Install Greenplum OSS on Ubuntu
About Greenplum Database
Greenplum Database is an MPP SQL Database based on PostgreSQL. Its used in production in hundreds of large corporations and government agencies around the world and including the open source has over thousands of deployments globally.
Greenplum Database scales to multi-petabyte data sizes with ease and allows a cluster of powerful servers to work together to provide a single SQL interface to the data.
In addition to using SQL for analyzing structured data, Greenplum provides modules and extensions on top of the PostgreSQL abstractions for in database machine learning and AI, Geospatial analytics, Text Search (with Apache Solr) and Text Analytics with Python and Java, and the ability to create user-defined functions with Python, R, Java, Perl, C or C++.
Greenplum Database Ubuntu Distribution
Greenplum Database is the only open source product in its category that has a large install base, and now with the release of Greenplum Database 5.3, Ready to Install binaries are hosted for the Ubuntu Operating System to make installation and deployment easy.
Ubuntu is a popular operating system in cloud-native environments and is based on the very well respected Debian Linux distribution.
In this article, I will demonstrate how to install the Open Source Greenplum Database binaries on the Ubuntu Operating System.
Greenplum Database binaries for Ubuntu are hosted on the Personal Package Archive system, which allows the community to contribute readily to install packages that can be installed from any internet connected system.
So let’s get right to it!
Greenplum OSS on Ubuntu Installation Instructions
First, ensure you have a supported Ubuntu OS version. At the time of this writing, Ubuntu builds of Greenplum are built for the 16.04 LTS (long-term support) release version of Ubuntu. Check the PPA page, for current information about which OS version is available.
Add the Greenplum PPA repository to your Ubuntu System, like this:
sudo add-apt-repository ppa:greenplum/db
Update your Ubuntu system to retrieve information from the recently added repository, like this:
sudo apt-get update
Install the Greenplum Database software, like this:
sudo apt-get install greenplum-db-oss
The above command will install the Greenplum Database software and any required dependencies on the system automatically and put the resulting software in /opt/gpdb.
Load Greenplum Database software into your environment with the following command:
$ . /opt/gpdb/greenplum_path.sh
$ which gpssh
/opt/gpdb/bin/gpssh
You can see the software is on the path by testing using the which command as above. Now you can copy a Greenplum cluster configuration file template into your local directory for editing like this:
cp $GPHOME/docs/cli_help/gpconfigs/gpinitsystem_singlenode .
Edit gpinitsystem Configuration File
The following edits can be made for the most simple cluster configuration running locally.
Create this file and put only your hostname into the file:
MACHINE_LIST_FILE=./hostlist_singlenode
Update this line to have a directory you want to use for primaries for example:
declare -a DATA_DIRECTORY=(/gpdata1 /gpdata2)
declare -a DATA_DIRECTORY=(/home/inovick/primary /home/inovick/primary)
And make sure the directory mentioned above exists.
Update this line to have the hostname of your machine, in my case, the hostname is ‘ubuntu’:
MASTER_HOSTNAME=hostname_of_machine
MASTER_HOSTNAME=ubuntu
Update the master data directory entry in the file and ensure it exists by making the directory:
MASTER_DIRECTORY=/home/inovick/master
That’s enough to get the database initialized and up running, so close the file and let’s initialize the cluster. We will have a master segment instance and two primary segment instances with this configuration. In more advanced setups you would configure a standby master and segment mirrors on additional hosts, and the data would be automatically both sharded (distributed) between the primary segments and mirrored from primaries to mirrors.
Run gpinitsystem
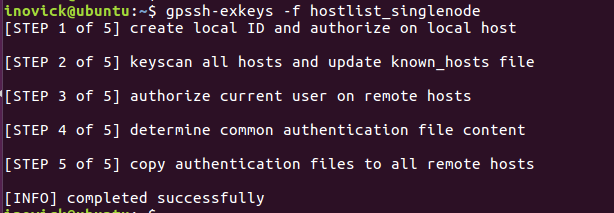
First, let’s make sure ssh keys are exchanged by running the following command. Screenshot from my system is shown below:
gpssh-exchkeys -f hostlist_singlenode
Ok, we need to start the cluster, let’s get started. Run the following command:
gpinitsystem -c gpinitsystem_singlenode
The utility will print out what its going to do and then ask you to confirm before proceeding. Here is an example below:

Once it finishes you are good to go, you can create a database, login and start doing queries and inserting data as shown below:

To really get the full benefit, you will want to do some of the following things:
- Allocate enough hardware to process large amounts of data in your cluster
- Check the official Greenplum Database documentation
- Watch some of the Greenplum Videos on YouTube
- Load a lot of data using the high speed parallel load of gpload or external tables with gpfdist, PXF, or S3
That’s it for this tutorial, enjoy Greenplum OSS on Ubuntu.
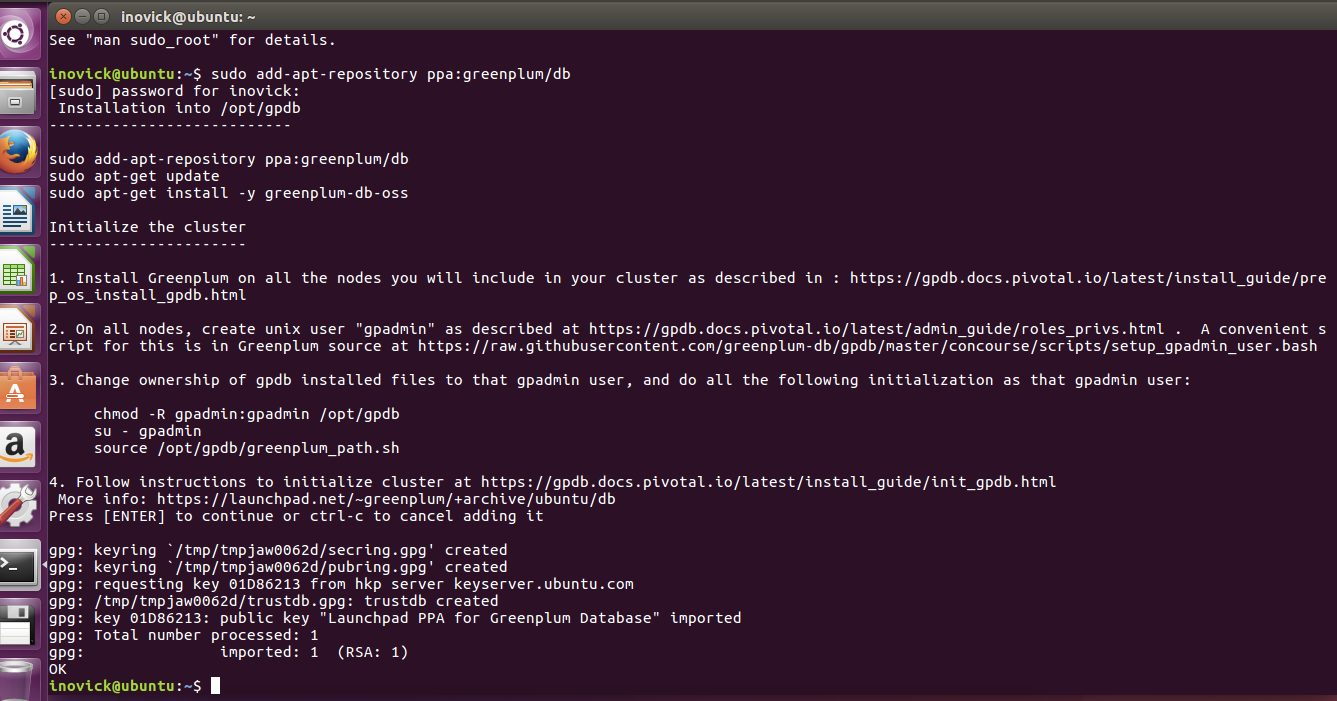
PPA description
Installation into /opt/gpdb
---------------------------
sudo apt-get install -y software-properties-common
sudo add-apt-repository ppa:greenplum/db
sudo apt-get update
sudo apt-get install -y greenplum-db-oss
Initialize the cluster
----------------------
1. Install Greenplum on all the nodes you will include in your cluster as described in : https://gpdb.docs.pivotal.io/latest/install_guide/prep_os_install_gpdb.html
2. On all nodes, create unix user "gpadmin" as described at https://gpdb.docs.pivotal.io/latest/admin_guide/roles_privs.html . A convenient script for this is in Greenplum source at https://raw.githubusercontent.com/greenplum-db/gpdb/master/concourse/scripts/setup_gpadmin_user.bash
3. Change ownership of gpdb installed files to the gpadmin user, and do all the following initialization as that gpadmin user:
chown -R gpadmin:gpadmin /opt/gpdb
su - gpadmin
source /opt/gpdb/greenplum_path.sh
4. Follow instructions to initialize cluster at https://gpdb.docs.pivotal.io/latest/install_guide/init_gpdb.html
Adding this PPA to your system
You can update your system with unsupported packages from this untrusted PPA by adding ppa:greenplum/db to your system's Software Sources. (Read about installing)
sudo add-apt-repository ppa:greenplum/db
sudo apt-get update
Install Greenplum OSS on Ubuntu的更多相关文章
- Install Google Pinyin on Ubuntu 14.04
Install Google Pinyin on Ubuntu 14.04 I've been spending more and more time on Ubuntu and I'm not us ...
- HOWTO install Oracle 11g on Ubuntu Linux 12.04 (Precise Pangolin) 64bits
安装了Ubuntu 12.04 64bit, 想在上面安装Oracle 11gr2,网上找了好多文档都没成功,最后完全参考了MordicusEtCubitus的文章. 成功安装的关键点:install ...
- Install a Redmine on Ubuntu system
# How to install a Redmine on Ubuntu system Ref to: https://www.linode.com/docs/applications/project ...
- Install LAMP Stack On Ubuntu 16.04
原文:http://www.unixmen.com/how-to-install-lamp-stack-on-ubuntu-16-04/ LAMP is a combination of operat ...
- How do you install Google Chrome on Ubuntu?
https://askubuntu.com/questions/510056/how-to-install-google-chrome sudo apt-get install chromium-br ...
- Install eclipse ns3 in ubuntu 14.04
1. NS3 install 参考NS3 tutorial即可. 2.eclipse 2.1下载 下载地址:http://www.eclipse.org/downloads/ ...
- install dns server on ubuntu
参考 CSDN/Ubuntu环境下安装和配置DNS服务器 在 Ubuntu 上安裝 DNS server Install BIND 9 on Ubuntu and Configure It for U ...
- [译]How to Install Node.js on Ubuntu 14.04 如何在ubuntu14.04上安装node.js
原文链接为 http://www.hostingadvice.com/how-to/install-nodejs-ubuntu-14-04/ 由作者Jacob Nicholson 发表于October ...
- Install latest R for ubuntu
### delete old version rm -rf /usr/local/lib/R /usr/lib/R ~/**/R sudo apt-get autoremove rstudio sud ...
随机推荐
- 高维数据的高速近期邻算法FLANN
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jinxueliu31/article/details/37768995 高维数据的高速近期邻算法FL ...
- pip报错解决:EnvironmentError: mysql_config not found
centos7下使用python类库MySQL-python操作mysql.pip安装类库:pip install MySQL-python报错提示:mariadb EnvironmentError: ...
- InvokeRequired和Invoke(转)
C#中禁止跨线程直接访问控件,InvokeRequired是为了解决这个问题而产生的,当一个控件的InvokeRequired属性值为真时,说明有一个创建它以外的线程想访问它.此时它将会在内部调用ne ...
- makedepend: command not found(转)
makedepend: command not found 解决方案: 修改Makefile MAKEDEPEND=$(CC) -M 参考: When I set CROSS_COMPILE, `MA ...
- npm 切换淘宝源
由于Node官方模块仓库太慢,建议将模块仓库切换到阿里源 C:\workspace\angular>npm config set registry https://registry.npm.ta ...
- API - .after
.after() Insert content, specified by the parameter, after each element in the set of matched elemen ...
- sparkSQL以JDBC为数据源
一.环境准备 安装oracle后,创建测试表.数据: create table test ( username varchar2(32) primary key , password varchar2 ...
- PHP-不同Str 拼接方法性能对比
问题 在PHP中,有多种字符串拼接的方式可供选择,共有: 1 . , .= , sprintf, vprintf, join, implode 那么,那种才是最快的,或者那种才是最适合业务使用的,需要 ...
- hyperledger fabric各类节点及其故障分析 摘自https://www.cnblogs.com/preminem/p/8729781.html
hyperledger fabric各类节点及其故障分析 1.Client节点 client代表由最终用户操作的实体,它必须连接到某一个peer节点或者orderer节点上与区块链网络通信.客户端 ...
- ubuntu base make 未找到命令
引用:https://blog.csdn.net/fenglibing/article/details/7096556 1.先放入UBUNTU安装盘到光盘中: 2.再按顺序执行以下的命令: sudo ...