Mybatis的二级缓存、使用Redis做二级缓存
什么是二级缓存?
二级缓存和一级缓存的原理是一样的,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于的sqlSession,而二级缓存是基于mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如何两个mapper的namespace相同,即使两个mapper,那这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中
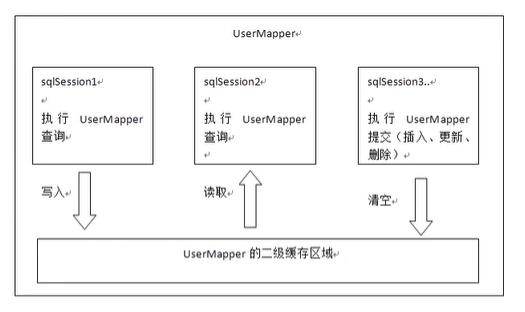
- 如上图
sqlSession1在查询时会从UserMapper的二级缓存中取,如果没有则执行数据库查询操作。 - 然后写入到二级缓存中
sqlSession2则执行同样的UserMapper查询时,会从UserMapper的二级缓存中取,此时的二级缓存中已经有内容了,所以就可以直接取到,不再与数据库交互。sqlSession3在执行事务操作(插入、更新、删除)时,会清空UserMapper的二级缓存
1. 开启二级缓存
如何使用二级缓存:
mybatis中,一级缓存是默认开启的,但是二级缓存需要配置才可以使用
在全局配置文件
sqlMapConfig.xml中加入如下代码:<!--开启二级缓存-->
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
其次在哪个namespace中开启二级就在哪里配置,因为mybatis有注解和xml两种方式所以:
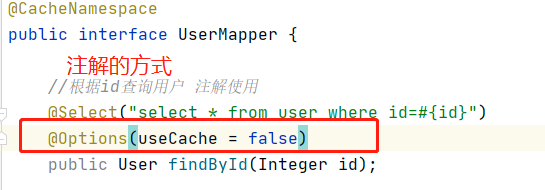
注解
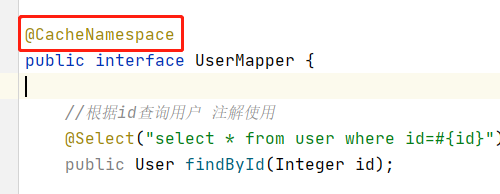
注解扩展://我们默认使用的是mybatis自带的二级缓存,它的实现在PerpetualCache类中,所以可以写成
@CacheNamespace(implementation = PerpetualCache.class)
//如果是使用redis作为二级缓存的话,下面第二部分会讲到
xml
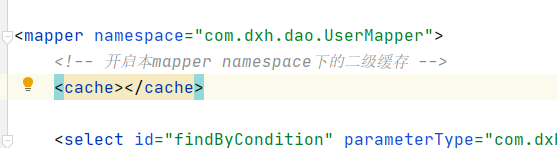
这样就开启了UserMapper的二级缓存
测试一:
我们要根据用户id查询用户信息:

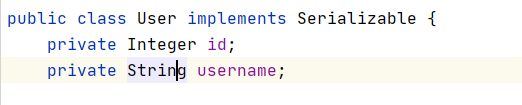
注意:将缓存的pojo实现
Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存的存储介质多种多样,不一定只在内存中,也可能在硬盘中,如果我们要再取出这个缓存的话,就需要反序列化了。所以mybatis的pojo都去实现Serializable接口
最后执行看到打印日志:
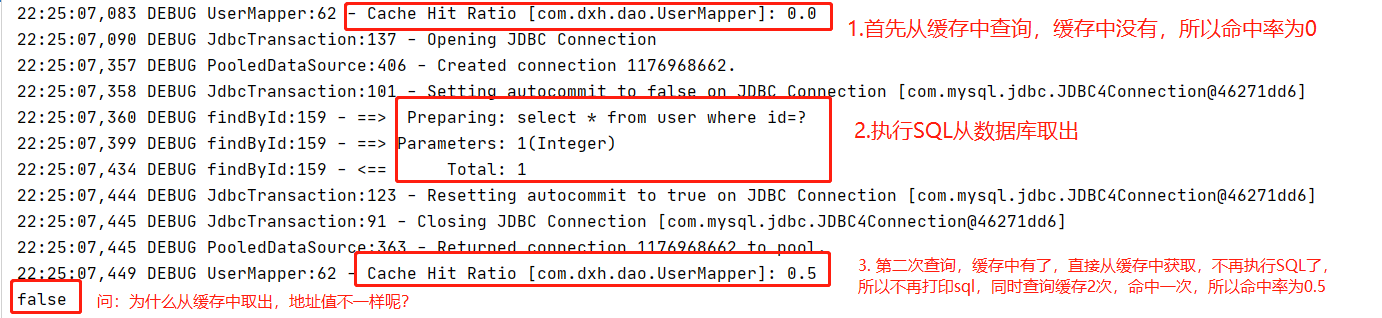
为什么System.out.println(user1==user2)为false ?二级缓存和一级缓存不同,二级缓存缓存的不是对象,而是数据,在第二次查询时底层重新创建了一个User对象,并且把二级缓存中的数据重新封装成了对象并返回。所以user1和user2不是一个对象。
测试二:
我们在测试二中进行一下事务操作,看看是否能清空二级缓存:
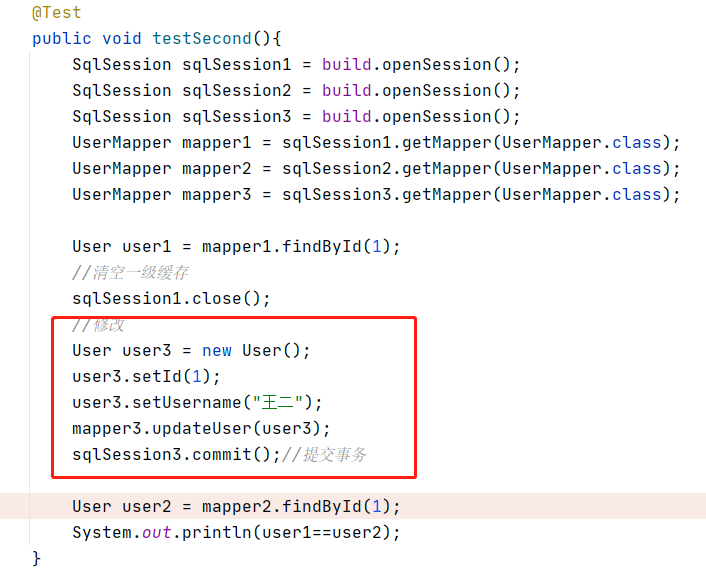
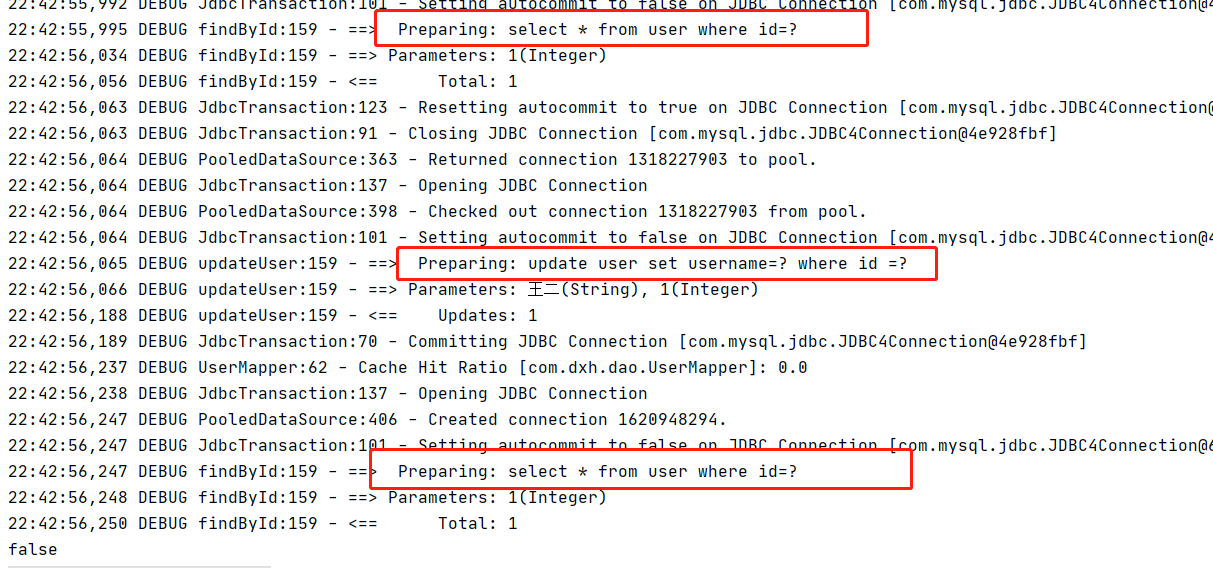
增加了一个修改操作,发现执行了两个select,说明提交事务会刷新二级缓存
userCache和flushCache
还可以配置userCache和flushCache
userCache : 是用来设置是否禁用二级缓存的,在statement中设置可以禁用当前select语句的二级缓存,即每次查询都会发出sql。默认情况为true.
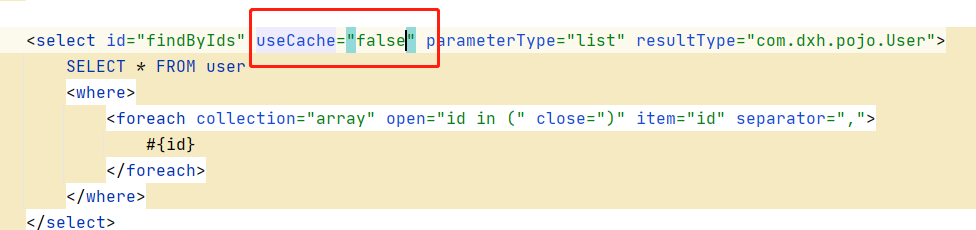
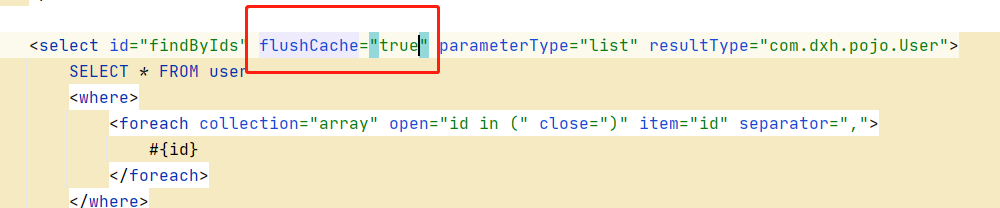
flushCache : 在mapper的同一个namespace中,如果有其它的增删改操作后需要刷新缓存,如果部执行刷新缓存会出现脏读。
设置statement配置中的flushCache="true",即刷新缓存,如果改成false则不会刷新,有可能出现脏读。所以一般情况下没必要改
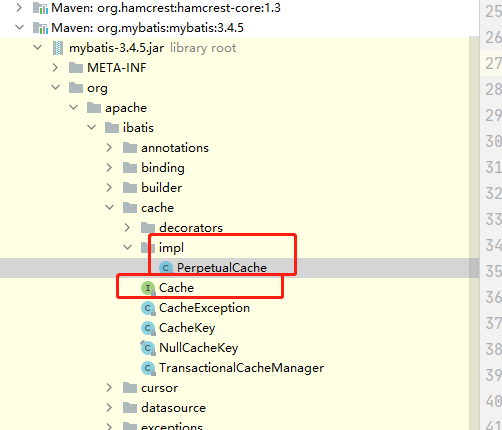
Mybatis二级缓存和一级缓存一样也是使用到了
org.apache.ibatis.cache.impl.PerpetualCache这个类是mybatis的默认缓存类,同时,想要自定义缓存必须实现
cache接口
2. 使用Redis实现二级缓存
Mybatis自带的二级缓存是有缺点的,就是这个缓存是单服务器进行工作的,无法实现分布式缓存。
所以为了解决这个问题,必须找一个分布式缓存专门存放缓存数据。
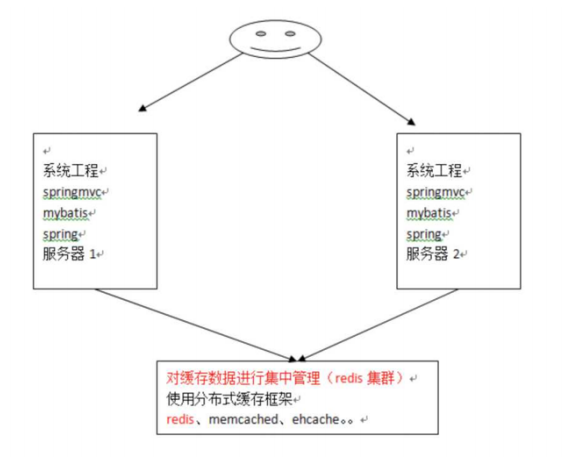
如何使用
mybatis提供了一个针对cache接口的redis实现类,在mybatis-redis包中
首先我们引入jar包
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
修改Mapper.xml文件
//**********XML方式***********:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lagou.mapper.IUserMapper">
//表示针对于当前的namespace开启二级缓存
<cache type="org.mybatis.caches.redis.RedisCache" /> <select id="findAll" resultType="com.lagou.pojo.User" useCache="true">
select * from user
</select>
//*******注解方式**********
@CacheNamespace(implementation = RedisCache .class)
public interface UserMapper {
//根据id查询用户 注解使用
@Select("select * from user where id=#{id}")
public User findById(Integer id);这个类同样实现了
Cache接口
配置redis的配置文件
redis.host=localhost
redis.port=6379
redis.connectionTimeout=5000
redis.password=
redis.database=0
测试方法同自带的二级缓存一样。
3. Redis二级缓存源码分析
RedisCache和Mybatis二级缓存的方案都差不多,无非是实现Cache接口,并使用jedis操作缓存,不过在设计细节上有点区别。
我们带着问题分析源码:
- 在RedisCache类中如何向redis中进行缓存值的存取 ?
- 使用了哪种数据结构 ?
package org.mybatis.caches.redis;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import org.apache.ibatis.cache.Cache;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
//首先其实现了Cache接口,被mybatis初始化的时候的CacheBuilder创建
//创建方式就是调用了下面的有参构造
public final class RedisCache implements Cache {
private final ReadWriteLock readWriteLock = new DummyReadWriteLock();
private String id;
private static JedisPool pool;
//有参构造
public RedisCache(final String id) {
if (id == null) {
throw new IllegalArgumentException("Cache instances require an ID");
}
this.id = id;
//RedisConfigurationBuilder调用parseConfiguration()方法创建RedisConfig对象
RedisConfig redisConfig = RedisConfigurationBuilder.getInstance().parseConfiguration();
//构建Jedis池
pool = new JedisPool(redisConfig, redisConfig.getHost(), redisConfig.getPort(),
redisConfig.getConnectionTimeout(), redisConfig.getSoTimeout(), redisConfig.getPassword(),
redisConfig.getDatabase(), redisConfig.getClientName());
}
//模板方法,下面的putObject和getObject、removeObject都会用到这个方法
private Object execute(RedisCallback callback) {
Jedis jedis = pool.getResource();
try {
return callback.doWithRedis(jedis);
} finally {
jedis.close();
}
}
//。。。。。。。。省略部分代码
@Override
public void putObject(final Object key, final Object value) {
execute(new RedisCallback() {
@Override
public Object doWithRedis(Jedis jedis) {
jedis.hset(id.toString().getBytes(), key.toString().getBytes(), SerializeUtil.serialize(value));
return null;
}
});
}
@Override
public Object getObject(final Object key) {
return execute(new RedisCallback() {
@Override
public Object doWithRedis(Jedis jedis) {
return SerializeUtil.unserialize(jedis.hget(id.toString().getBytes(), key.toString().getBytes()));
}
});
}
@Override
public Object removeObject(final Object key) {
return execute(new RedisCallback() {
@Override
public Object doWithRedis(Jedis jedis) {
return jedis.hdel(id.toString(), key.toString());
}
});
}
}
RedisConfig redisConfig = RedisConfigurationBuilder.getInstance().parseConfiguration();

RedisConfig中封装了默认的Redis配置信息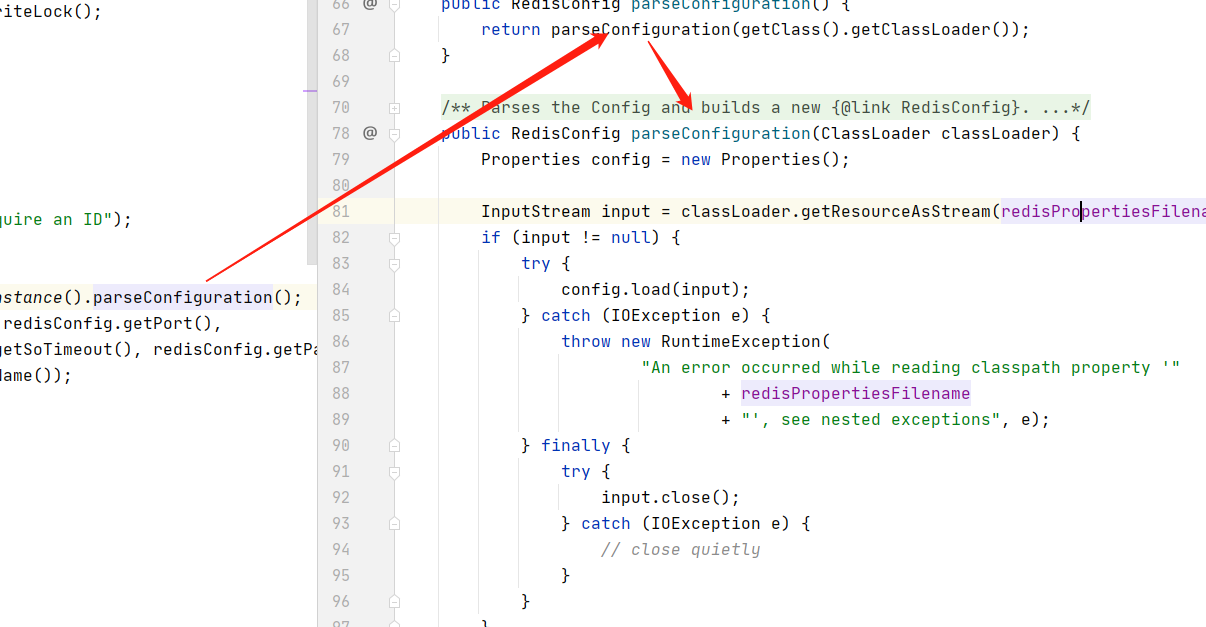
这个方法读取了我们配置在/resource/redis.properties这个文件
RedisConfig后构建了Jedis池put方法
private Object execute(RedisCallback callback) {
Jedis jedis = pool.getResource();
try {
return callback.doWithRedis(jedis);
} finally {
jedis.close();
}
} public void putObject(final Object key, final Object value) {
execute(new RedisCallback() {
@Override
public Object doWithRedis(Jedis jedis) {
jedis.hset(id.toString().getBytes(), key.toString().getBytes(), SerializeUtil.serialize(value));
return null;
}
});
}
我们可以看到,put方法调用了模板方法得到 一个jedis链接,然后调用doWithRedis()方法
jedis.hset(id.toString().getBytes(), key.toString().getBytes(), SerializeUtil.serialize(value));
可以很清楚的看到,mybatis-redis在存储数据的时候,是使用的hash结构,把cache的id作为这个hash的key (cache的id在mybatis中就是mapper的namespace);这个mapper中的查询缓存数据作为 hash的field,需要缓存的内容直接使用SerializeUtil存储,SerializeUtil和其他的序列化类差不多,负责对象的序列化和反序列化;
Mybatis的二级缓存、使用Redis做二级缓存的更多相关文章
- SSM+redis整合(mybatis整合redis做二级缓存)
SSM:是Spring+Struts+Mybatis ,另外还使用了PageHelper 前言: 这里主要是利用redis去做mybatis的二级缓存,mybaits映射文件中所有的select都会刷 ...
- spring boot:使用caffeine+redis做二级缓存(spring boot 2.3.1)
一,为什么要使用二级缓存? 我们通常会使用caffeine做本地缓存(或者叫做进程内缓存), 它的优点是速度快,操作方便,缺点是不方便管理,不方便扩展 而通常会使用redis作为分布式缓存, 它的优点 ...
- Spring Boot使用redis做数据缓存
1 添加redis支持 在pom.xml中添加 <dependency> <groupId>org.springframework.boot</groupId> & ...
- Redis做为缓存的几个问题
缓存理流程: 前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果. 1.缓存雪崩 解决方案3:如果缓存数据库是分布 ...
- web性能优化之--合理使用http缓存和localStorage做资源缓存
一.前言 开始先扯点别的: 估计很多前端er的同学应该遇到过:在旧项目中添加新的功能模块.或者修改一些静态文件时候,当代码部署到线上之后,需求方验收OK,此时你送了一口气,当你准备开始得意于自己的ma ...
- Redis做LRU缓存
当Redis用作缓存时,通常可以让它在添加新数据时自动逐出旧数据. 这种行为在开发人员社区中非常有名,因为它是流行的memcached系统的默认行为. LRU实际上只是支持的驱逐方法之一. 本页介绍了 ...
- 使用redis做mysql缓存
应用Redis实现数据的读写,同时利用队列处理器定时将数据写入mysql. 同时要注意避免冲突,在redis启动时去mysql读取所有表键值存入redis中,往redis写数据时,对redis主键自增 ...
- spring-boot-route(十二)整合redis做为缓存
redis简介 redis作为一种非关系型数据库,读写非常快,应用十分广泛,它采用key-value的形式存储数据,value常用的五大数据类型有string(字符串),list(链表),set(集合 ...
- redis 做为缓存服务器 注项!
作为缓存服务器,如果不加以限制内存的话,就很有可能出现将整台服务器内存都耗光的情况,可以在redis的配置文件里面设置: # maxmemory <bytes> #限定最多使用1.5GB内 ...
随机推荐
- 加快ASP。NET Core WEB API应用程序。第3部分
下载source from GitHub 对ASP进行深度重构和优化.NET Core WEB API应用程序代码 介绍 第1部分.创建一个测试的RESTful WEB API应用程序. 第2部分.增 ...
- List移除另外一个list的时候报错,java.lang.UnsupportedOperationException
问题 编写代码的时候,使用Mybatis-plus分页查询返回的list,移除自己new的ArrayList报错 根据异常信息,发现mybatis-plus分页查询返回的list底层并没有实现remo ...
- antd pro 路由
概要 antd pro 路由简介 路由, 菜单和面包屑 页面之间的路由 带参数的路由 总结 概要 路由配置是单页应用的核心之一, antd pro 将所有的路由配置集中在一个文件中, 可以更好的对应用 ...
- 多测师讲解自动化测试 _RF分配id_高级讲师肖sir
1.Assign Id To Element.
- MeteoInfoLab脚本示例:inpolygon
inpollygon函数是用来判断带坐标(x/y)的数据是否在某个或者一组多边形(Polygon)中,返回的结果中如果做多边形内则值为1,否则值为-1.下面一个例子演示了利用一个shape文件和inp ...
- ScanTailor-ScanTailor 强大的多方位的满足处理扫描图片的需求
ScanTailor 强大的多方位的满足处理扫描图片的需求 ScanTailor 能做什么? 批量或单张或选择区间旋转图片 自动切割页面,同时提供手动选项 自动识别图像歪斜角度,同时提供手动选项 ...
- centos8安装zookeeper(单机方式)
一,下载zookeeper: 1,官网地址 http://zookeeper.apache.org/ 找到这个地址: https://mirrors.tuna.tsinghua.edu.cn/apac ...
- php 反射 实例化类
<?php class Person { public $name; public $sex; public function __construct($name,$sex=1) { $this ...
- 第十九章 DHCP原理介绍
一.为什么使用DHCP 1.手动为局域网中大量主机配置IP地址.掩码.网关等参数的工作繁琐,容易出错 2.DHCP可以自动为局域网中主机完成TCP/IP协议配置 3.DHCP自动配置避免了IP地址冲突 ...
- 2. A Distributional Perspective on Reinforcement Learning
本文主要研究了分布式强化学习,利用价值分布(value distribution)的思想,求出回报\(Z\)的概率分布,从而取代期望值(即\(Q\)值). Q-Learning Q-Learning的 ...