginx-module/src/common.c, line: 155, loa ...
- Docker部署FastDFS(附示例代码)
1. FastDFS简介 FastDFS是一个开源的分布式文件系统,它对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负载均衡的问题.特别适合以文 ...
- Tapdata Cloud 2.1.5来啦:新增支持Amazon RDS数据库,错误日志查询更便捷,Agent部署细节再优化
需求持续更新,优化一刻不停--Tapdata Cloud 2.1.5 来啦! 最新发布的版本中,数据连接再上新,同时新增任务报错相关信息快速查询入口,开始支持 JVM 参数自定义设置. 更 ...
- Tapdata Cloud 2.1.4 来啦:数据连接又上新,PolarDB MySQL、轻流开始接入,可自动标记不支持的字段类型
需求持续更新,优化一刻不停--Tapdata Cloud 2.1.4 来啦! 最新发布的版本中,在新增数据连接之余,默认标记不支持同步的字段类型,避免因此影响任务的正常运行. 更新速览 ① 数 ...
- Tapdata Cloud 2.1.2 来啦:大波细节已就绪!字段类型可批量修改、支持微信扫码登录、新增支持 Vika 为目标
Tapdata Cloud cloud.tapdata.net 让数据实时可用 Tapdata Cloud 是国内首家异构数据库实时同步云平台,目前支持 Oracle.MySQL.PG.SQL Ser ...
随机推荐
- 2.MongoDB 4.2副本集环境基于时间点的恢复
(一)MongoDB恢复概述 对于任何数据库,如果要将数据库恢复到过去的任意时间点,否需要有过去某个时间点的全备+全备之后的重做日志. 接下来根据瑞丽航空的情况进行概述: 全备:每天晚上都会进行备份: ...
- 谈谈BUG严重级别(severity)管理
在软件工程理论中,BUG严重级别(severity)是用于指示软件质量问题导致的负面影响的程度.但在大部分实际的软件开发组织中,对BUG严重级别(severity)的定义和使用常常充斥着大量的争议和分 ...
- 地图绘制之basemap第一弹 basemap选择与安装
作为一个测绘GIS专业的学生,会有很多绘制地图的需求,一般情况使用ArcGIS.QGIS就可以解决,但是在绘制如论文插图时需要使用更加专业可定制化程度更高的工具,专业传统一般使用GMT,几经比较,最终 ...
- 存储池与存储卷,使用virt-install创建虚拟机
原文链接:https://www.cnblogs.com/zknublx/p/9199658.html 创建存储池 1.建立存储池的目录 mkdir /kvm/images 2.为了安全性,更改目录的 ...
- jdk 功能变化
JDK的变化 JDK1.5 JDK1.6 jdk1.7 1. 添加自动装箱,拆箱 1. =后可以省略泛型, 见ArrayList 2. try后加一个(), 定义流对象,作用域在try里 jdk1 ...
- oracle impdp 数据迁移 至RDS 亚马逊云
背景: 公司年底打算将aws rds11.2.0.4 oracle 数据库升级到19c,所以需要进行升级测试,所以需要我把线上的库数据迁移到一台测试的rds oracle 亚马逊云的数据库中,然后升级 ...
- Selenium使用cookis登录,并临时将cookis存储在本地【shelve数据库】
Python中自带了一个shelve库,可以帮助我们存储一些少量的数据. shelve数据库类似redis,是以[键值对]的方式进行数据的存储,有点像"字典"这种数据结构,存储在本 ...
- Sqli-labs 1-10
Less 1-4(基础注入) 基础知识: table_schema:数据库的名称 table_name:表的名称 column_name:列的名称 information_schema:表示所有信息, ...
- 【原创】如何优雅的转换Bean对象
背景 我们的故事要从一个风和日丽的下午开始说起! 这天,外包韩在位置上写代码-外包韩根据如下定义 PO(persistant object):持久化对象,可以看成是与数据库中的表相映射的 java 对 ...
- 消息队列之-RocketMQ入门
简介 RocketMQ是阿里开源的消息中间件,目前已经捐献个Apache基金会,它是由Java语言开发的,具备高吞吐量.高可用性.适合大规模分布式系统应用等特点,经历过双11的洗礼,实力不容小觑. 官 ...