hadoop完全分布式
虚拟机克隆
a. vim /etc/udev/rules.d/70-persistent-net.rules
更改网卡名

b. vim /etc/sysconfig/network-scripts/ifcfg-eth0
更新网卡
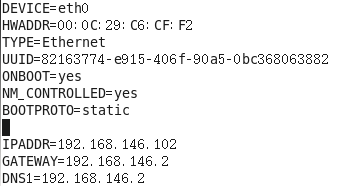
c. vim /etc/sysconfig/network
更改主机名称

d. 配置hosts
vim /etc/hosts
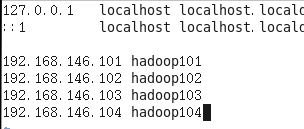
windows主机hosts:C:\Windows\System32\drivers\etc\hosts

e. 重启虚拟机
集群配置
a. 集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
b. 配置集群文件
配置core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property> <!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
配置hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
配置yarn-env.sh
# some Java parameters
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
配置mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
c. ssh无密登录
生成公钥和私钥
cd ~
ssh-keygen -t rsa
公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
注:由于节点间的通讯,hadoop102需要root用户在配置一次,hadoop103普通用户配置一次
群起集群
a. 配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves

脚本同步所有节点配置文件
b. 启动集群
sbin/start-dfs.sh
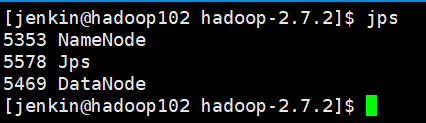
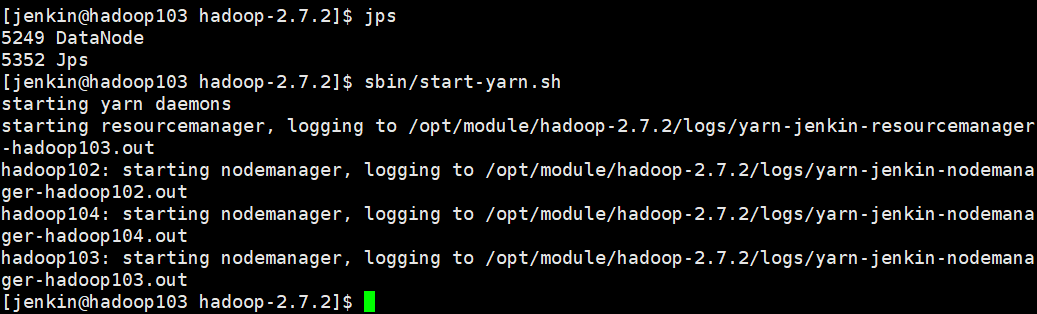
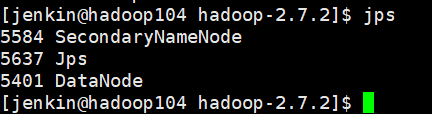
注:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间
时间服务器配置
a. 检查ntp是否安装
rpm -qa | grep ntp

b. 修改ntp配置文件
vim /etc/ntp.conf
修改1(授权192.168.146.0-192.168.146.255网段上的所有机器可以从这台机器上查询和同步时间)
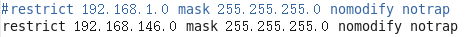
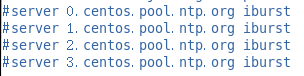
修改2(集群在局域网中,不使用其他互联网上的时间)
添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
添加在conf文件末尾
server 127.127.1.0
fudge 127.127.1.0 stratum 10
c. 修改/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd
# 让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes
d. 重新启动ntpd服务
service ntpd status
service ntpd start
e. 设置ntpd服务开机启动
chkconfig ntpd on
其他机器配置
a. 在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写内容
*/10 * * * * /usr/sbin/ntpdate hadoop102
b. 修改任意机器时间
date -s "2020-11-11 11:11:11"
c. 十分钟后查看机器是否与时间服务器同步
date
hadoop完全分布式的更多相关文章
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式平台搭建(centos 6.3)
最近要写一个数据量较大的程序,所以想搭建一个hbase平台试试.搭建hbase伪分布式平台,需要先搭建hadoop平台.本文主要介绍伪分布式平台搭建过程. 目录: 一.前言 二.环境搭建 三.命令测试 ...
- [hadoop] hadoop-all-in-one-伪分布式安装
hadoop伪分布式-all-in-one安装 #查看hadoop 版本 [root@hadoop-allinone-200-123 bin]# pwd /wdcloud/app/hadoop-2.7 ...
- Hadoop伪分布式搭建(一)
下面内容主要说明在Windows虚拟机上面,怎么搭建一个Hadoop伪分布式,并如何运行wordcount程序和网页查看HDFS文件系统. 1 相关软件下载和安装 APACH官网提供hadoop版本 ...
- ubuntu下hadoop完全分布式部署
三台机器分别命名为: hadoop-master ip:192.168.0.25 hadoop-slave1 ip:192.168.0.26 hadoop-slave2 ip:192.168.0.27 ...
- Hadoop伪分布式搭建步骤
说明: 搭建环境是VMware10下用的是Linux CENTOS 32位,Hadoop:hadoop-2.4.1 JAVA :jdk7 32位:本文是本人在网络上收集的HADOOP系列视频所附带的 ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop完全分布式环境搭建
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三 ...
随机推荐
- anaconda 配置虚拟环境
工作时有时候会遇到不同版本的问题,比如深度学习tensorflow 1.14版本 和 2.0版本,或者cpu版本和gpu版本,那么这个时候建立虚拟环境就很方便了 anaconda命令行下 1) act ...
- 手把手教你写DI_3_小白徒手支持 `Singleton` 和 `Scoped` 生命周期
手把手教你写DI_3_小白徒手支持 Singleton 和 Scoped 生命周期 在上一节:手把手教你写DI_2_小白徒手撸构造函数注入 浑身绷带的小白同学:我们继续开展我们的工作,大家都知道 Si ...
- 【游记】CSp2020
同步发表于洛谷博客 初赛 Day -2 做了个模拟(非洛谷),只有一丁点分,显然过不了 (盗张 i am ak f 的图) Day 0 颓,颓,颓,又做了一套模拟,坚定了退役的信心. Day 1 人好 ...
- 五、git学习之——分支管理策略、Bug分支、feature分支、多人协作
一.分支管理策略 通常,合并分支时,如果可能,Git会用Fast forward模式,但这种模式下,删除分支后,会丢掉分支信息. 如果要强制禁用Fast forward模式,Git就会在merge时生 ...
- Angular:使用service进行数据的持久化设置
①使用ng g service services/storage创建一个服务组件 ②在app.module.ts 中引入创建的服务 ③利用本地存储实现数据持久化 ④在组件中使用
- 事件修饰符 阻止冒泡 .stop 阻止默认事件 .prevent
stop修饰符 阻止冒泡行为 可以在函数中利用$event传参通过stopPropagation()阻止冒泡 通过直接在元素中的指令中添加 .stop prevent修饰符 阻止默认行为 可以在函数中 ...
- Java中instanceof注意的地方
instanceof只能用于对象的判断,不能用于基本类型的判断,以下代码会编译不通过 'A' instanceof Character instanceof特有的规则:若左操作数是null,结果就直接 ...
- iOS崩溃治理--开篇
去年我开始负责iOS崩溃治理的工作,从原来的万分之五崩溃率,一直到现在的万分之一左右的崩溃率,期间踩了很多坑,因此想和大家分享一下,希望能对大家有所帮助,也欢迎大家私信交流. 如果你打算开始治理崩溃的 ...
- 深入浅出JVM(一):你写得.java文件是如何被加载到内存中执行的
众所周知,.java文件需要经过编译生成.class文件才能被JVM执行. 其中,JVM是如何加载.class文件,又做了些什么呢? .class文件通过 加载->验证->准备->解 ...
- Android基础工具移植说明
早前开展的计划因各种杂事而泡汤,而当遇到了具体任务后,在压力下花了两个多周的业余时间把这件事完成了. 这就是我的引以为傲的Mercury-Project,它的核心目标是移植一些Android底层轮子到 ...