kafka项目经验之如何进行Kafka压力测试、如何计算Kafka分区数、如何确定Kaftka集群机器数量
@
Kafka压测
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈==(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。 ==
使用下面两个kafka自带的脚本
kafka-consumer-perf-test.shkafka-producer-perf-test.sh
Kafka Producer(生产)压力测试
进入kafka的安装目录,执行下面的命令
[sun@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
说明:
record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。throughput是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。
输出:
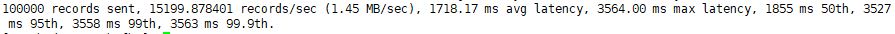
参数解析:本例中一共写入10w条消息,吞吐量为1.45 MB/sec,每次写入的平均延迟为1718.17毫秒,最大的延迟为3564.00毫秒。
Kafka Consumer(消费)压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
进入kafka的安装目录,执行下面的命令
[sun@hadoop102 kafka]$ bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
参数说明:
--zookeeper 指定zookeeper的链接信息
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
输出:

start.time开始时间:2021-01-27 13:55:20:963end.time结束时间:2021-01-27 13:55:36:555data.consumed.in.MB共消费数据:22.1497MBMB.sec吞吐量:1.4206MB/secdata.consumed.in.nMsg共消费消息条数:232256条nMsg.sec平均每秒消费条数:14895.8440条
计算Kafka分区数
- 创建一个只有1个分区的topic
- 测试这个topic的producer吞吐量(1.45m/s)和consumer吞吐量(1.42m/s)。数据来自上面的压测
- 假设他们的值分别是Tp和Tc,单位可以是MB/s。 4)然后假设你期望的目标吞吐量是Tt(10m/s),那么分区数=Tt /min(Tp,Tc) ,这里取最小值是因为使最低的吞吐量都能达到期望的吞吐量。
- 例如:producer吞吐量=20m/s;consumer吞吐量=50m/s,期望吞吐量100m/s;
- 分区数=100 / 20 =5分区 5)分区数一般设置为:3-10个
Kafka机器数量计算
- Kafka机器数量(经验公式)=2 (峰值生产速度副本数/100)+1
- 先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。 副本数默认是1个
- 在企业里面2-3个都有,2个居多。
- 比如我们的峰值生产速度是50M/s(一般不超过50M/s)。生产环境可以设置为2。 Kafka机器数量=2(502/100)+1=3台
- 副本多可以提高可靠性,但是会降低网络传输效率。
kafka项目经验之如何进行Kafka压力测试、如何计算Kafka分区数、如何确定Kaftka集群机器数量的更多相关文章
- 项目经验——Sql server 数据库的备份和还原____还原数据库提示“介质集有2个介质簇,但只提供了1个。必须提供所有成员” .
在对数据库备份与还原的过程中,我遇到一个问题“介质集有2个介质簇,但只提供了1个.必须提供所有成员”,下面详细的介绍一下遇到问题的经过与问题解决的方法! 一.备份与还原遇到的问题描述与解决方法: 前两 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- Spark集群 + Akka + Kafka + Scala 开发(3) : 开发一个Akka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- Centos安装Kafka集群
kafka是LinkedIn开发并开源的一个分布式MQ系统,现在是Apache的一个孵化项目.在它的主页描述kafka为一个高吞吐量的分布式(能 将消息分散到不同的节点上)MQ.在这片博文中,作者简单 ...
- 4 kafka集群部署及kafka生产者java客户端编程 + kafka消费者java客户端编程
本博文的主要内容有 kafka的单机模式部署 kafka的分布式模式部署 生产者java客户端编程 消费者java客户端编程 运行kafka ,需要依赖 zookeeper,你可以使用已有的 zo ...
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- 生产环境一键创建kafka集群
前段时间公司的一个kafka集群出现了故障,由于之前准备不足,当时处理的比较慌乱.如:由于kafka的集群里topic数量较多,并且每个topic的分区数量和副本数量都不是一样的,如果按部就班的一个一 ...
- kafka集群及监控部署
1. kafka的定义 kafka是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础 ...
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
随机推荐
- 关于AES-CBC模式字节翻转攻击(python3)
# coding:utf-8 from Crypto.Cipher import AES import base64 def encrypt(iv, plaintext): if len(plaint ...
- yii2 设置的缓存无效,返回false,不存在
为了那些因为标题点进来的小伙伴,我直接把问题解决方案写在开头: 问题描述, $cache->add($key,'value',1800);这样设置了值后,后面无论怎么取这个$key,取出来的结果 ...
- EF Core扩展工具记录 批量操作 记录修改删除历史 动态linq
Microsoft.EntityFrameworkCore.UnitOfWork Microsoft.EntityFrameworkCore的插件,用于支持存储库,工作单元模式以及支持分布式事务 ...
- mysql数据安全之利用二进制日志mysqlbinlog恢复数据
mysql数据安全之利用二进制日志mysqlbinlog恢复数据 简介:如何利用二进制日志来恢复数据 查看二进制日志文件的内容报错: [root@xdclass-public log_bin]# my ...
- 记录第一次使用Vivado——以全加器为例子
从altera转战xilinx,经典的FPGA到ZYNQ系列,第一站就是先熟悉编译软件Vivado.我就直接跳过软件安装部分了,如有疑问,可以在评论区提出来,我看到了就帮你解答. 首先是是打开界面 然 ...
- 根据租户id获取部门树状结构有父子结构的数据list
/** * 根据租户id获取部门树状结构 * @param tenantId * @return */ @GetMapping("getDeptTreeList") public ...
- 如何实现Application event,观察者模式
spring 事件为bean 与 bean之间传递消息.一个bean处理完了希望其余一个接着处理.这时我们就需要其余的一个bean监听当前bean所发送的事件. spring事件使用步骤如下: 1.先 ...
- 云计算之4---Cockpit
cockpit是一个简单可用的监控工具,你可以添加多个主机进行监控,上限是20台 .也可以使用cockpit来管理虚拟机/容器,也可以安装其他组件开启更多功能. 注意:cockpit没有告警功能,不适 ...
- 【ASP.NET Core】Blazor 服务器端的 Base Path
提到 Blazor,没准就会有人问:选用 Server 端还是 WebAssembly(客户端)?其实这个不用纠结,老周个人的原则是:Server 端优先.理由很单纯:服务器端虽然消耗服务器上的资源, ...
- 【机制】JavaScript的原型、原型链、继承
1.原型和原型链的概念 js在创建一个对象时,比如叫 obj,都会给他偷偷的加上一个引用,这个引用指向的是一个对象,比如叫 yuanxing, 这个对象可以给引用它的对象提供属性共享,比如:yuanx ...