用python在excel中读取与生成随机数写入excel中
今天是我第一次发博客,就关于python在excel中的应用作为我的第一篇吧。
具体要求是:在一份已知的excel表格中读取学生的学号与姓名,再将这些数据放到新的excel表中的第一列与第二列,最后再生成随机数作为学生的考试成绩。
首先要用到的数据库有:xlwt,xlrd,random这三个数据库。
命令如下:
import xlwt
import xlrd
import random
现有一份表格内容如下图:
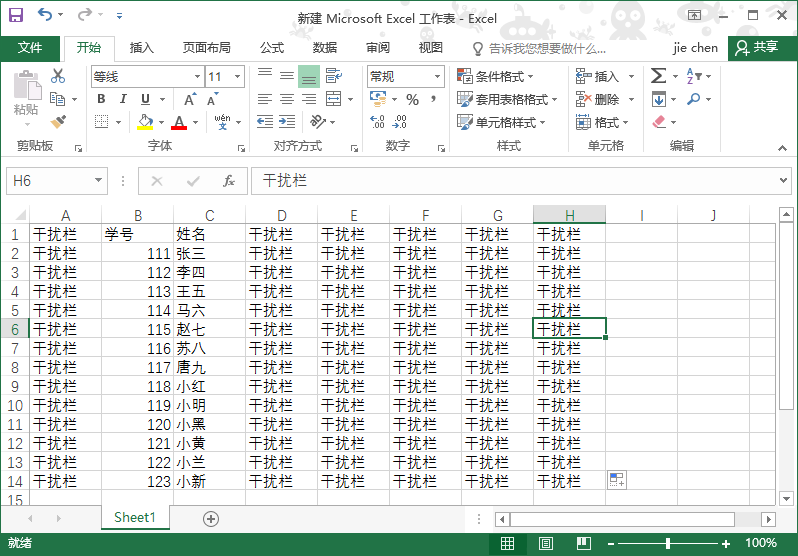
现在我们需要提取这其中的B1—C14。
(提示:在对这份电子表格进行操作的时候,要使用到这个电子表格的地址,即表格的储存位置。)
excel=xlrd.open_workbook(G:\python\新建文件夹\表1.xlsx') #打开并读取表格
sheet=excel.sheets()[0] #在原表1中提取第一页中的数据。对excel进行处理时,行列页都是从0开始进行计算
wb=xlwt.Workbook() #创立一个新的excel表格
ws =wb.add_sheet('成绩单') #第一页命名为成绩单
(如果要进行多页操作,要将学号姓名放到两页excel表格中的话可以如下操作:
ws1=wb.add_sheet('1班成绩单')
ws2=wb.add_sheet('2班成绩单')
)
创建两个list:
a=[]
b=[]
(这两个list是用来临时存放学号与姓名的)
for i in range (1,14): #在大二下学期15级成绩汇总.xlsx表中提取出姓名与学号
a .append(sheet.row_values(i,1,2)) #提取第i行的第1个数,即这个命令抽取的是表中的学号列
b .append(sheet.row_values(i,2,3)) #提取第i行的第2个数,即这个命令抽取的是表中的姓名列
在此特比注意:excel中行与列均是从0开始计算的,即表中第1行第1列在进行处理运行时为第0行第0列,表中第2行第2列在进行处理运行时为第1行第1列。表中sheet也是从0开始算起。
解释一下: a .append(sheet.row_values(i,1,2))在经过几次错误后我发现,i是指第i行,1,2这两个是一段范围。即取的是第1个值,按照上面注意的说,就是表中第二个框格的值。
如果对此有疑问可以试一下将1,2修改一个值进行尝试。
for n in range(13): #将学号与姓名写入新建的表格中,并写在第1页,人数为13人。
ws.write(n,0,a[n][0])
ws.write(n,1,b[n][0])
提醒:为什么这里要用a[n][0]而不是a[n]?这个是我自己水平有限制的原因。因为在提取表中数据放入a,b两个list中他们的形式是:a=[[111],[112],[113]……]的形式,对于这一点的解决方法我还没想出来,因此只能靠a[n][0]这样的形式来解决。因为在写入新的表格过程中不能将list整个放入框格中,只能放入文本或者其他框格允许的格式。如果你们有什么比较好的方法可以提出来我们一起交流学习,感激不尽。
for q in range(13): #对1班所有人的成绩进行随机抽取数据
ran=random.randint(60,91)
if ran<=70:
ws1.write(q,2,'及格({0})'.format(ran))
if ran>70 and ran<=80:
ws1.write(q,2,'中等({0})'.format(ran))
if ran>80 and ran<=90:
ws1.write(q,2,'良好({0})'.format(ran))
wb.save('15资环1,2班地理信息系统实习成绩.xls') #将新建的表格保存为'15资环1,2班地理信息系统实习成绩.xls'文件
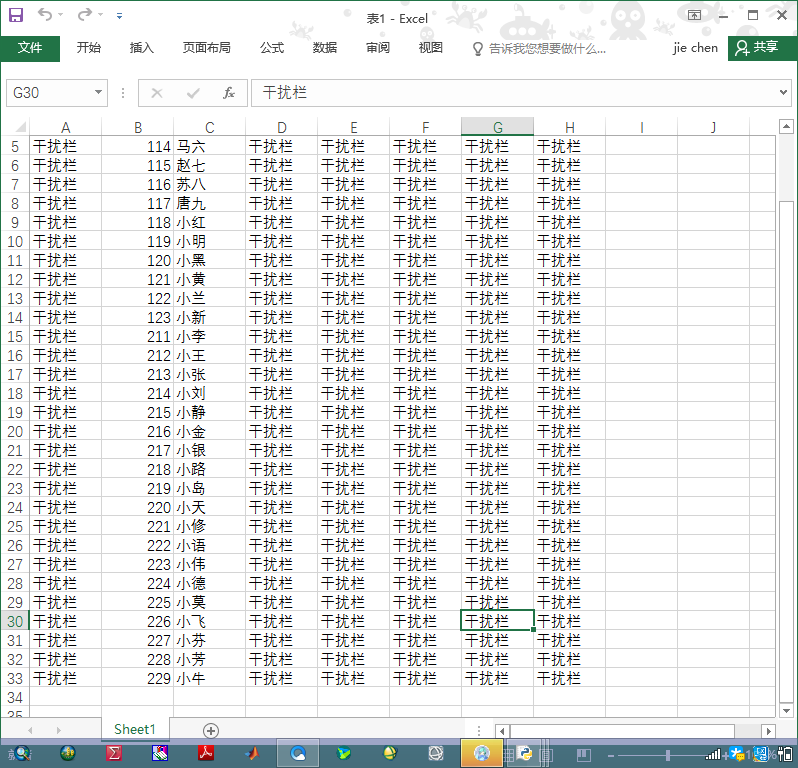
以下代码是由两个班的数据进行运算。
原来的表格为:
import xlwt #引入xlwt数据库用来将数据写入excel文档中
import xlrd #引入xlrd数据库用来从excel中读取数据
import random #引入random数据库给出随机数 excel=xlrd.open_workbook('G:\python\新建文件夹\表1.xlsx') #从一个已有学号与姓名的excel表格中提取出对应的学号和姓名 sheet=excel.sheets()[0]
wb=xlwt.Workbook() #创立一个新的excel表格
ws1=wb.add_sheet('1班成绩单') #第一页命名为1班成绩单
ws2=wb.add_sheet('2班成绩单') #第一页命名为2班成绩单 a1=[] #表1中的学号列
a2=[] #表2中的学号列
b1=[] #表1中的姓名列
b2=[] #表2中的姓名列 for i in range (1,14): #表1.xlsx表中提取出1班的姓名与学号
a1.append(sheet.row_values(i,1,2))
b1.append(sheet.row_values(i,2,3)) for j in range (14,33): #在表1.xlsx表中提取出1班的姓名与学号
a2.append(sheet.row_values(j,1,2))
b2.append(sheet.row_values(j,2,3)) for n in range(13): #将1班学号与姓名写入新建的表格中,并写在第1页.1班人数为13人
ws1.write(n,0,a1[n][0])
ws1.write(n,1,b1[n][0])
for m in range(19): #将2班学号与姓名写入新建的表格中,并写在第2页.2班人数为19人
ws2.write(m,0,a2[m][0])
ws2.write(m,1,b2[m][0]) for q in range(13): #对1班所有人的成绩进行随机抽取数据
ran=random.randint(60,91) #分数为60-90之间
if ran<=70:
ws1.write(q,2,'及格({0})'.format(ran)) #以下表示在各分数段的等级
if ran>70 and ran<=80:
ws1.write(q,2,'中等({0})'.format(ran))
if ran>80 and ran<=90:
ws1.write(q,2,'良好({0})'.format(ran)) for d in range(19): #对2班所有人的成绩进行随机抽取数据
ran=random.randint(60,91)
if ran<=70:
ws2.write(d,2,'及格({0})'.format(ran))
if ran>70 and ran<=80:
ws2.write(d,2,'中等({0})'.format(ran))
if ran>80 and ran<=90:
ws2.write(d,2,'良好({0})'.format(ran)) wb.save('15资环1,2班地理信息系统实习成绩.xls') #将新建的表格保存为'15资环1,2班地理信息系统实习成绩.xls'文件
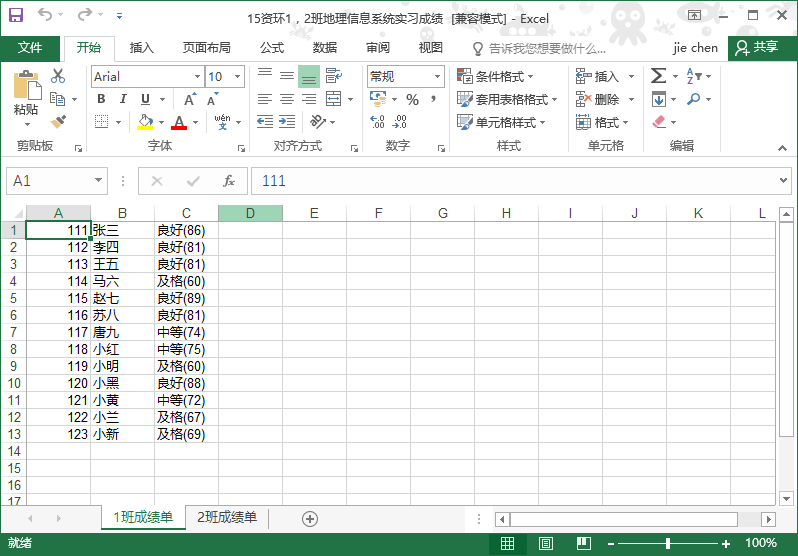
结果如下:
用python在excel中读取与生成随机数写入excel中的更多相关文章
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- Python中random模块生成随机数详解
Python中random模块生成随机数详解 本文给大家汇总了一下在Python中random模块中最常用的生成随机数的方法,有需要的小伙伴可以参考下 Python中的random模块用于生成随机数. ...
- 读取xml文件,写入excel
在上一篇 Python写xml文件已经将所有订单写入xml文件,这一篇我们把xml文件中的内容读出来,写入excel文件. 输入xml格式: <?xml version="1.0&qu ...
- 从Excel中读取数据并批量写入MySQL数据库(基于MySQLdb)
一.Excel内容如下,现在需要将Excel中的数据全部写入的MySQL数据库中: 二.连接MySQL的第三方库使用的是“MySQLdb”,代码如下: # -*- coding:utf-8 -*-im ...
- python 文件单行循环读取的坑(一个程序中,文件默认只能按行循环读取一次,即使写到另一个循环里,它也只读取一次)
本来写了一个程序,想获取a文件中有,但是b文件中没有的行: 想到的方法是:1.一行一行提取a文件中数据,然后用a文件中的每一行与b文件中的每一行比较, 2.如果找到相同行就继续查找a中的下一行,如果找 ...
- Excel导入导出,生成和下载Excel报表、附件等操作--ASP.NET
public class OutExcel { public static void OutExcel_bb(DataTable dt, string thepath, string temppath ...
- java:从指定问价中读取80个字节写入指定文件中
import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; public class F ...
- 从Excel中读取数据并批量写入MySQL数据库(基于pymysql)
一.Excel内容时这样的: 二.最初的代码是这样的: # -*- coding:utf-8 -*-import pymysqlfrom xlrd import open_workbook class ...
- MVC中的ActionLink生成的属性名称 中划线的解决办法
当使用ActionLink来生成链接属性时,由于中划线的变量名称不符合命名规则,那么直接写中划线的变量时无法编译,此时只要改为下划线即可.Razor 引擎会自动转为中划线. 即 data_icon ...
随机推荐
- AndroidStudio cannot resolve symbol 解决办法 清楚缓存
<?xml version="1.0" encoding="utf-8"?><RelativeLayout xmlns:android=&qu ...
- Lonlife 1000 - Spoon Devil's 3-D Matrix
1000 - Spoon Devil's 3-D Matrix Time Limit:1s Memory Limit:32MByte Submissions:208Solved:65 DESCRIPT ...
- FreeRTOS--疑难解答
此章节涉及新手最常遇见的3种问题: 错误的中断优先级设置 栈溢出 不恰当的使用printf() 使用configASSERT()能够显著地提高生产效率,它能够捕获.识别多种类型的错误.强烈建议在开发或 ...
- 原生Js实现拖拽(适用于pc和移动端)
效果: HTML和CSS部分 <!DOCTYPE html> <html lang="en"> <head> <meta charset= ...
- springMVC使用jsp:include嵌入页面的两种方式
1.静态嵌入子页面 <%@ include file="header.jsp" %> 静态嵌入支持 jsp . html . xml 以及纯文本. 静态嵌入在编译时 ...
- Android 7.1 WindowManagerService 屏幕旋转流程分析 (二)
一.概述 从上篇[Android 7.1 屏幕旋转流程分析]知道实际的旋转由WindowManagerService来完成,这里接着上面具体详细展开. 调了三个函数完成了三件事,即首先调用update ...
- HDU-1828-Picture(线段树)
Problem Description A number of rectangular posters, photographs and other pictures of the same shap ...
- 为WebClient增加Cookie的支持
我们经常会在应用程序中使用到WebClient模拟访问网站资源并且进行处理,如果多次访问之间我们希望为他们保存Cookie,换句话说,第一个请求产生的Cookie能自动带到第二个请求的话,可以通过自定 ...
- TP3.2.3 接入支付宝
TP3.2.3 接入支付宝 项目接入支付宝支付了,在做这个给我的感觉是,方便 ,毕竟是老马的产品是吧, 话不多说 , 首先我们先找到官方的SDK ,不想去找的小伙伴复制此链接 https://doc ...
- java中websocket的应用
在上一篇文章中,笔者简要介绍了websocket的应用场景及优点,戳这里 这篇文章主要来介绍一下在java项目中,特别是java web项目中websocket的应用. 场景:我做了一个商城系统,跟大 ...