PCI_Making Recommendations
协作性过滤
基于用户的协作性过滤
简单理解从众多用户中先搜索出与目标用户‘品味’相似的部分人,然后考察这部分人的偏爱,根据偏爱结果为用户做推荐。这个过程也成为基于用户的协作性过滤(user_based collaborative filtering)。
以推荐电影为例
数据集
偏好数据集,嵌套字典,格式为:{用户:{电影名称:评分}}。
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}
寻找相近用户
从众多用户中先搜索出与目标用户‘品味’相似的人。相似度的计算用欧几里得距离和皮尔逊相关度来计算。
皮尔逊相关度公式:
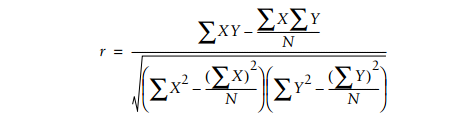
from math import sqrt #欧几里得距离
#将得到的距离1/(1+distance),保持sim_distance值在(0,1),且sim_distance越大,两者越近
def sim_distance(prefs,person1,person2):
si = {}
for item in prefs[person1]:
if item in prefs[person2]:
si[item] = 1 if len(si) == 0:
return 0 sum_of_squares = sum([pow(prefs[person1][item] - prefs[person2][item],2)
for item in prefs[person1] if item in prefs[person2]]) return 1/(1 + sum_of_squares) #皮尔逊系数
#对不整齐/规范数据更有效,如本例具有相同品味但某一人评价更严格,在欧几里得距离看来是不相近的,但pearsion会找到最佳拟合线(best_fit line)所以更准确
def sim_pearson(prefs, person1, person2):
si = {}
for item in prefs[person1]:
if item in prefs[person2] :
si[item] = 1 # 两者有相似的个数
n = len(si) if n==0 :
return 1 sum1=sum([prefs[person1][it] for it in si])
sum2=sum([prefs[person2][it] for it in si]) sum1Sq=sum([pow(prefs[person1][it],2) for it in si])
sum2Sq=sum([pow(prefs[person2][it],2) for it in si]) pSum=sum([prefs[person1][it]*prefs[person2][it] for it in si]) num=pSum-(sum1*sum2/n) den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n)) if den ==0 :
return 0 r = num / den return r
测试:
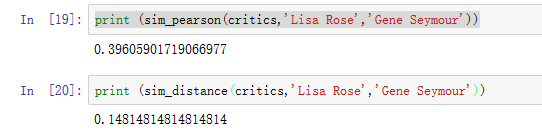
确定计算相关度方法后,找相关度最高用户:
#为评论者打分
#找到相关度最高的用户,similarity指定相关度方法,n指定返回最相似用户人数
def topMatches(prefs, person, n = 5, similarity = sim_distance):
scores = [(similarity(prefs, person, other), other)
for other in prefs if other != person]
scores.sort()
scores.reverse()
return scores[0:n]
测试:

推荐物品
经过搜索到‘品味’相同的人后,可以选择从最相似用户看过的电影随机选一部,这是可行的,但可能刚好有一部你想看的但最相似的用户没看过。由此需要对推荐物品做处理:1.对所有相似用户做加权,突出更相似用户比重;2.抑制被评论更多的影片对结果的影响。下表可反应该过程:
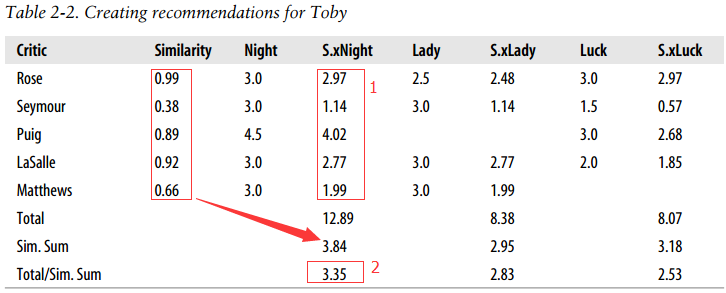
#推荐
def getRecommendations(prefs, person, similarity = sim_distance):
totals={}
simSums={} for other in prefs:
if other == person: continue sim = similarity(prefs, person, other)
if sim <= 0: continue #只对没看过的影片进行评分
#加权相似用户评价值
for item in prefs[other]:
if item not in prefs[person] or prefs[person][item]==0:
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
#print(totals[item]) simSums.setdefault(item,0)
simSums[item]+=sim for item, total in totals.items():
pass #对自己可能想看的电影评分
rankings=[(total/simSums[item],item) for item, total in totals.items()] rankings.sort()
rankings.reverse()
return rankings
测试:

至此,一个简易的基于用户的推荐系统完成。但实际中更多可能存在基于物品推荐的情况,以该列说明,给定一个电影推荐相似电影。通过查看那些用户喜欢该电影,再搜索这些用户还喜欢其他电影的程度/评价来做相似度匹配,在该例中通过改变数据集即可实现。
#转换数据集
def transformPrefs(prefs):
result={}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{}) result[item][person] = prefs[person][item]
return result
转换结果如下:{电影名:{用户:评分}}
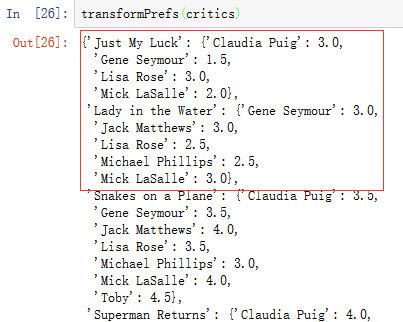
测试:

基于物品的协作型过滤
基于用户的过滤方法在数据量小时较为有效,但当数据量变大时,每次为用户推荐都逐个用户比较显然不合理,基于物品的过滤(item_based collaborative filtering)预先计算好相近物品,当对用户进行推荐时,只要查看预先构造好的列表即可。而且该计算无需不停计算,只要及时的在网络流量不大情况下进行即可。
构造相似物品数据集
构造包含相近物品的完整数据集。构造完成后在需要推荐时使用。
#构造包含相近物品的完整数据集
def calculateSimilarItems(prefs,n=10):
result = {}
#数据集以物品为中心 {物品:{用户:评分}}
itemprefs = transformPrefs(prefs)
c = 0
for item in itemprefs:
c+=1
if c%100==0: print('%d / %d' %(c,len(itemprefs))) #构造最相似物品集合
scores=topMatches(itemprefs,item, n=n,similarity=sim_distance)
result[item]=scores
return result
测试:

获得推荐
经过以上,已经事先得到各电影之间的相似度,在推荐时使用。对各相似电影相似度加权,具体如下:
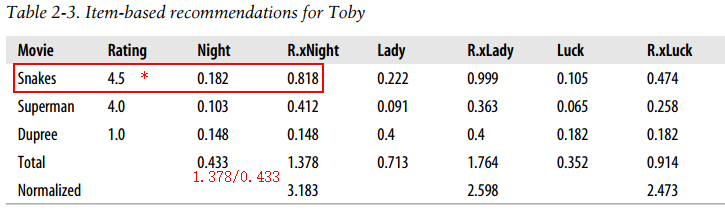
#推荐
def getRecommendedItems(prefs,itemMatch,user):
userRatings = prefs[user]
scores={}
totalSim={} for (item,rating) in userRatings.items(): #print ('item= %s rating= %s' % (item,rating))
for (similarity,item2) in itemMatch[item]:
#print('similarity=%s item2=%s'%(similarity,item2))
#如果已经评价过则忽略
if item2 in userRatings: continue scores.setdefault(item2,0)
scores[item2]+=similarity*rating totalSim.setdefault(item2,0)
totalSim[item2]+=similarity rankings = [(score/totalSim[item],item) for item,score in scores.items()]
rankings.sort()
rankings.reverse()
return rankings
测试:

----------------------------------------------------------
本系列为较早学习《集体智慧编程》的笔记,多注释在代码出,现重写在Blog,多有理解不当之处,望指教。
PCI_Making Recommendations的更多相关文章
- 【转载】Recommendations with Thompson Sampling (Part II)
[原文链接:http://engineering.richrelevance.com/recommendations-thompson-sampling/.] [本文链接:http://www.cnb ...
- <Programming Collective Intelligence> Chapter2:Making Recommendations
<Programming Collective Intelligence> Chapter2:Making Recommendations 欧几里得距离评价 皮尔逊相关度评价 它相比于欧几 ...
- C# - Recommendations for Abstract Classes vs. Interfaces
The choice of whether to design your functionality as an interface or an abstract class can somet ...
- xDB and sitecore 8 hardware Recommendations
xDB and sitecore 8 hardware Recommendations as below: xDB hardware guidelines https://doc.sitecore.n ...
- XML Publisher Report Issues, Recommendations and Errors
In this Document Purpose Questions and Answers References APPLIES TO: Oracle Process Manufactu ...
- Netflix Recommendations
by Xavier Amatriain and Justin Basilico (Personalization Science and Engineering) In part one of thi ...
- Best Practices and Recommendations for RAC databases with SGA size over 100GB (文档 ID 1619155.1)
Best Practices and Recommendations for RAC databases with SGA size over 100GB (文档 ID 1619155.1) APPL ...
- 1950261 - SAP HANA Database Backup Policy Recommendations and Regular Backup Script
=====Symptom For SAP Business One, version for SAP HANA users, SAP HANA provides a range of database ...
- 【RS】Amazon.com recommendations: item-to-item collaborative filtering - 亚马逊推荐:基于物品的协同过滤
[论文标题]Amazon.com recommendations: item-to-item collaborative filtering (2003,Published by the IEEE C ...
随机推荐
- PHP接口学习
接口:不同类的共同行为进行定义,然后在不同类中实现不同的功能. 接口的具体语法: 接口是零件可以用多个零件组成一个新东西: 接口本身是抽象的,内部申明的方法也是抽象的: 不用加abstract 一个类 ...
- Java 9 揭秘(2. 模块化系统)
文 by / 林本托 Tips 做一个终身学习的人. 在此章节中,主要介绍以下内容: 在JDK 9之前Java源代码用于编写,打包和部署的方式以及该方法的潜在问题 JDK 9中有哪些模块 如何声明模块 ...
- Catalog Service - 解析微软微服务架构eShopOnContainers(三)
上一篇我们说了Identity Service,因为其基于IdentityServer4开发的,所以知识点不是很多,今天我们来看下Catalog Service,今后的讲解都会把不同的.重点的拿出来讲 ...
- cocoapod升级
1.0 重新安装问题 cd /user/xx/.cocoapod/repos rm -rf master pod setup /user/xx/.cocoapod/repos 查看目录文件夹大小: d ...
- html逻辑运算符
逻辑运算符 逻辑运算符用于测定变量或值之间的逻辑. 给定 x=6 以及 y=3,下表解释了逻辑运算符: &&and(x < 10 && y > 1) 为 t ...
- RSA加密通信小结(四)--RSA加解密的实际操作与流程小结
在上一篇文章中,我们已经将密钥的生成方法和流程,归纳总结.而本篇主要是讲如何利用密钥进行加解密. 首先,在上一篇文章中的我们生成了很多密钥,证书等等. 在上述生成的文件中,接收服务端加密报文:pkcs ...
- POJ 1207 3N+1 Problem
更简单的水题,穷举法即可. 需要注意的点: 1.i 和 j的大小关系不确定,即有可能 i>j 2.即使i>j,最后输出的结果也要严格按照输出,亦即如果输入10,1,则对应输出也应为 10 ...
- require.js的初步认识
我们之前呢写Javascript代码时都会写在一个文件里面,只要加载这一个文件就够了.后来,代码越来越多必须分成多个文件,依次加载.就如下面的代码: <script src="a.js ...
- jQuery.merge( first, second )返回: Array
jQuery.merge( first, second )返回: Array描述: 合并两个数组内容到第一个数组.first类型: Array第一个用于合并的数组,其中将会包含合并后的第二个数组的内容 ...
- java注解编程