Python3.5下安装&测试Scrapy
1、引言
Scrapy框架结构清晰,基于twisted的异步架构可以充分利用计算机资源,是做爬虫必备基础,本文将对Scrapy的安装作介绍。
2、安装lxml
2.1 下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 选择对应python3.5的lxml库
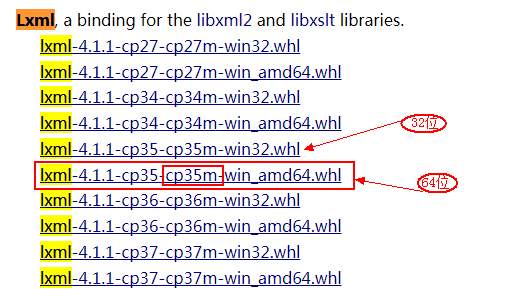
2.2 如果pip的版本过低,先升级pip:
python -m pip install -U pip
2.3 安装lxml库(先将下载的库文件copy到python的安装目录,按住shift键并鼠标右击选择“在此处打开命令窗口”)
pip install lxml-4.1.1-cp35-cp35m-win_amd64.whl
看到出现successfully等字样说明按章成功。
3、 安装Twisted库
3.1 下载链接:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 选择对应python3.5的库文件
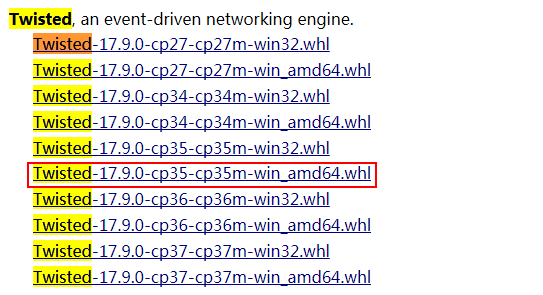
3.2 安装
pip install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
看到出现successfully等字样说明按章成功。
Note:部分机器可能安装失败,可以尝试将 Twisted-17.9.0-cp35-cp35m-win_amd64.whl文件移动到 $python/Scripts/ 目录下,重新安装。
4、安装Scrapy
twisted库安装成功后,安装scrapy就简单了,在命令提示符窗口直接输入命令:
pip install scrapy
看到出现successfully等字样说明按章成功。
5、Scrapy测试
5.1 新建项目
先新建一个Scrapy爬虫项目,选择python的工作目录(我的是:H:\PycharmProjects 然后安装Shift键并鼠标右键选择“在此处打开命令窗口”),然后输入命令:
scrapy startproject allister
对应目录会生成目录allister文件夹,目录结构如下:
└── allister
├── allister
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
└── scrapy.cfg 简单介绍个文件的作用:
# -----------------------------------------------
scrapy.cfg:项目的配置文件;
allister/ : 项目的python模块,将会从这里引用代码
allister/items.py:项目的items文件
allister/pipelines.py:项目的pipelines文件
allister/settings.py :项目的设置文件
allister/spiders : 存储爬虫的目录
5.2 修改allister/items.py文件:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class AllisterItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
5.3 编写文件 AllisterSpider.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : AllisterSpider.py
# @Author: Allister.Liu
# @Date : 2018/1/18
# @Desc : import scrapy
from allister.items import AllisterItem class ItcastSpider(scrapy.Spider):
name = "ic2c"
allowed_domains = ["http://www.itcast.cn"]
start_urls = [
"http://www.itcast.cn/channel/teacher.shtml#ac"
] def parse(self, response):
items = [] for site in response.xpath('//div[@class="li_txt"]'):
item = AllisterItem() t_name = site.xpath('h3/text()')
t_level = site.xpath('h4/text()')
t_desc = site.xpath('p/text()') unicode_teacher_name = t_name.extract_first().strip()
unicode_teacher_level = t_level.extract_first().strip()
unicode_teacher_info = t_desc.extract_first().strip() item["name"] = unicode_teacher_name
item["level"] = unicode_teacher_level
item["info"] = unicode_teacher_info yield item
编写完成后复制至项目的 \allister\spiders目录下,cmd选择项目根目录输入以下命令:
scrapy crawl ic2c -o itcast_teachers.json -t json
抓取的数据将以json的格式存储在ic2c_infos.json文件中;
如果出现如下错误请看对应解决办法:
Scrapy运行错误:ImportError: No module named win32api
Python3.5下安装&测试Scrapy的更多相关文章
- Python3.X下安装Scrapy
Python3.X下安装Scrapy (转载) 2017年08月09日 15:19:30 jingzhilie7908 阅读数:519 标签: python 相信很多同学对于爬虫需要安装Scrap ...
- centos7 python3.5 下安装paramiko
centos7 python3.5 下安装paramiko 安装开发包 yum install openssl openssl-devel python-dev -y 安装pip前需要前置安装setu ...
- 在python3.5下安装scrapy包
此前scrapy只支持python2.x 但是最新的1.1.0rc1已结开始支持py3了 如果电脑上安装了scrapy的依赖包,诸如lxml.OpenSSL 1.你直接下载Scrapy-1.1.0rc ...
- python3 linux下安装
1.下载 https://www.python.org/ftp/python/3.5.2/Python-3.5.2.tgz 2.安装 上传到linux服务器 #进入上传文件的目录 cd /app/pr ...
- 在Python3.5下安装和测试Scrapy爬网站
1. 引言 Scrapy框架结构清晰,基于twisted的异步架构可以充分利用计算机资源,是爬虫做大的必备基础.本文将讲解如何快速安装此框架并使用起来. 2. 安装Twisted 2.1 同安装Lxm ...
- win7中python3.4下安装scrapy爬虫框架(亲测可用)
貌似最新的scrapy已经支持python3,但是错误挺多的,以下为在win7中的安装步骤: 1.首先需要安装Scrapy的依赖包,包括parsel, w3lib, cryptography, pyO ...
- 在Windows10 64位 Anaconda4 Python3.5下安装XGBoost
系统环境: Windows10 64bit Anaconda4 Python3.5.1 软件安装: Git for Windows MINGW 在安装的时候要改一个选择(Architecture选择x ...
- Windows python3.3下安装BeautifulSoup
首先在官网下载:http://www.crummy.com/software/BeautifulSoup/#Download BeautifulSoup在版本4以上都开始支持python3了,所以就下 ...
- 关于在Python3.6下安装MySQL-python,flask-sqlalchemy模块的问题
这周末在学习Flask框架的时候,有需要安装MySQL-python模块,一开始用pip安装: pip install MySQL-python 但是安装的时候报错了: error: command ...
随机推荐
- angularf封装echarts
前言:angular中快速使用echarts 在html使用ehart很简单,你只需要引入文件和按照官方例子按照对应参数配置和数据填充就Ok了,那么在angular中怎么使用eharts(可以使用ec ...
- linux应用态下的时间
1.时间值 1.1 日历时间(UTC) 该值是自1 9 7 0年1月1日0 0 : 0 0 : 0 0以来国际标准时间( U T C)所经过的秒数累计值(早期的手册称 U T C为格林尼治标准时间) ...
- Ubuntu安装微信开发者工具
参考教程:https://ruby-china.org/topics/30339 1.下载nw sdk $ wget -c http://dl.nwjs.io/v0.15.3/nwjs-sdk-v0. ...
- JavaScript实现段落文本高亮
代码: <!doctype html> <html lang="en"> <head> <meta http-equiv="Co ...
- 60、jQuery其余操作
上篇主要介绍了jQuery,和一些基本用法,这篇主要讲解动画.常用事件.还有一些jQuery的补充内容. 本篇导航: 动画 常用事件 插件 jQuery API 中文文档 一.动画 1.基本 show ...
- ArcGIS API for JavaScript 4.2学习笔记[24] 【IdentifyTask类】的使用(结合IdentifyParameters类)(第七章完结)
好吧,我都要吐了. 接连三个例子都是类似的套路,使用某个查询参数类的实例,结合对应的Task类,对返回值进行取值.显示. 这个例子是Identify识别,使用了TileLayer这种图层,数据来自Se ...
- RabbitMQ 1-入门学习
环境: 软件环境MacOS ,Homebrew包管理工具 IDE: Eclipse 项目:Maven项目 1.安装RabbitMQ Server: 方式一:通过homebrew :终端执行:brew ...
- js 自定义html标签属性
<input type="text" id="txtBox" displayName="123456" /> 获取自定义属性值: ...
- Confluence5.4.4迁移至6.3.1
1.数据备份 服务器查看: 2.安装破解文件及安装包至服务器 3.停止旧版本并启动安装 4.访问8090端口开始安装 5.获取授权码,需要能访问国外网站,并且有atlassian账号 6.将数据库连接 ...
- CentOs7 systemd添加自定义系统服务
systemd: CentOS 7的服务systemctl脚本存放在:/usr/lib/systemd/,有系统(system)和用户(user)之分,即:/usr/lib/systemd/syste ...