【mq读书笔记】消息队列负载与重新分配(分配 新队列pullRequest入队)
回顾PullMessageService#run:
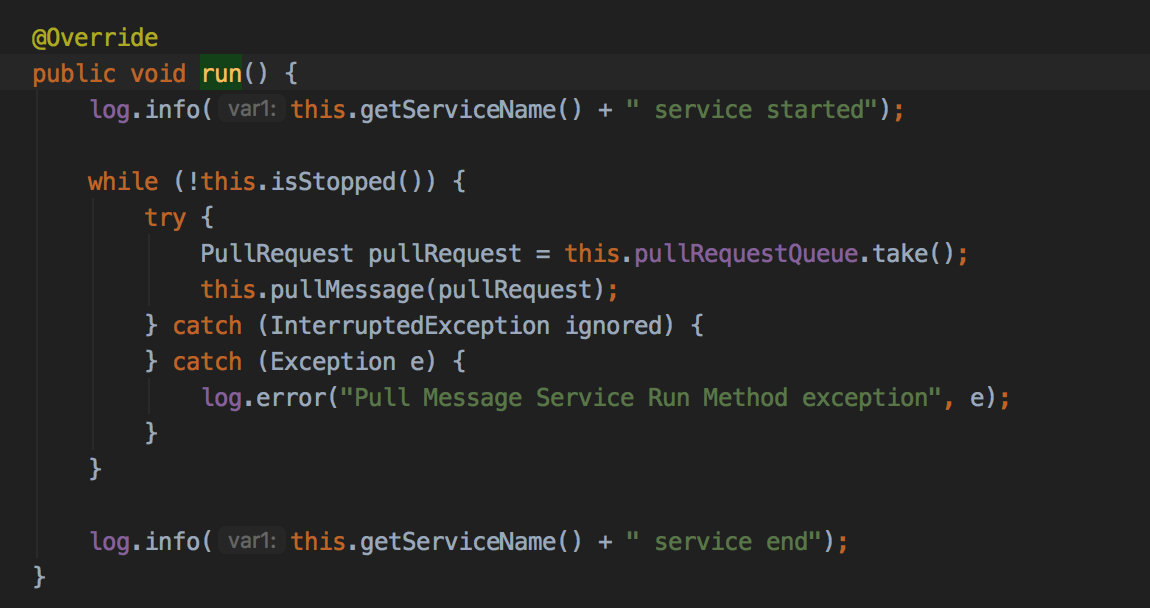
如果队列总没有PullRequest对象,线程将阻塞。
围绕PullRequest有2个问题:
1.PullRequest对象在什么时候创建并加入pullRequestQueue中以便唤醒PullMessageService县城
2.集群内多个消费者如何负载主题下的多个消费队列,并且如果有新的消费者加入时,消息队列又会如何重新分布。
重新分布实现:RebalanceService,一个MQClientInstance持有一个RebalanceService实现,并随MQClientInstance启动而启动。
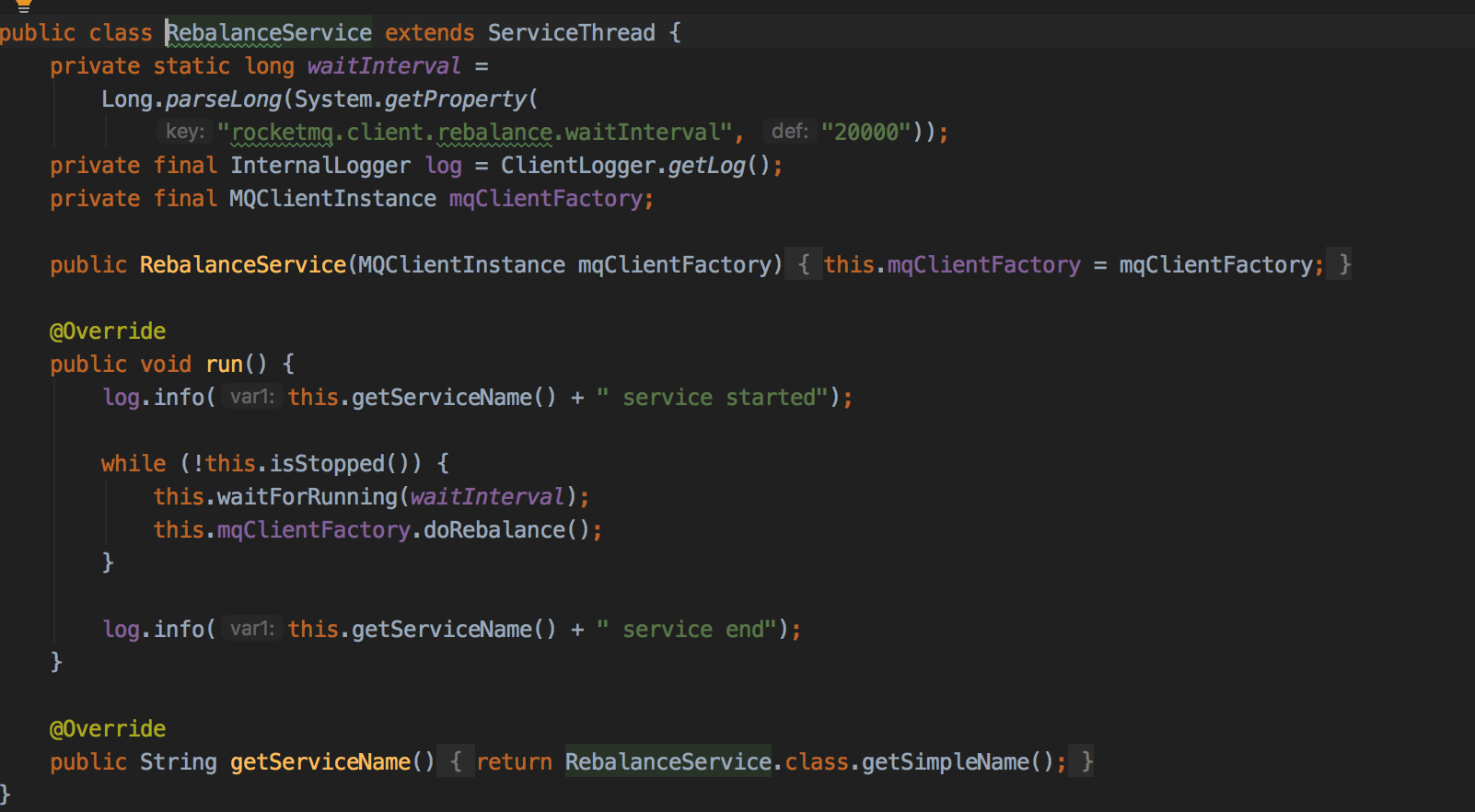
默认每隔20s rebalance一次。
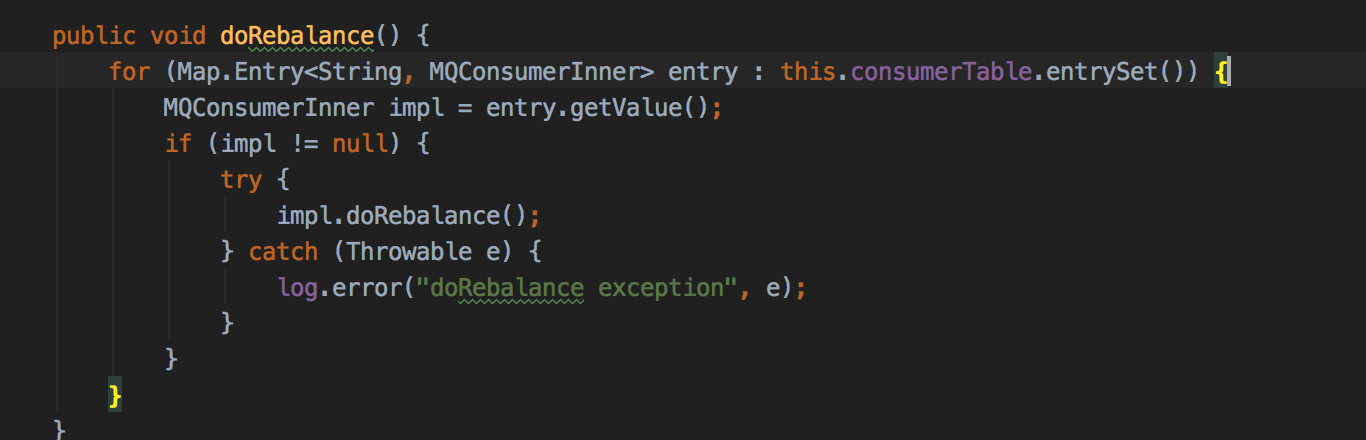
遍历已注册的消费者(这个consumerTable是怎么来的),对消费者执行doRebalance
public void doRebalance(final boolean isOrder) {
Map<String, SubscriptionData> subTable = this.getSubscriptionInner();//在消费者调用subscribe方法时填充。
if (subTable != null) {
for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {
final String topic = entry.getKey();
try {
this.rebalanceByTopic(topic, isOrder);
} catch (Throwable e) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("rebalanceByTopic Exception", e);
}
}
}
}
this.truncateMessageQueueNotMyTopic();
}
每个DefaultMQPushConsumerImpl都持有一个单独的RebalanceImpl对象,该方法遍历订阅信息对每个主题的队列进行重新负载。
RebalanceImpl#rebalanceByTopic:
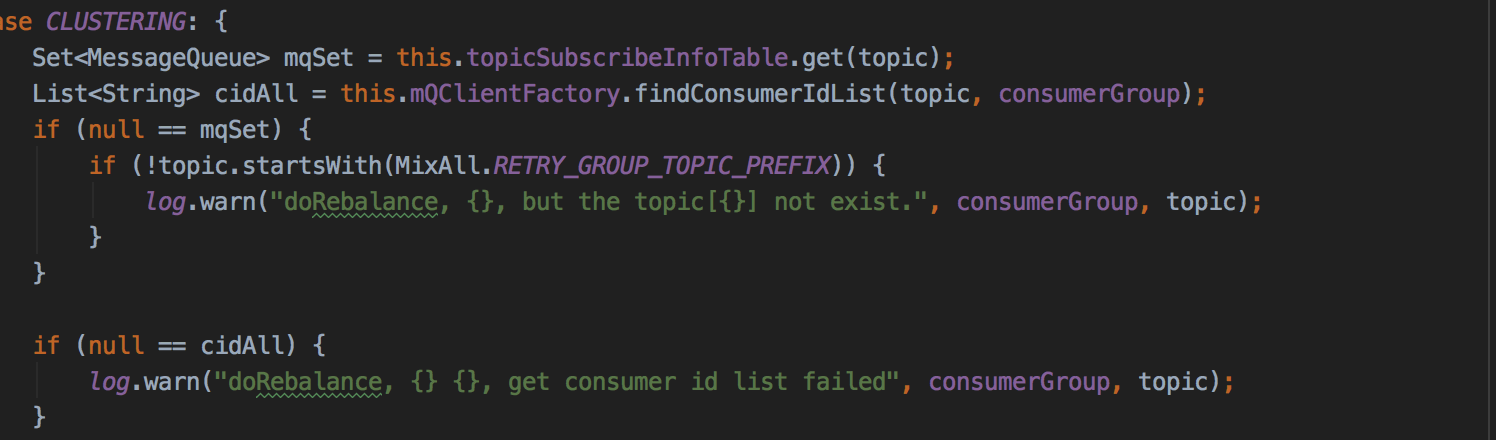
从主题订阅信息缓存表中获取主体的队列消息,发送请求从Broker中该消费组内当前所有的消费者客户端ID,主题topic的队列可能分布在多个Broker上,那请求发往哪个Broker呢?
答案是随机选择一个,Broker为什么会存在消费组内所有消费者的信息呢?MQClientInstance会向所有的Broker发送心跳包,心跳中包含MQClientInstance的消费者信息。
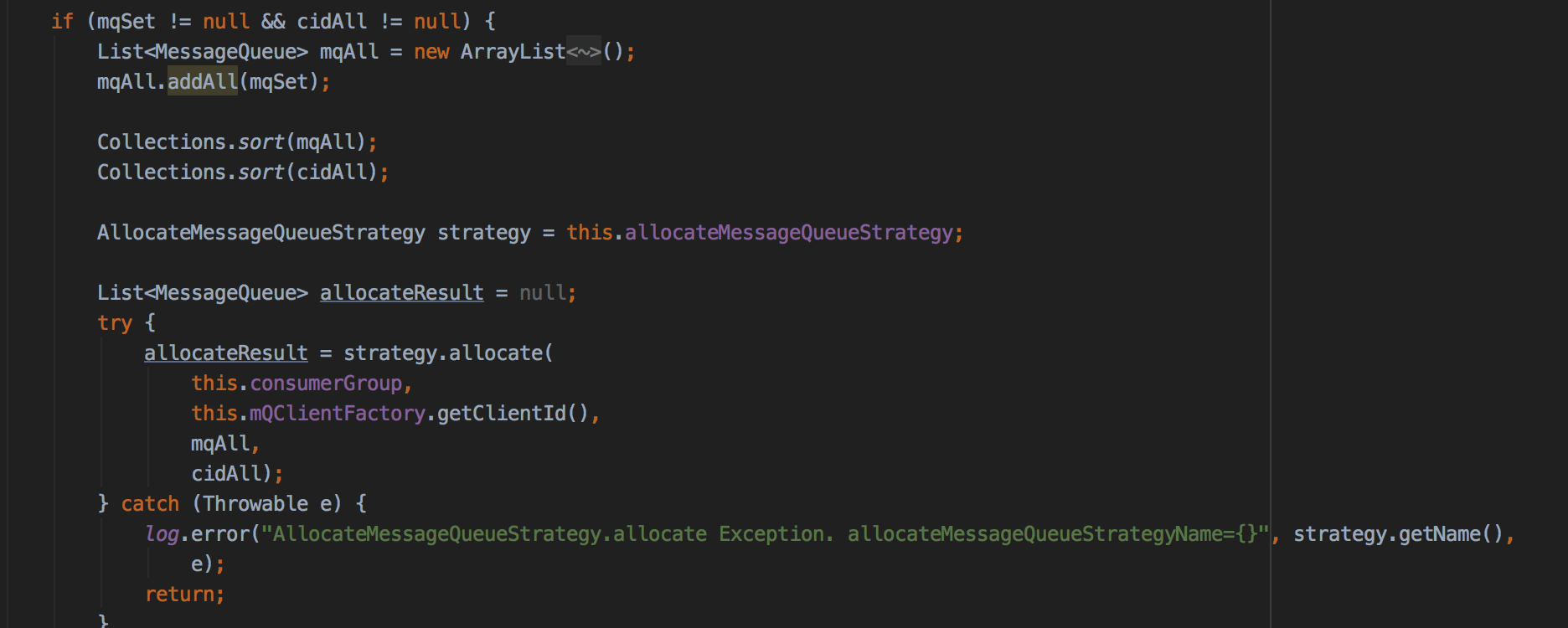
allocate()一共有5种分配算法。
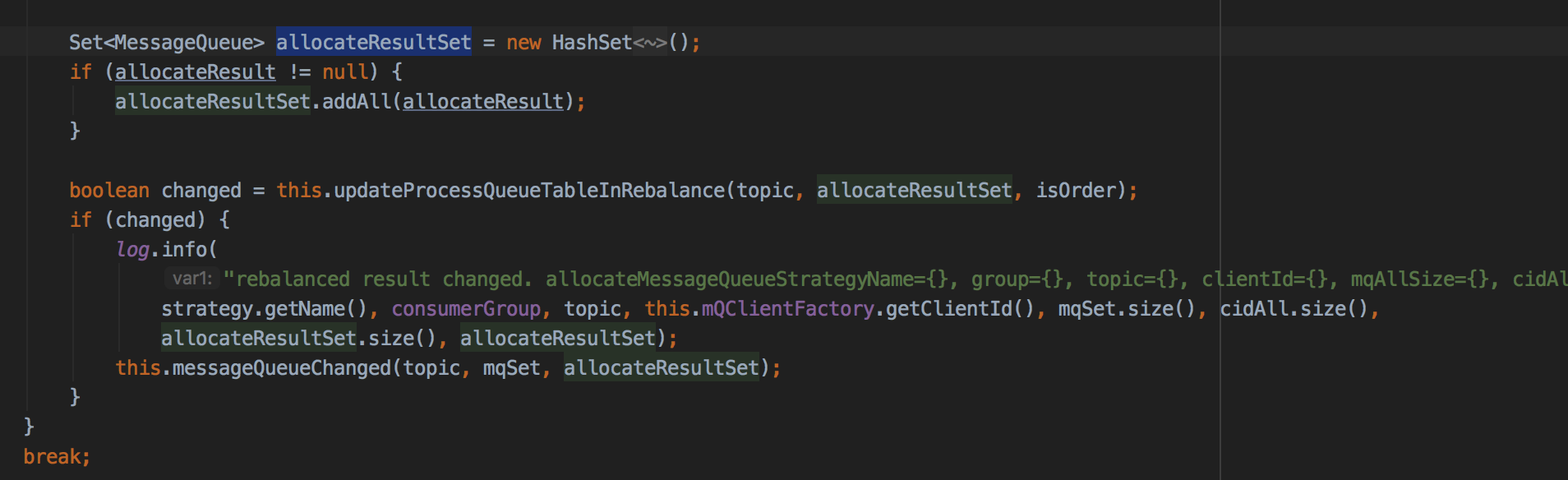
private boolean updateProcessQueueTableInRebalance(final String topic, final Set<MessageQueue> mqSet,
final boolean isOrder) {
boolean changed = false; Iterator<Entry<MessageQueue, ProcessQueue>> it = this.processQueueTable.entrySet().iterator();
while (it.hasNext()) {
Entry<MessageQueue, ProcessQueue> next = it.next();
MessageQueue mq = next.getKey();
ProcessQueue pq = next.getValue(); if (mq.getTopic().equals(topic)) {
//如果新分配的队列不包含当前旧队列,则停止消费旧队列
if (!mqSet.contains(mq)) {
pq.setDropped(true);
if (this.removeUnnecessaryMessageQueue(mq, pq)) {
it.remove();
changed = true;
log.info("doRebalance, {}, remove unnecessary mq, {}", consumerGroup, mq);
}
} else if (pq.isPullExpired()) {
switch (this.consumeType()) {
case CONSUME_ACTIVELY:
break;
case CONSUME_PASSIVELY:
pq.setDropped(true);
if (this.removeUnnecessaryMessageQueue(mq, pq)) {
it.remove();
changed = true;
log.error("[BUG]doRebalance, {}, remove unnecessary mq, {}, because pull is pause, so try to fixed it",
consumerGroup, mq);
}
break;
default:
break;
}
}
}
}
List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
for (MessageQueue mq : mqSet) {
if (!this.processQueueTable.containsKey(mq)) {
//如果是新非分配的队列:
if (isOrder && !this.lock(mq)) {
log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
continue;
}
this.removeDirtyOffset(mq);
ProcessQueue pq = new ProcessQueue();
long nextOffset = this.computePullFromWhere(mq);
if (nextOffset >= 0) {
ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
if (pre != null) {
log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
} else {
//创建队列拉取任务PullRequest,添加到PullMessageService线程的pullRequestQueue中
log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
PullRequest pullRequest = new PullRequest();
pullRequest.setConsumerGroup(consumerGroup);
pullRequest.setNextOffset(nextOffset);
pullRequest.setMessageQueue(mq);
pullRequest.setProcessQueue(pq);
pullRequestList.add(pullRequest);
changed = true;
}
} else {
log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
}
}
}
this.dispatchPullRequest(pullRequestList);
RebalancePushImpl#computePullFromWhere:
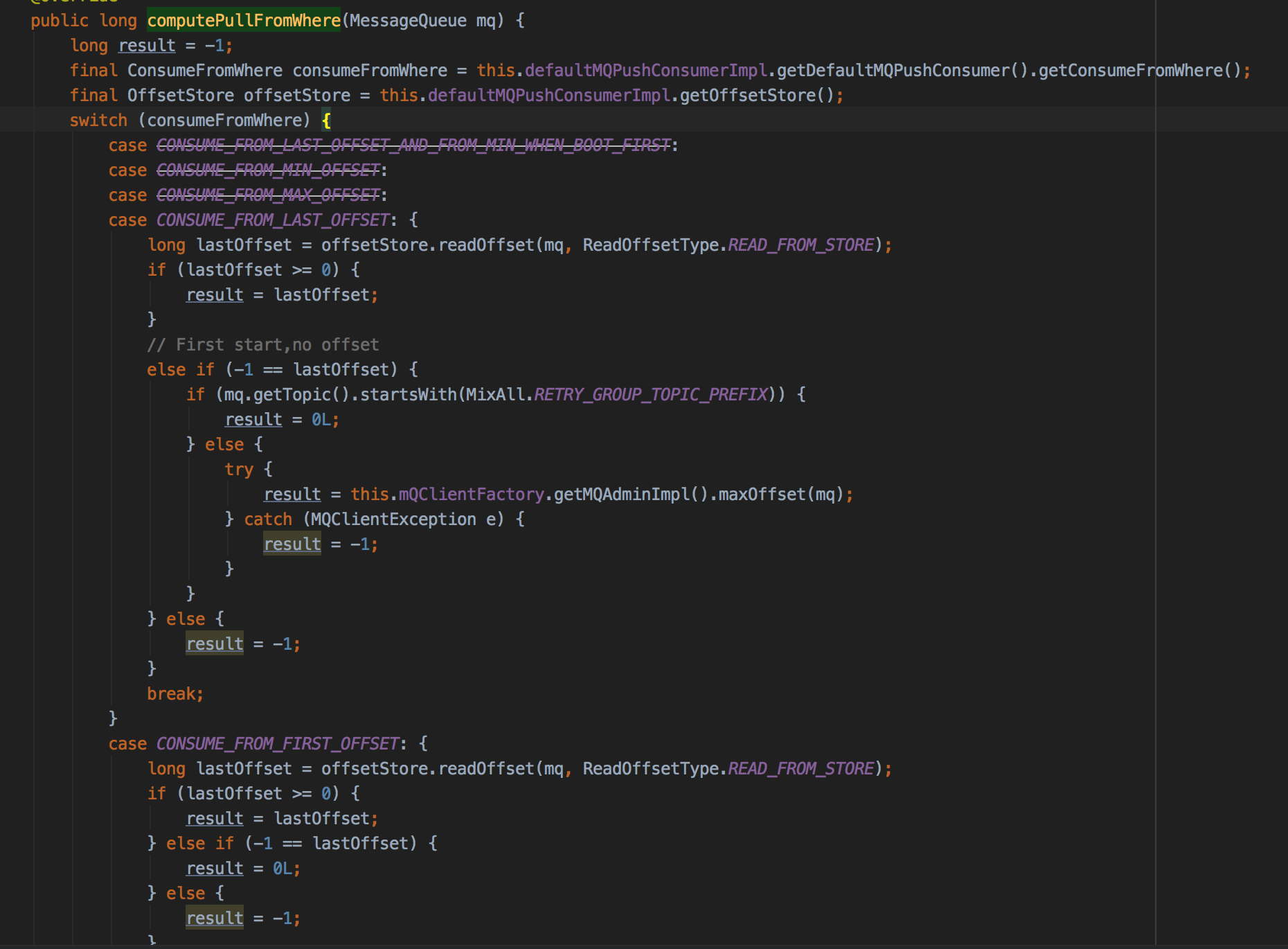
offsetStore.readOffset=-1表示该消息队列刚创建。从磁盘中读取消息队列的消费进度,如果大于0则直接返回即可;如果等于-1,CONSUME_FROM_LAST_OFFSET模式下获取该消息队列当前最大的偏移量。如果小于-1,则表示该消息进度文件中存储了错误的偏移量。
如果CONSUME_FROM_FIRST_OFFSET,则在等于-1时,直接返回0从头开始。
如果CONSUME_FROM_TIMESTAMP:从消费者启动的时间戳对应的消费进度开始消费:
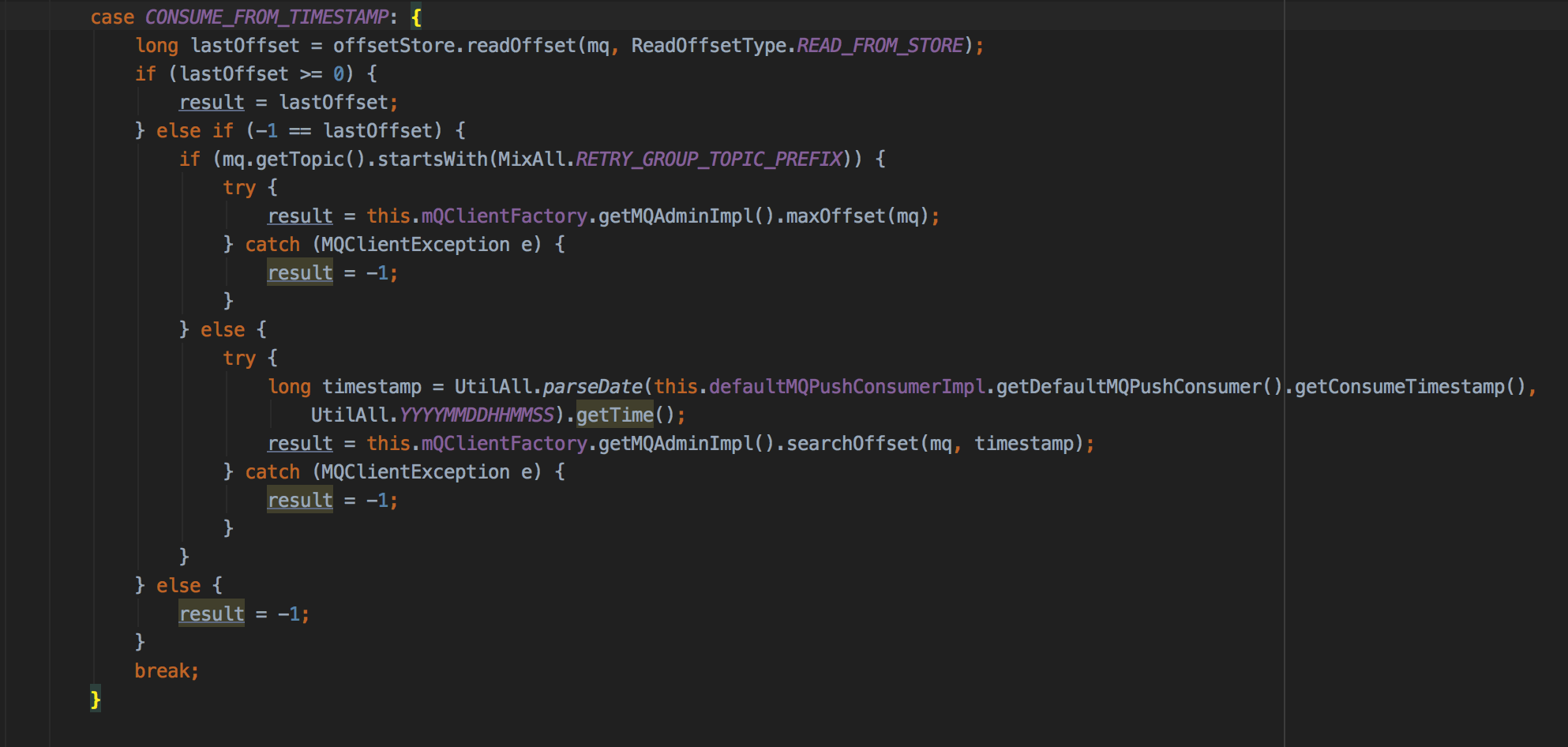
如果等于-1,尝试去操作消息存储时间戳为消费者启动的时间戳,如果能找到则返回找到的偏移量,否则返回0。
以上如果lastOffset小于-1,表示该消息进度文件中存储了错误的偏移量,result=-1,在后面的过程中,用偏移量-1拉取消息时会无法取到消息,但是会用-1去更新消费进度,然后将消息消费队列丢弃,在下一次消息队列负载时会再次消费
总结:RebalanceService线程每隔20s对消费者订阅的主题进行一次队列重新分配,每一次分配都会获取主题的所有队列,从Broker服务器实时查询当前该主题该消费组内消费者列表,对新分配的消息队列会创建对应PullRequest对象。在一个JVM进程中,同一个消费组同一个队列只会存在一个PullRequest对象。
每次进行队列重新负载时会从Broker实时查询出当前组内所有消费者,并且对消息队列,消费者列表进行排序,这样新加入的消费者就会在队列重新分布时分配到消费队列从而消费消息。
【mq读书笔记】消息队列负载与重新分配(分配 新队列pullRequest入队)的更多相关文章
- 【mq读书笔记】顺序消息
注意异常情况导致整个消费无限重试 阻塞消费 mq支持局部消息顺序消费,可以确保同一个消息消费队列中的消息被顺序消费.看下针对顺序消息在整个消费过程中做的调整: 队列负载: DefaultMQPushC ...
- 【mq读书笔记】mq消息消费
消息消费以组的的模式开展: 一个消费组内可以包含多个消费者,每一个消费组可订阅多个主题: 消费组之间有集群模式与广播模式两种消费模式:集群模式-主题下的同一条消息只允许被其中一个消费者消费.广播模式- ...
- 【mq读书笔记】消息拉取长轮训机制(Broker端)
RocketMQ并没有真正实现推模式,而是消费者主动想消息服务器拉取消息,推模式是循环向消息服务端发送消息拉取请求. 如果消息消费者向RocketMQ发送消息拉取时,消息未到达消费队列: 如果不启用长 ...
- 《java并发编程实战》读书笔记11--构建自定义的同步工具,条件队列,Condition,AQS
第14章 构建自定义的同步工具 本章将介绍实现状态依赖性的各种选择,以及在使用平台提供的状态依赖机制时需要遵守的各项规则. 14.1 状态依赖性的管理 对于并发对象上依赖状态的方法,虽然有时候在前提条 ...
- 【mq读书笔记】消息确认(失败消息,定时队列重新消费)
接上文的集群模式,监听器返回RECONSUME_LATER,需要将将这些消息发送给Broker延迟消息.如果发送ack消息失败,将延迟5s后提交线程池进行消费. 入口:ConsumeMessageCo ...
- 【mq读书笔记】消息消费队列和索引文件的更新
ConsumeQueue,IndexFile需要及时更新,否则无法及时被消费,根据消息属性查找消息也会出现较大延迟. mq通过开启一个线程ReputMessageService来准时转发commitL ...
- 【mq读书笔记】mq事务消息
关于mq食物以什么样的方式解决了什么样的问题可以参考这里: https://www.jianshu.com/p/cc5c10221aa1 上文中示例基于mq版本较低较新的版本中TransactionL ...
- 【mq读书笔记】定时消息
mq不支持任意的时间京都,如果要支持,不可避免的需要在Broker层做消息排序,加上持久化方面的考量,将不可避免地带来巨大的性能消耗,所以rocketMQ只支持特定级别的延迟消息. 在Broker短通 ...
- 【mq读书笔记】消息消费过程(钩子 失败重试 消费偏移记录)
在https://www.cnblogs.com/lccsblog/p/12249265.html中,PullMessageService负责对消息队列进行消息拉取,从远端服务器拉取消息后将消息存入P ...
随机推荐
- NB-IOT覆盖能力有多强 是怎么实现的
NB-IoT技术中出现以来就以其强大的覆盖能力和通信距离长而受到广大使用者的欢迎,那么NB-IoT覆盖能力究竟是有多大,其覆盖能力应该怎么来衡量? 强大的覆盖能力是NB-IoT技术的最大特点之一,不仅 ...
- [论文阅读] RNN 在阿里DIEN中的应用
[论文阅读] RNN 在阿里DIEN中的应用 0x00 摘要 本文基于阿里推荐DIEN代码,梳理了下RNN一些概念,以及TensorFlow中的部分源码.本博客旨在帮助小伙伴们详细了解每一步骤以及为什 ...
- C3P0和Druid数据库连接池
目录 C3P0连接池 步骤: C3P0初始化: 创建C3P0工具类: 创建C3P0测试类: Druid连接池(由阿里巴巴提供的数据库连接池实现技术) 步骤: Druid初始化: 创建Druid工具类: ...
- 常用简单电脑bai快捷键大全
Ctrl+C 复制.duCtrl+X 剪切.Ctrl+V粘贴.Ctrl+Z撤销.Ctrl+A全选所有文件.zhiDelete删除.daoShift+Delete避开回收站直接永久删除(不可找回).F3 ...
- GraphX 在图数据库 Nebula Graph 的图计算实践
不同来源的异构数据间存在着千丝万缕的关联,这种数据之间隐藏的关联关系和网络结构特性对于数据分析至关重要,图计算就是以图作为数据模型来表达问题并予以解决的过程. 一.背景 随着网络信息技术的飞速发展,数 ...
- git引入_版本控制介绍
八个字形容git技术: 公司必备,一定要会 一.git概念: git是一个免费的,开源的分布式版本控制系统,可以快速高效的处理从小型到大型的项目 二.什么是版本控制: 版本控制是一种一个记录一个或若个 ...
- jupyter使用自动补全和切换默认浏览器
自动补全 可以做conda环境中执行以下命令.linux下打开conda环境的命令是: conda activate 退出conda环境的命令是: conda deactivate 安装插件: pip ...
- icmp port unreachable
端口不可达: client------>server 结果server回复端口不可达, 由于是icmp报文: 到达client内核协议栈后进入icmp_rcv处理: /* * Deal with ...
- yum 的一些问题总结
1. yum 只删除目标,不删除依赖 rpm -e --nodeps xxx 2.yum remove 出错 报错 Error: Cannot retrieve repository metadata ...
- Loadrunner学习(一)
一个优秀的软件系统不单单具有良好的功能,还需要有过硬的性能,一个只通过功能测试的系统,只能称之为"可用",而不能算是"好用".当然,性能测试需要基于功能测试,只 ...