使用tensorflow2识别4位验证码及思考总结
在学习了CNN之后,自己想去做一个验证码识别,网上找了很多资料,杂七杂八的一大堆,但是好多是tf1写的,对tf1不太熟悉,有点看不懂,于是自己去摸索吧。
摸索的过程是异常艰难呀,一开始我直接用captcha 生成了10080张验证码去识别,发现loss一直停留在2.3左右,accuracy一直是0.1左右,训练了100回合,也没啥变化,电脑都快要跑废了,咋办呀,于是网上各种问大佬,找到机会就发问,说我识别验证码出现的问题,其中一位大佬对我的问题很有帮助,感谢魏巍老师。
下面就是我寻找问题答案的每一步:
第一回
网络结构的搭建:
model=tf.keras.models.Sequential([
tf.keras.Input(shape=(H, W, C)),
layers.Conv2D(, , activation='relu'),
layers.MaxPooling2D((, )),
layers.Conv2D(, , activation='relu'),
layers.MaxPooling2D((, )),
layers.Conv2D(, , activation='relu'),
layers.MaxPooling2D((, )),
layers.Conv2D(, , activation='relu'),
layers.MaxPooling2D((, )),
layers.Conv2D(, , activation='relu'),
layers.MaxPooling2D((, )),
layers.Flatten(),
layers.Dense(, activation='relu'),
layers.Dense(D * N_LABELS, activation='softmax'),
layers.Reshape((D, N_LABELS)),
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics= ['accuracy']) callbacks=[
tf.keras.callbacks.TensorBoard(log_dir='logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=check_point_path,
save_weights_only=True,
save_best_only=True)
]
history = model.fit(train_gen,
steps_per_epoch=len(train_idx)//batch_size,
epochs=,
callbacks=callbacks,
validation_data=valid_gen,
validation_steps=len(valid_idx)//valid_batch_size)
summary:

我的训练数据量:train count: 7408, valid count: 3176, test count: 4536,
样本图:
 ,
, ,
,
训练结果:
Train for 231 steps, validate for 99 steps
Epoch 1/100
1/231 […] - ETA: 4:18 - loss: 2.2984 - accuracy: 0.1328
231/231 [==============================] - 143s 618ms/step - loss: 2.3032 - accuracy: 0.0971 - val_loss: 2.3029 - val_accuracy: 0.0987
Epoch 2/100
230/231 [============================>.] - ETA: 0s - loss: 2.3026 - accuracy: 0.1014
231/231 [==============================] - 121s 525ms/step - loss: 2.3026 - accuracy: 0.1013 - val_loss: 2.3031 - val_accuracy: 0.0986
Epoch 3/100
230/231 [============================>.] - ETA: 0s - loss: 2.3026 - accuracy: 0.1029
231/231 [==============================] - 138s 597ms/step - loss: 2.3026 - accuracy: 0.1026 - val_loss: 2.3032 - val_accuracy: 0.0986
Epoch 4/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1031
231/231 [==============================] - 124s 537ms/step - loss: 2.3025 - accuracy: 0.1031 - val_loss: 2.3032 - val_accuracy: 0.0987
Epoch 5/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1040
231/231 [==============================] - 123s 532ms/step - loss: 2.3025 - accuracy: 0.1039 - val_loss: 2.3032 - val_accuracy: 0.0989
Epoch 6/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1039
231/231 [==============================] - 118s 509ms/step - loss: 2.3025 - accuracy: 0.1038 - val_loss: 2.3033 - val_accuracy: 0.0988
…
Epoch 20/100
230/231 [============================>.] - ETA: 0s - loss: 2.3025 - accuracy: 0.1038
231/231 [==============================] - 120s 521ms/step - loss: 2.3025 - accuracy: 0.1038 - val_loss: 2.3034 - val_accuracy: 0.0988
Epoch 21/100
190/231 [=======================>…] - ETA: 20s - loss: 2.3025 - accuracy: 0.1032
loss 一直没有变化,accuracy 也很低,不知道出现了什么原因,困扰一两个星期呀,都想要放弃了,太难了。。。。
但是我不死心呀,非要把它搞出来,咋搞呢,4位识别不出来,能不能先识别一位呢?好,那就开始搞,一位比较简单,跟Mnist 数据集很相似,在这我就不详细了。
第二回
接着来识别2位的验证码,
train count: 441, valid count: 189, test count: 270,
样本图:
 ,
, ,
,
下面是我用 2 位验证码进行训练的结果:

30张图片进行测试,结果:

哎呦,有感觉了,有了起色了,出现了过拟合的现象,解决过拟合的方法主要有:
1、get more trainning data
2、reduce the capacity of the network
3、 add weight regularization
4、add dropout
5、data-augmentation
6、batch normalization
第三回
于是我就增加了数据集,train count: 4410, valid count: 1890, test count: 2700,
然后又出现了 loss 一直在 2.3,accuracy 在 0.09 左右,这是什么鬼呢?我都想骂娘了。
但是我还是不死心呀,继续想办法呀,既然彩色的有难度,我先识别黑白的样本行不行呢,先试试吧。
第四回
网络结构依然采用上面的,input_shape(100,80,3)
这是我用 2 位的黑白图片的验证码进行了训练,效果很好,收敛也很快。
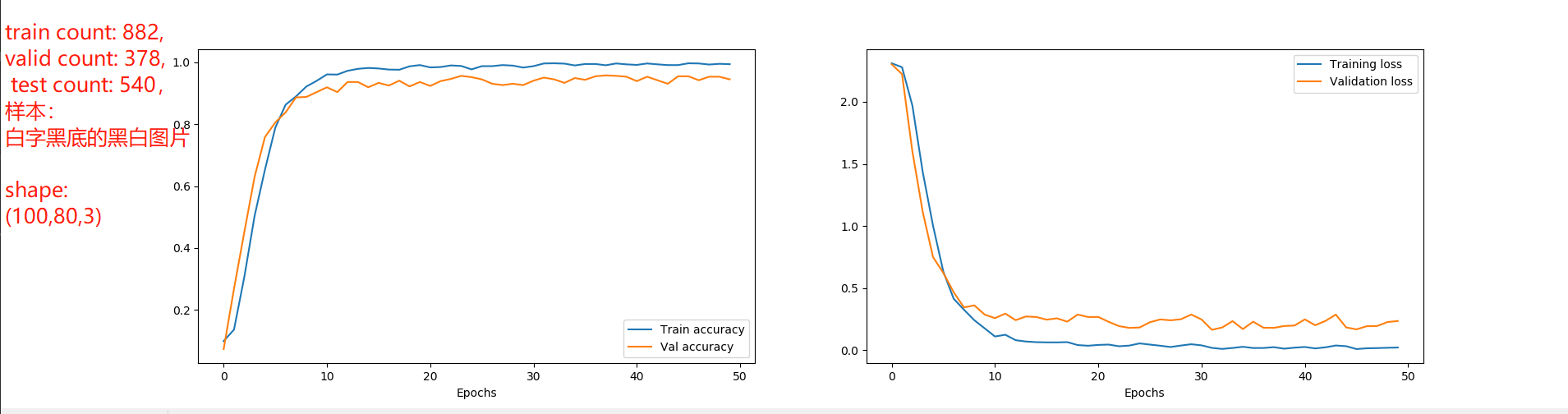
训练第 50 回合时:
Epoch 50/50
26/27 [============>…] - ETA: 0s - loss: 0.0150 - accuracy: 0.9940
27/27 [==============] - 8s 289ms/step - loss: 0.0212 - accuracy: 0.9936 - val_loss: 0.2348 - val_accuracy: 0.9446,
随机选取了 30 张图片进行了测试,2 张识别错了:

样本图:

看着这结果,我露出了洁白的牙牙,信心大增呀,继续搞,直接上4位验证码。
第五回
依然采用上面的网络结构,
这次使用的是 4 位黑白图片的验证码
train count: 2469, valid count: 1059, test count: 1512,

训练第 20 回合:
Epoch 20/20
76/77 [====>.] - ETA: 0s - loss: 0.0409 - accuracy: 0.9860
77/77 [======] - 33s 429ms/step - loss: 0.0408 - accuracy: 0.9861 - val_loss: 0.3283 - val_accuracy: 0.9221,
随机选取 30 张图片进行测试,8 张错误:

4位验证码的样本图:

从结果来看,,有点过拟合,没关系,继续加大数据集,
第六回
依旧采用上面的网络结构:
这次我增加了数据集 4939 张,依旧使用的是 4 位黑白的验证码,训练结果还是挺好的:
train count: 4939, valid count: 2117, test count: 3024,

第 20 回合:
Epoch 20/20
153/154 [==>.] - ETA: 0s - loss: 0.0327 - accuracy: 0.9898
154/154 [====] - 75s 488ms/step - loss: 0.0329 - accuracy: 0.9898 - val_loss: 0.1057 - val_accuracy: 0.9740,
可以看出 训练集的准确率 跟验证集上很接近。
随机选取 30 张图片进行测试,6 张错误:

好了,搞了这么多,由此我觉得是噪点影响了深度学习的识别,maxpool的时候连带着噪点也采样了,我们需要将噪点处理掉,再喂入神经网络。
下篇我需要把彩色验证码上噪点给去掉,然后再送入神经网络,请持续关注。
使用tensorflow2识别4位验证码及思考总结的更多相关文章
- [验证码识别技术]字符验证码杀手--CNN
字符验证码杀手--CNN 1 abstract 目前随着深度学习,越来越蓬勃的发展,在图像识别和语音识别中也表现出了强大的生产力.对于普通的深度学习爱好者来说,一上来就去跑那边公开的大型数据库,比如I ...
- java练习题(字符串类):显示4位验证码、输出年月日、从XML中抓取信息
1.显示4位验证码 注:大小写字母.数字混合 public static void main(String[] args) { String s="abcdefghijklmnopqrstu ...
- python利用selenium库识别点触验证码
利用selenium库和超级鹰识别点触验证码(学习于静谧大大的书,想自己整理一下思路) 一.超级鹰注册:超级鹰入口 1.首先注册一个超级鹰账号,然后在超级鹰免费测试地方可以关注公众号,领取1000积分 ...
- js 做的随机8位验证码
开发思路: 画出放置验证码的模块.一个写有“看不清…”的小块,以及输入验证码的文本框 获取各个模块 封装一个函数Yan_ma(),设置验证码为8位,里面含有数字,小写字母,小写字母和中文.每种类型出现 ...
- 爬虫(十二):图形验证码的识别、滑动验证码的识别(B站滑动验证码)
1. 验证码识别 随着爬虫的发展,越来越多的网站开始采用各种各样的措施来反爬虫,其中一个措施便是使用验证码.随着技术的发展,验证码也越来越花里胡哨的了.最开始就是几个数字随机组成的图像验证码,后来加入 ...
- java识别简单的验证码
1.老规矩,先上图 要破解类似这样的验证码: 拆分后结果: 然后去匹配,得到结果. 2.拆分图片 拿到图片后,首先把图片中我们需要的部分截取出来. 具体的做法是,创建一个的和图片像素相同的一个代表权重 ...
- time-based基于google key生成6位验证码(google authenticator)
由于公司服务器启用了双因子认证,登录时需要再次输入谷歌身份验证器生成的验证码.而生成验证码是基于固定的算法的,以当前时间为基础,基于每个人的google key去生成一个6位的验证码.也就是说,只要是 ...
- python下调用pytesseract识别某网站验证码
一.pytesseract介绍 1.pytesseract说明 pytesseract最新版本0.1.6,网址:https://pypi.python.org/pypi/pytesseract Pyt ...
- Aforge.net识别简易数字验证码问题
参考:https://www.bbsmax.com/A/rV57LjWGdP/ https://blog.csdn.net/louislong007/article/details/47683035 ...
随机推荐
- 找回 Virtuoso 中的缩放和角度
https://www.cnblogs.com/yeungchie/ 打开要缩放的版图 CIW 中运行:dbCreateXformPCell(geGetEditCellView() geGetEdit ...
- Skill 脚本演示 ycSchReGrid.il
https://www.cnblogs.com/yeungchie/ ycSchReGrid.il 修复 schematic 或 schematicSymbol 视图中 offGrid 的问题. 回到 ...
- Python性能分析与优化PDF高清完整版免费下载|百度云盘
百度云盘|Python性能分析与优化PDF高清完整版免费下载 提取码:ubjt 内容简介 全面掌握Python代码性能分析和优化方法,消除性能瓶颈,迅速改善程序性能! 对于Python程序员来说,仅仅 ...
- luogu P5289 [十二省联考2019]皮配 背包
LINK:皮配 我承认是一道很难的题目. 不过对于这道题 部分分的提示显得尤为重要. 首先是 40分的暴力dp 很容易想 但是不容易写. 从40分可以发现我们只需要把蓝阵营和鸭派系的人数给存在起来就行 ...
- 在Swoole上加速Laravel应用
Swoole是用于PHP的生产级异步编程框架.它是用纯C语言编写的PHP扩展,它使PHP开发人员可以在PHP中编写高性能,可伸缩的并发TCP,UDP,Unix套接字,HTTP,WebSocket服务, ...
- elasticsearch 高级搜索示例 es7.0
基础数据 创建索引 PUT mytest { "mappings": { "properties": { "title": { " ...
- IdentityServer4 (3) 授权码模式(Authorization Code)
写在前面 1.源码(.Net Core 2.2) git地址:https://github.com/yizhaoxian/CoreIdentityServer4Demo.git 2.相关章节 2.1. ...
- Linux入门-程序开发
Linux程序开发 linux程序总体上来说是分两部分的: 1. 底层驱动程序开发: 2.应用层应用程序开发: 驱动程序 一般情况下驱动是跟内核与硬件有关系的,编程语言是C语言,需要懂一些硬件的知识, ...
- 这几个冷门却实用的 Python 库,我爱了!
- Python画各种 3D 图形Matplotlib库
回顾 2D 作图 用赛贝尔曲线作 2d 图.此图是用基于 Matplotlib 的 Path 通过赛贝尔曲线实现的,有对赛贝尔曲线感兴趣的朋友们可以去学习学习,在 matplotlib 中,figur ...