Lucene的配置及创建索引全文检索
Lucene
是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
优点
概念
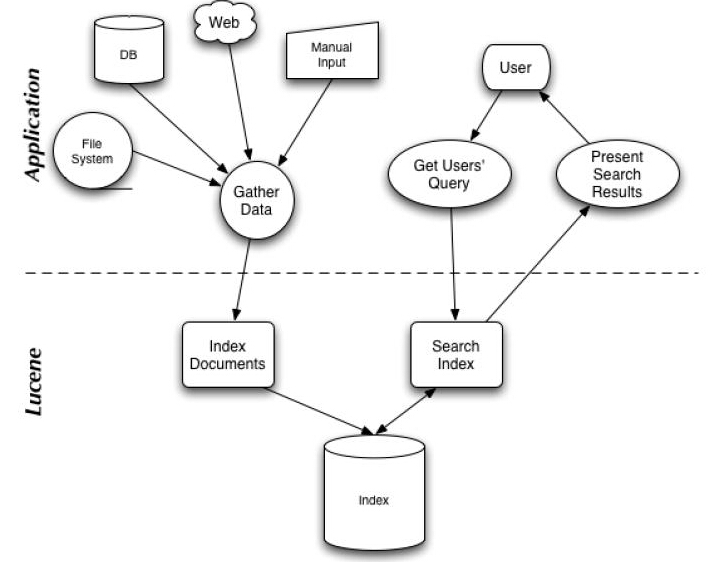
Lucene配置

public static void createindex() throws Exception {
//创建文件目录 创建在项目目录下的index中
Directory dir=FSDirectory.open(FileSystems.getDefault().getPath(System.getProperty("user.dir")+"/index"));
//分词处理 是一个抽象类 一种单字分词,标准的
Analyzer analyzer=new IKAnalyzer();
//创建IndexWriterConfig对象
IndexWriterConfig config=new IndexWriterConfig(analyzer);
//创建IndexWriter对象
IndexWriter iWriter=new IndexWriter(dir, config);
//清除之前的索引
iWriter.deleteAll();
//创建文档对象
Document doc=new Document();
//向文档中添加文本内容字段,及字段类型
doc.add(new Field("fieldname","坚持到底gl博主的博文,转载请注释出处", TextField.TYPE_STORED));
//将文档添加到indexWriter中,写入索引文件中
iWriter.addDocument(doc);
//关闭写入
iWriter.close();
}
这样运行可以看到你的索引index中的内容文件已经创建出来了
索引已经创建,接下来查询一下试试索引 ,传入需要查询的词
public static void search(String string) throws Exception {
Directory dir=FSDirectory.open(FileSystems.getDefault().getPath(System.getProperty("user.dir")+"/search"));
//打开索引目录的
DirectoryReader dReader=DirectoryReader.open(dir);
IndexSearcher searcher=new IndexSearcher(dReader);
//第一个参数 field值 ,第二个参数用户需要检索的字符串
Term t=new Term("fieldname",string);
//将用户需要索引的字符串封装成lucene能识别的内容
Query query=new TermQuery(t);
//查询,最大的返回值10
TopDocs top=searcher.search(query, 10);
//命中数,那个字段命中,命中的字段有几个
System.out.println("命中数:"+top.totalHits);
//查询返回的doc数组
ScoreDoc[] sDocs= top.scoreDocs;
for (ScoreDoc scoreDoc : sDocs) {
//输出命中字段内容
System.out.println(searcher.doc(scoreDoc.doc).get(field));
}
}
就这样一个全文检索的测试就出来了,多去思考总结,扩展出去
再给添加一个代码有益于理解
public static void main(String[] args) throws Exception {
String chString="坚持到底的文章,转载请注释出处";
Analyzer analyzer=new IKAnalyzer();
TokenStream stream=analyzer.tokenStream("word", chString);
stream.reset();
CharTermAttribute cta=stream.addAttribute(CharTermAttribute.class);
while (stream.incrementToken()) {
System.out.println(cta.toString());
}
stream.close();
}
显示如下:

还可以添加这几个文件,有一点需要注意的是,注意你的编码格式
第一个:ext.dic 扩展词典,分词中那个需要组在一起的,如:分词处理可能将“坚持到底”四个字分为“坚持”和“到底”,可以在这个文件中直接添加坚持到底,就可以显示出坚持到底的这个索引
第三个:stopword.dic 扩展停止词典,分词中不想出现的,不希望他被分开出现或单独的,可以往里面写,检索的时候就不会有
第二个:是指定上面两个扩展词典的
这些就是最基本掌握的内容,还有很多分词算法等类型,需要去扩展
Lucene的配置及创建索引全文检索的更多相关文章
- Lucene学习之一:使用lucene为数据库表创建索引,并按关键字查询
最近项目中要用到模糊查询,开始研究lucene,期间走了好多弯路,总算实现了一个简单的demo. 使用的lucene jar包是3.6版本. 一:建立数据库表,并加上测试数据.数据库表:UserInf ...
- Lucene学习笔记:一,全文检索的基本原理
一.总论 根据http://lucene.apache.org/java/docs/index.html定义: Lucene是一个高效的,基于Java的全文检索库. 所以在了解Lucene之前要费一番 ...
- 用Lucene对文档进行索引搜索
问题 现在给出很多份文档,现在对某个搜索词感兴趣,想找到相关的文档. 简单搜索 一种简单粗暴的做法是: 1.读取每个文档:2.找到其中含有搜索词的文档:3.对找到的文档中搜索词出现的次数统计:4.根据 ...
- Elasticsearch-索引新数据(创建索引、添加数据)
ES-索引新数据 0.通过mapping映射新建索引 CURL -XPOST 'localhost:9200/test/index?pretty' -d '{ "mappings" ...
- Apache Lucene(全文检索引擎)—创建索引
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 本项目Demo已上传GitHub,欢迎大家fork下载学习:https://gith ...
- lucene创建索引
创建索引. 1.lucene下载. 下载地址:http://archive.apache.org/dist/lucene/java/. lucene不同版本之间有不小的差别,这里下载的是lucene ...
- lucene简介 创建索引和搜索初步
lucene简介 创建索引和搜索初步 一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引 ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- Lucene 4.7 --创建索引
Lucene的最新版本和以前的语法或者类名,类规定都相差甚远 0.准备工作: 1). Lucene官方API http://lucene.apache.org/core/4_7_0/index.htm ...
随机推荐
- 一步一步学Vue(七)
前言:我以后在文章最后再也不说我下篇博文要写什么,之前说的大家也可以忽略,如果你不忽略,会失望的
- Entity Framework Core 批处理语句
在Entity Framework Core (EF Core)有许多新的功能,最令人期待的功能之一就是批处理语句.那么批处理语句是什么呢?批处理语句意味着它不会为每个插入/更新/删除语句发送单独的请 ...
- 安装j2ee开发环境
先安装jdk,再安装eclipse ,再安装myeclipse. eclipse与myeclipse必须在图形化界面安装. 1. 挂载光驱/硬盘 mount /mnt/cdrom/ 挂载光驱 ...
- Python基础学习 -- 列表与元组
本节学习目的: 掌握数据结构中的列表和元组 应用场景: 编程 = 算法 + 数据结构 数据结构: 通过某种方式(例如对元素进行编号)组织在一起的数据元素的集合,这些元素可以是数字或者字符,或者其他数据 ...
- MongoDB数据库的数据类型和$type操作符
前面的话 本文将详细介绍MongoDB数据库的数据类型和$type操作符 数据类型 MongoDB支持以下数据类型 类型 数字 备注 Double 1 双精度浮点数 - 此类型用于存储浮点值 Stri ...
- 拯救莫莉斯[GDOI2014]
时间限制:1s 内存限制:256MB 问题描述 莫莉斯·乔是圣域里一个叱咤风云的人物,他凭借着自身超强的经济头脑,牢牢控制了圣域的石油市场. 圣域的地图可以看成是一个n*m的矩阵.每个整数坐标 ...
- webpack学习--创建一个webpack打包流程
创建一个webpack打包流程 首先安装webpack插件 mkdir webpack-demo && cd webpack-demo npm init -y npm install ...
- string::npos,一个很大的数
string::npos,这是一个很大的数 npos 是这样定义的: static const size_type npos = -1; 因为 string::size_type (由字符串配置器 a ...
- 干货--Excel的表格数据的一般处理和常用python模块。
写在前面: 本文章的主要目的在于: 介绍了python常用的Excel处理模块:xlwt,xlrd,xllutils,openpyxl,pywin32的使用和应用场景. 本文只针对于Excel表中常用 ...
- 超多经典 canvas 实例,动态离子背景、移动炫彩小球、贪吃蛇、坦克大战、是男人就下100层、心形文字等等等
超多经典 canvas 实例 普及:<canvas> 元素用于在网页上绘制图形.这是一个图形容器,您可以控制其每一像素,必须使用脚本来绘制图形. 注意:IE 8 以及更早的版本不支持 &l ...