Kafka0.10.2.0分布式集群安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
1.2 Scala
参见博文:http://www.cnblogs.com/liugh/p/6624491.html
1.3 Zookeeper
参见博文:http://www.cnblogs.com/liugh/p/6671460.html
二、文件准备
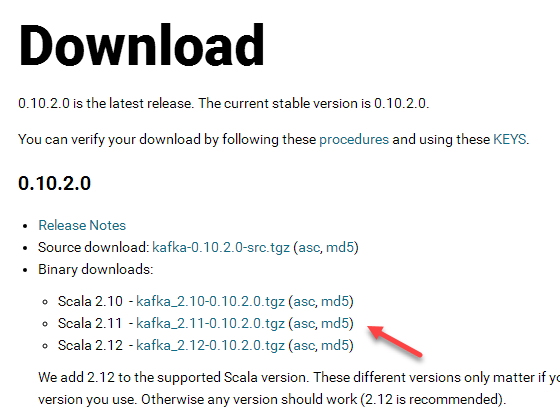
2.1 文件名称
kafka_2.11-0.10.2.0.tgz
2.2 下载地址
http://kafka.apache.org/downloads
三、工具准备
3.1 Xshell
一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。
Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
3.2 Xftp
一个基于 MS windows 平台的功能强大的SFTP、FTP 文件传输软件。
使用了 Xftp 以后,MS windows 用户能安全地在UNIX/Linux 和 Windows PC 之间传输文件。
四、部署图

五、Kafka安装
以下操作,均使用root用户
5.1 通过Xftp将下载下来的Kafka安装文件上传到Master及两个Slave的/usr目录下
5.2 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf kafka_2.11-0.10.2.0.tgz
5.3 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
#Kafka Env
export KAFKA_HOME=/usr/kafka_2.11-0.10.2.0
export PATH=$PATH:$KAFKA_HOME/bin
5.4 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Slave节点上执行# source /etc/profile使其立即生效
六、Kafka配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Slave节点即可。
6.1 server.properties配置文件
切换到/usr/kafka_2.11-0.10.2.0/config目录下
使用vi编辑器,打开server.properties,主要设置BrokerId、listeners、LogDir、Zookeeper,如下所示:
broker.id= listeners=PLAINTEXT://DEV-SH-MAP-01:9092 log.dirs=/usr/kafka_2.-0.10.2.0/log zookeeper.connect=DEV-SH-MAP-:,DEV-SH-MAP-:,DEV-SH-MAP-:
其中:
1)broker.id:broker的id,必需是一个全局(集群)唯一的整数值,即集群中每个kafka server的配置不能相同
2)listeners:socket监听的地址,格式为listeners = security_protocol://host_name:port,端口默认为9092
3)log.dirs:日志保存目录
4)zookeeper.connect:zookeeper连接地址
拷贝配置文件到两个Slave节点:
在Master节点,执行如下命令:
# scp server.properties root@DEV-SH-MAP-02:/usr/kafka_2.11-0.10.2.0/config
# scp server.properties root@DEV-SH-MAP-03:/usr/kafka_2.11-0.10.2.0/config
【注意】需要结合具体的Slave节点,修改borker.Id、listeners
七、Kafka使用
7.1 启动Kafka集群
分别在Master及两个Slave上执行命令:
kafka-server-start.sh -daemon server.properties
7.2 创建Topic
kafka-topics.sh --zookeeper DEV-SH-MAP-01:2181 --create --replication-factor 1 --partitions 1 --topic test
7.3 查看Topic
kafka-topics.sh --zookeeper DEV-SH-MAP-01:2181 --list
7.4 创建Producer
kafka-console-producer.sh --broker-list DEV-SH-MAP-01:9092 --topic test
7.5 创建Consumer
kafka-console-consumer.sh --bootstrap-server DEV-SH-MAP-01:9092 --topic test --from-beginning
7.6 删除Topic
kafka-topics.sh --zookeeper DEV-SH-MAP-01:2181 --delete --topic test
Kafka0.10.2.0分布式集群安装的更多相关文章
- Spark2.1.0分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Hadoop 参见博文:http://www.cnblogs ...
- Spark2.2.0分布式集群安装(StandAlone模式)
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 1.2 Scala 参见博文:http://www.cnblogs. ...
- CentOS 6+Hadoop 2.6.0分布式集群安装
1.角色分配 IP Role Hostname 192.168.18.37 Master/NameNode/JobTracker HDP1 192.168.18.35 Slave/DataNode/T ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
随机推荐
- Angular.js之指令学习笔记
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"& ...
- laravel中的Database Notifications
创建Post and User模型 php artisan make:model Post php artisan make:model User 创建posts and users 表文件 ph ...
- mvc路由
一.路由常规设置 1.URL模式 路由系统用一组路由来实现它的功能.这些路由共同组成了应用程序的URL架构或方案. URL的两个关键行为: a.URL模式是保守的,因而只匹配与模式具有 ...
- 面向对象 "一"
1:面向对象不是所有情况都适用. 2面向对象编程 a:定义类 calss Foo: 注意顶一个类的时候首字母必须是大写 def (方法一)(self,bb) pass b:根据创建对象,创建和Foo实 ...
- wemall app商城源码中android按钮的三种响应事件
wemall-mobile是基于WeMall的android app商城,只需要在原商城目录下上传接口文件即可完成服务端的配置,客户端可定制修改.本文分享wemall app商城源码中android按 ...
- java异常详解
java异常需要弄清楚如下几个问题: 1.java异常的层次结构 2.搞清楚问题:java中异常抛出后代码还会继续执行吗? 答:该问题可以参考该博文,完美的回答了我的疑惑:http://www.cnb ...
- HTML超文本标记语言-基础标签整理
第一章 <META>标签: <meta http-equiv="Content-Type" Content="text/html;charset=gb2 ...
- 【转】Django Middleware
Django 处理一个 Request 的过程是首先通过中间件,然后再通过默认的 URL 方式进行的.我们可以在 Middleware 这个地方把所有Request 拦截住,用我们自己的方式完成处理以 ...
- TCP/IP笔记(三)数据链路层
数据链路的作用 数据链路层的协议定义了通过通信媒介互连的设备之间传输的规范.通信媒介包括双绞线电缆.同轴电缆.光纤.电波以及红外线等介质.此外,各个设备之间有时也会通过交换机.网桥.中继器等中转数据. ...
- iOS开发之Xib和storyboard对比
相同点: (2)都用来描述软件界面 (2)都用Interface Builder工具来编辑 不同点: (1)Xib是轻量级的,用来描述局部的UI界面 (2)Storyboard是重量级的,用来描述整个 ...