Scala的安装和配置
1.Windows下搭建Scala开发环境
1)Scala需要Java运行时库,安装Scala需要首先安装JVM虚拟机并配置好,推荐安装JDK1.8
2)在http://www.scala-lang.org/ 下载Scala2.11.8程序安装包

3)配置Jdk的环境变量
4)配置SCALA_HOME,SCALA_HOME= D:\program\scala-2.11.8
5)将Scala安装目录下的bin目录加入到PATH环境变量
6)在PATH变量中添加:%SCALA_HOME%\bin 在终端中输入“scala”命令打开scala解释器

2.Centos7下搭建Scala开发环境
1) 下载RPM包
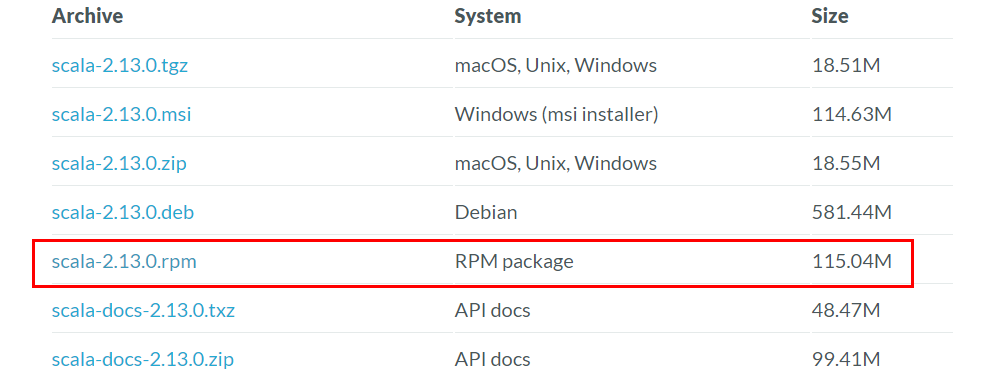
wget https://downloads.lightbend.com/scala/2.13.0/scala-2.13.0.rpm

2)安装Scala的rpm包
sudo rpm -ivh scala-2.13.0.rpm

查看安装结果

测试版本:
[@hadoop-103 software]$ scala -version
Scala code runner version 2.13.0 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
@hadoop-103 software]$ scala
Welcome to Scala 2.13.0 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144).
Type in expressions for evaluation. Or try :help. scala> val i=10
i: Int = 10 scala> val j=20
j: Int = 20 scala> println(s"$i + $j ="+(i+j))
10 + 20 =30
3.IDEA中安装Scala插件
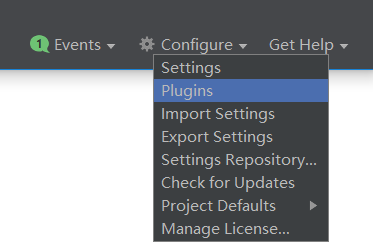
1) 打开IDEA工具,如图:点击Configure

或者: 文件->settings->pulgins 这里也能找到插件安装的位置
2) 点击Plugins
3) 点击Install plugin from disk
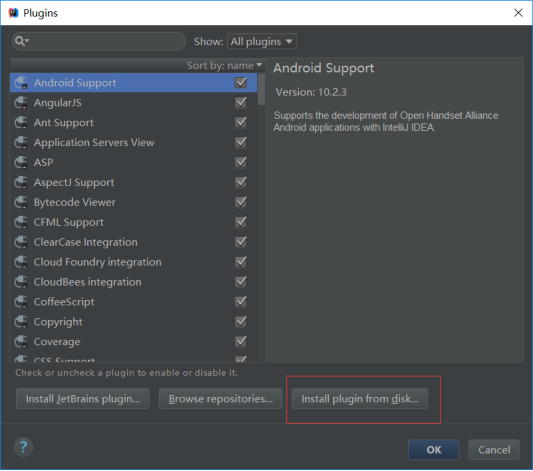
4) 选择scala的plugins

5) 此时会显示一个Scala的条目,在右侧点击Restart IntelliJ IDEA
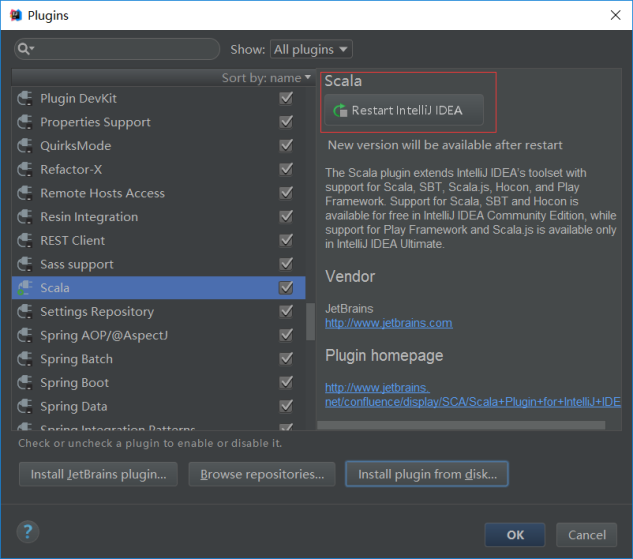
重新启动后, Scala的插件安装成功了!:)
4.在IDEA中创建Scala项目
如这里先创建一个maven项目,默认情况下是没有添加Scala支持的,需要手动添加

选择所安装的Scala
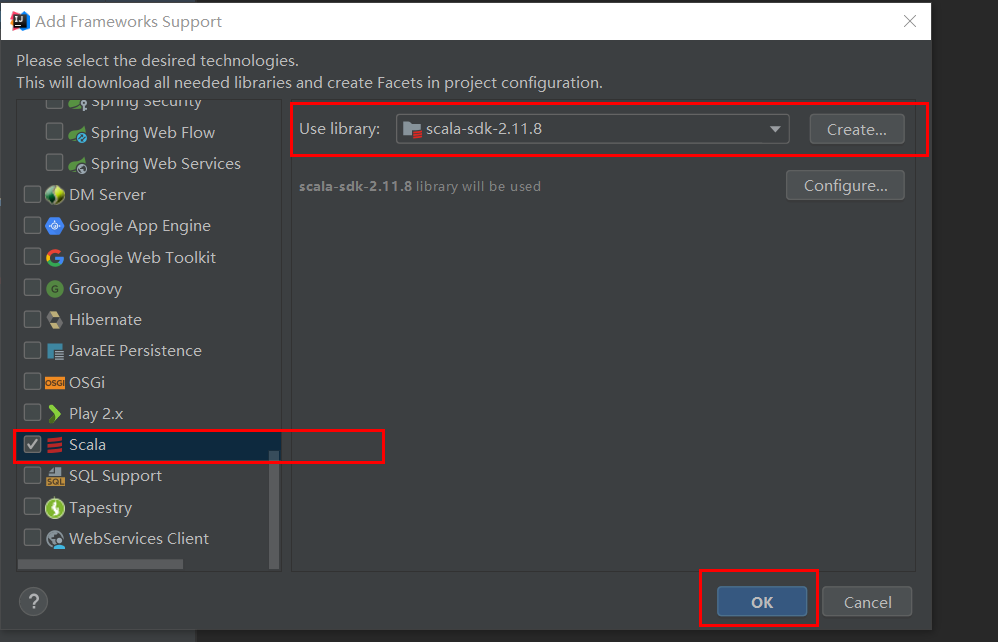
再次查看扩展包就有了Scala支持了

注意:如果所创建的文件夹,没有显示为source文件夹,需要将它设置为source文件夹,设置方法
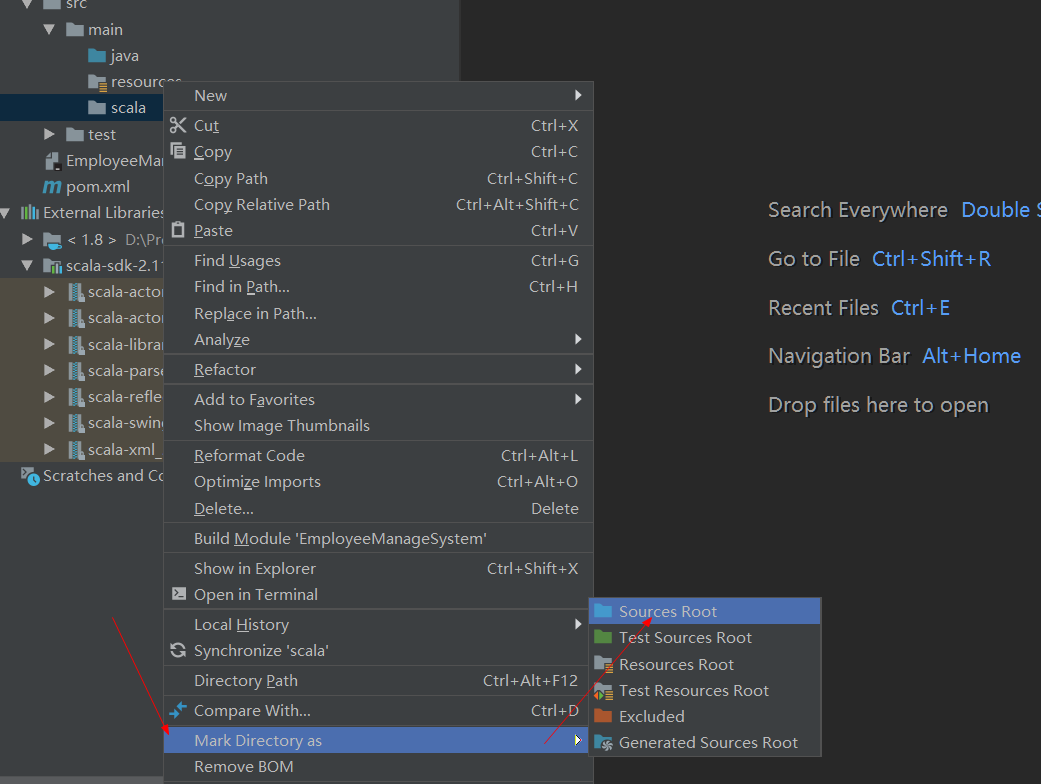
创建一个HelloWorld

package com.bigdata.demo
object HelloWorld {
def main(args: Array[String]): Unit = {
println("helloWorld!!!");
}
}
运行Scala


实际测试发现,不添加Scala支持,只是在maven中配置如下的插件,也是可以运行Scala的
<dependencies>
<dependency>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.2.0</version>
</dependency>
</dependencies>
Scala的安装和配置的更多相关文章
- Scala详细环境安装与配置
https://blog.csdn.net/free356/article/details/72911898 系统为windows.安装配置Scala如下: 一,安装Scala 1,java6以上(建 ...
- Scala 安装与配置
安装准备 由于 Scala 运行于 Java 平台,因此 Scala 之前需要确保系统安装 JDK Windows 中安装 Scala 1. 下载 scala-2.11.2.msi 安装包 点击安装文 ...
- Node.js入门:Node.js&NPM的安装与配置
Node.js安装与配置 Node.js已经诞生两年有余,由于一直处于快速开发中,过去的一些安装配置介绍多数针对0.4.x版本而言的,并非适合最新的0.6.x的版本情况了,对此,我们将在0. ...
- Spark(三): 安装与配置
参见 HDP2.4安装(五):集群及组件安装 ,安装配置的spark版本为1.6, 在已安装HBase.hadoop集群的基础上通过 ambari 自动安装Spark集群,基于hadoop yarn ...
- kafka集群安装与配置
一.集群安装 1. Kafka下载: 可以从kafka官方网站(http://kafka.apache.org)上找到下载地址,再wgetwget http://mirrors.cnnic.cn/ap ...
- 数据库概述、mysql-5.7.11-winx64.zip 的下载、安装、配置和使用(windows里安装)图文详解
本博文的主要内容有 .数据库的概述 .mysql-5.7.11-winx64.zip 的下载 .mysql-5.7.11-winx64.zip 的安装 .mysql-5.7.11-winx64. ...
- Spark安装和配置
hadoop2的安装教程 Spark可以直接安装在hadoop2上面,主要是安装在hadoop2的yarn框架上面 安装Spark之前需要在每台机器上安装Scala,根据你下载的Spark版本,选择对 ...
- Ambari安装之安装并配置Ambari-server(三)
前期博客 Ambari安装之部署本地库(镜像服务器)(二) 安装并配置Ambari-server (1)检查仓库是否可用 [hadoop@ambari01 yum.repos.d]$ pwd /et ...
- Scala的安装,入门,学习,基础
1:Scala的官方网址:http://www.scala-lang.org/ 推荐学习教程:http://www.runoob.com/scala/scala-tutorial.html Scala ...
随机推荐
- Flutter学习笔记(41)--自定义Dialog实现版本更新弹窗
如需转载,请注明出处:Flutter学习笔记(41)--自定义Dialog实现版本更新弹窗 功能点: 1.更新弹窗UI 2.强更与非强更且别控制 3.屏蔽物理返回键(因为强更的时候点击返回键,弹窗会消 ...
- Centos 7下编译安装Mysql
(1)官网下载地址:https://dev.mysql.com/downloads/mysql/ 此处下载的是 mysql-boost-5.7..tar.gz 百度云下载地址:https://pan. ...
- 详解Java的对象创建
1. 前言 在<还不清楚怎样面向对象?>和<面向对象再探究>两篇文章中,都介绍了关于面向对象程序设计的概念和特点.其中也涉及到了许多代码,比如: Dog dog = new D ...
- dp入门例题(1)
按摩师问题 https://leetcode-cn.com/problems/the-masseuse-lcci/ (找好状态转移方程) 今天只和昨天的状态相关,依然是分类讨论: 今天不接受预约:或者 ...
- Qt高级编程 高清PDF+源|网盘下载地址附提取码|
书籍作者:Mark Summerfield(马克 . 萨默菲尔德)(英) 书籍译者:闫锋欣内容简介:本书是一本阐述Qt高级编程技术的书籍.本书以工程实践为主旨,是对Qt现有的700多个类和上百万字 ...
- luogu P4095 [HEOI2013]Eden 的新背包问题 多重背包 背包的合并
LINK:Eden 的新背包问题 就是一个多重背包 每次去掉一个物品 询问钱数为w所能买到的最大值. 可以对于每次Q暴力dp 利用单调队列优化多重背包 这样复杂度是Qnm的. 发现过不了n==10的点 ...
- SSRS - 请求因 HTTP 状态 401 失败: Unauthorized。
原因: 1.SSRS报表服务器停止了,重启就可以了 2.用户没有权限 3.用户登录密码过期了,重设密码就可以了(如果用户是安装了client的话,直接让他远程登录改一下密码)
- 玩转 SpringBoot2.x 之整合邮件发送
序 在实际项目中,经常需要用到邮件通知功能.比如,用户通过邮件注册,通过邮件找回密码等:又比如通过邮件发送系统情况,通过邮件发送报表信息等等,实际应用场景很多. 原文地址:https://www.mm ...
- MyBatis-Plus使用(4)-集成SpringBoot
我这里使用的MyBatis-Plus是当前最新的3.2.0版本, 1. 引入需要的jar,基础jar包括: <dependencies> <dependency> <gr ...
- VisualSVN Server修改默认端口号 443->8443