23-hadoop-hive的DDL和DML操作
跟mysql类似, hive也有 DDL, 和 DML操作
数据类型: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7. and later)
primitive_type为基本类型, 包括:
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2. and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8. and later)
| TIMESTAMP -- (Note: Available in Hive 0.8. and later)
| DECIMAL -- (Note: Available in Hive 0.11. and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13. and later)
| DATE -- (Note: Available in Hive 0.12. and later)
| VARCHAR -- (Note: Available in Hive 0.12. and later)
| CHAR -- (Note: Available in Hive 0.13. and later)
DDL:
基本语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14. and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10. and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6. and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6. and later)
[AS select_statement]; -- (Note: Available in Hive 0.5. and later; not supported for external tables)
1, 使用简单数据类型创建表
CREATE TABLE page_view(
viewTime INT,
page_url STRING,
ip STRING COMMENT 'IP Address of the User'
)
COMMENT 'This is the page view table'
ROW FORMAT DELIMITED # 使用 \t 进行分隔, 和下面一行一块用
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE; # 数据从文件中导入
准备数据
vini 192.168.208.126
bronk 192.168.208.32
导入:
load data local inpath '/opt/data_hive/test.txt' into table page_view;
2, 使用复合数据类型
创建数据表
CREATE TABLE people (
id string,
name string,
likes array<string>,
addr map<string, string>
)
row format delimited # 使用 \t 分隔数据
fields terminated by '\t'
collection items terminated by ',' # 集合之间使用 , 分隔
map keys terminated by ':' # map的key, values 使用 : 分隔
stored as textfile;
准备数据:
vini game,read,play stuAddr:yt,workAddr:bj
bronk game,read,play stuAddr:sy,workAddr:bj
数据导入:
load data local inpath '/opt/data_hive/test.txt' into table people;
查看数据:
select addr['stuAddr'] from people where name='vini';
3, 带partition的数据导入
CREATE TABLE people (
id string,
name string,
likes array<string>,
addr map<string, string>
)
partitioned by(dt string) # 增加分区字段
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
stored as textfile;
date 为 hive的一个保留字段, 不可使用, 一般使用dt作为代替
准备数据
vini game,read,play stuAddr:yt,workAddr:bj --
bronk game,read,play stuAddr:sy,workAddr:bj --
数据导入, 指定partition
load data local inpath '/opt/data_hive/test.txt' into table people partition (dt='2017-1-1', dt='2017-1-2');
ps: 创建数据表时, 有一个可选字段为 EXTERNAL, 表示创建的为内表还是外表
、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下(如果指定了location的话),也就是说外部表中的数据并不是由它自己来管理的!而内部表则不一样;
、在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
. 在创建内部表或外部表时加上location 的效果是一样的,只不过表目录的位置不同而已,加上partition用法也一样,只不过表目录下会有分区目录而已,load data local inpath直接把本地文件系统的数据上传到hdfs上,有location上传到location指定的位置上,没有的话上传到hive默认配置的数据仓库中。
详细见: http://blog.csdn.net/u012599619/article/details/50999259
DML
使用最多的是 select 语句和 insert 语句
insert:
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
insert使用多的为, 将一张表的数据导入需要的表中
创建表:
CREATE TABLE people_insert (
id string,
name string,
likes array<string>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
stored as textfile;
然后将people表中的部分数据, 导入到新的表中:
INSERT OVERWRITE TABLE people_insert IF NOT EXISTS select id,name,likes FROM people;
可以看到启动了一个新的mapreduce任务去执行
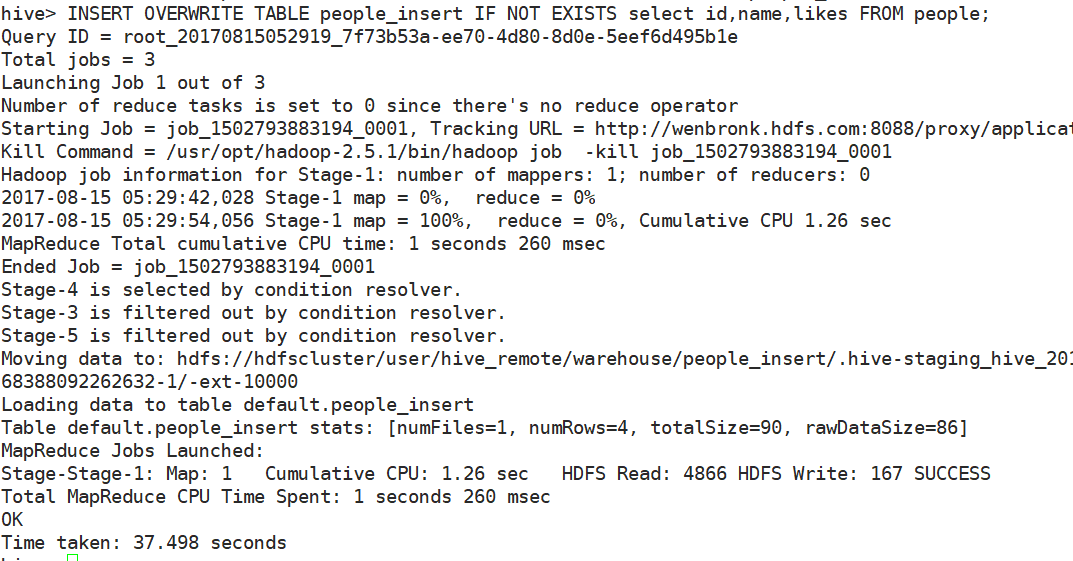
update 和 delete语句需要额外配置一些东西, 但使用不多, 不做阐述
系列来自 尚学堂极限班视频
23-hadoop-hive的DDL和DML操作的更多相关文章
- Hive DDL、DML操作
• 一.DDL操作(数据定义语言)包括:Create.Alter.Show.Drop等. • create database- 创建新数据库 • alter database - 修改数据库 • dr ...
- 大数据开发实战:Hive表DDL和DML
1.Hive 表 DDL 1.1.创建表 Hive中创建表的完整语法如下: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [ (col_nam ...
- Oracle DBLINK 抽数以及DDL、DML操作
DB : 11.2.0.3.0 原库实例orcl:SQL> select instance_name from v$instance; INSTANCE_NAME--------------- ...
- Oracle ddl 和 dml 操作
ddl 操作 窗口设置用户权限的方法 Oracle的数据类型 按住Ctrl点击表名 ,可以鼠标操作 插入的数据需要满足创建表的检查 主表clazz删除数据从表设置级联也会一同删除 有约束也 ...
- Hive DDL及DML操作
一.修改表 增加/删除分区 语法结构 ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ...
- Spark+Hadoop+Hive集群上数据操作记录
[rc@vq18ptkh01 ~]$ hadoop fs -ls / drwxr-xr-x+ - jc_rc supergroup 0 2016-11-03 11:46 /dt [rc@vq18ptk ...
- hive从本地导入数据时出现「Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask」错误
现象 通过load data local导入本地文件时报无法导入的错误 hive> load data local inpath '/home/hadoop/out/mid_test.txt' ...
- Hive 编程之DDL、DML、UDF、Select总结
Hive的基本理论与安装可参看作者上一篇博文<Apache Hive 基本理论与安装指南>. 一.Hive命令行 所有的hive命令都可以通过hive命令行去执行,hive命令行中仍有许多 ...
- Apache Hive (七)Hive的DDL操作
转自:https://www.cnblogs.com/qingyunzong/p/8723271.html 库操作 1.创建库 语法结构 CREATE (DATABASE|SCHEMA) [IF NO ...
随机推荐
- Lua 常用遍历
b = {} , do b[i] = i end -- method one for i, v in pairs(b) do print (i, v) end -- method two for i, ...
- noip第3课作业
1. 求最大值 [问题描述] 输入三个数a,b,c,输出三个整数中的最大值 [样例输入] 10 20 30 [样例输出] 30 #include <iostream> using n ...
- 第81讲:Scala中List的构造和类型约束逆变、协变、下界详解
今天来学习一下scala中List的构造和类型约束等内容. 让我们来看一下代码 package scala.learn /** * @author zhang */abstract class Big ...
- 数据压缩之经典——哈夫曼编码(Huffman)
(笔记图片截图自课程Image and video processing: From Mars to Hollywood with a stop at the hospital的教学视频,使用时请注意 ...
- bootstrap4.2 导航搜索框
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- Linux命令行获取本机外网IP地址
问题: 服务器地址为net映射地址,本机ifconfig无法直接获取映射的公网地址. 方法: [root@TiaoBan- nidongde]# curl http://ifconfig.me 50. ...
- spring 框架整合mybatis的源码分析
问题:spring 在整合mybatis的时候,我们是看不见sqlSessionFactory,和sqlsession(sqlsessionTemplate 就是sqlsession的具体实现)的,这 ...
- Sql递归关联情况,With作为开头条件。
with Test_Recursion(Id,ParentId)AS(select Id,ParentId from [V_KPI_DetailsActivities] where ParentId ...
- 深度学习主机环境配置: Ubuntu16.04+GeForce GTX 1080+TensorFlow
接上文<深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0>,我们继续来安装 TensorFlow,使其支持GeForce GTX 1080显卡 ...
- Ubuntu16.04安装NVIDIA显卡驱动
1.下载官方驱动程序 http://www.geforce.cn/drivers 如果我们直接安装驱动的话,往往会报错:ERROR: The Nouveau kernel driver is curr ...