hadoop完全分布式
虚拟机克隆
a. vim /etc/udev/rules.d/70-persistent-net.rules
更改网卡名

b. vim /etc/sysconfig/network-scripts/ifcfg-eth0
更新网卡
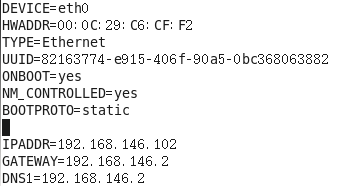
c. vim /etc/sysconfig/network
更改主机名称

d. 配置hosts
vim /etc/hosts
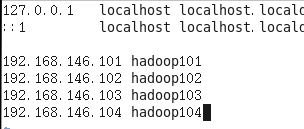
windows主机hosts:C:\Windows\System32\drivers\etc\hosts

e. 重启虚拟机
集群配置
a. 集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
b. 配置集群文件
配置core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property> <!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
配置hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
配置yarn-env.sh
# some Java parameters
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
配置mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
c. ssh无密登录
生成公钥和私钥
cd ~
ssh-keygen -t rsa
公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
注:由于节点间的通讯,hadoop102需要root用户在配置一次,hadoop103普通用户配置一次
群起集群
a. 配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves

脚本同步所有节点配置文件
b. 启动集群
sbin/start-dfs.sh
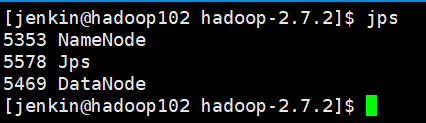
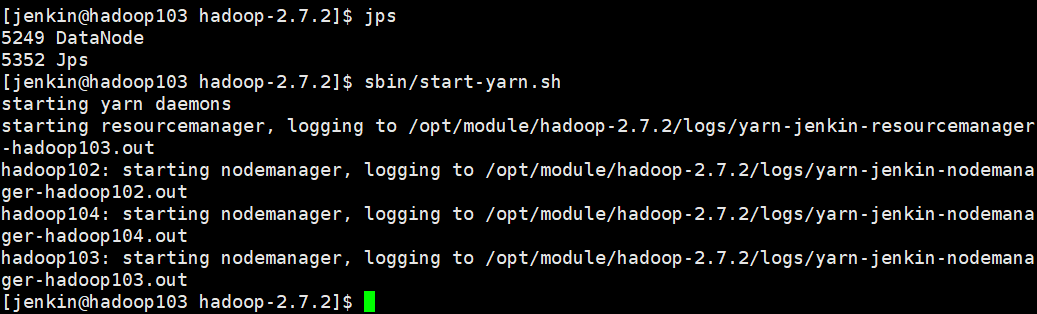
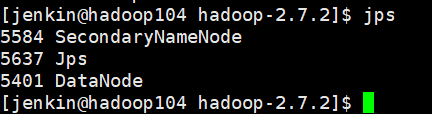
注:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间
时间服务器配置
a. 检查ntp是否安装
rpm -qa | grep ntp

b. 修改ntp配置文件
vim /etc/ntp.conf
修改1(授权192.168.146.0-192.168.146.255网段上的所有机器可以从这台机器上查询和同步时间)
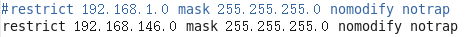
修改2(集群在局域网中,不使用其他互联网上的时间)
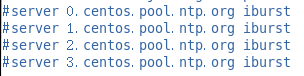
添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
添加在conf文件末尾
server 127.127.1.0
fudge 127.127.1.0 stratum 10
c. 修改/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd
# 让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes
d. 重新启动ntpd服务
service ntpd status
service ntpd start
e. 设置ntpd服务开机启动
chkconfig ntpd on
其他机器配置
a. 在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写内容
*/10 * * * * /usr/sbin/ntpdate hadoop102
b. 修改任意机器时间
date -s "2020-11-11 11:11:11"
c. 十分钟后查看机器是否与时间服务器同步
date
hadoop完全分布式的更多相关文章
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式平台搭建(centos 6.3)
最近要写一个数据量较大的程序,所以想搭建一个hbase平台试试.搭建hbase伪分布式平台,需要先搭建hadoop平台.本文主要介绍伪分布式平台搭建过程. 目录: 一.前言 二.环境搭建 三.命令测试 ...
- [hadoop] hadoop-all-in-one-伪分布式安装
hadoop伪分布式-all-in-one安装 #查看hadoop 版本 [root@hadoop-allinone-200-123 bin]# pwd /wdcloud/app/hadoop-2.7 ...
- Hadoop伪分布式搭建(一)
下面内容主要说明在Windows虚拟机上面,怎么搭建一个Hadoop伪分布式,并如何运行wordcount程序和网页查看HDFS文件系统. 1 相关软件下载和安装 APACH官网提供hadoop版本 ...
- ubuntu下hadoop完全分布式部署
三台机器分别命名为: hadoop-master ip:192.168.0.25 hadoop-slave1 ip:192.168.0.26 hadoop-slave2 ip:192.168.0.27 ...
- Hadoop伪分布式搭建步骤
说明: 搭建环境是VMware10下用的是Linux CENTOS 32位,Hadoop:hadoop-2.4.1 JAVA :jdk7 32位:本文是本人在网络上收集的HADOOP系列视频所附带的 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop完全分布式环境搭建
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三 ...
随机推荐
- 本地代码上传到github
一,注册Github账号 1.先注册一个账号,注册地址:https://github.com/ 2.登录后,点击start a project 3.创建一个repository name,输入框随便取 ...
- Day3 【Scrum 冲刺博客】
每日会议总结 昨天已完成的工作 方晓莹(PIPIYing) 开始人员管理页 搭建与后台对接的相关配置 方子茵(Laa-L) 完成车辆查询接口 黄芯悦(Sheaxx) 完善社区通知页面 完善社区活动页面 ...
- 第三方模块Gulp
1.第三方模块Gulp 基于node平台开发的前端构建工具. 将机械化操作编写成任务,想要执行机械化操作时执行一个命令,命令任务就能自动执行了.提高开发效率. 1)Gulp使用 ① 使用npm ins ...
- elasticsearch的基本了解
以下内容参考官方文档https://www.elastic.co/guide/en/elasticsearch/reference/7.2/elasticsearch-intro.html 使用的学 ...
- 要你命3000会员版v20.03_全球抖音模式
要你命3000是搭配抖音和极其多软件的神器,支持国际版.国内版,可以去除全部限制,无需爬墙,无需拔卡,35个国家/自由切换,真心强大,请务必低调,谢谢合作. 下载地址:https://sansuinb ...
- 使用数据泵,在不知道sys用户密码的情况下导出导入
expdp \"/as sysdba\" directory=my_dir logfile=expdp.log dumpfile=expdp_scott.dmp schemas=s ...
- Spark内核-任务调度机制
作者:十一喵先森 链接:https://juejin.im/post/5e1c414fe51d451cad4111d1 来源:掘金 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. ...
- 《Spring Boot 实战纪实》之关键点文档
目录 前言 (思维篇)人人都是产品经理 1.需求文档 1.1 需求管理 1.2 如何攥写需求文档 1.3 需求关键点文档 2 原型设计 2.1 缺失的逻辑 2.2 让想法跃然纸上 3 开发设计文档 3 ...
- 这嘎哒真TM那啥!Python版东北话编程火爆网络
还记得那个刷爆朋友圈的那个文言文编程语言么? 这个项目是一位名为Huang Lingdong的大四学生创建的,当时,就连中科院计算所研究员.机器翻译领域知名专家刘群老师都赞叹道: 后生可畏 近日,Gi ...
- JavaScript之经典面试题
1.作用域经典面试题 var num = 123; // f1函数写好了,作用域就定下来了,也就是作用域链定下来了 // f1函数作用域链: f1函数作用域 ==> 全局作用域 function ...