Python爬虫:抓取手机APP的数据
摘要
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。
1.抓取APP数据包
表单:

表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是。
另外必须加header,一开始我没有加header得到的是登录错误,所以要带上header信息。
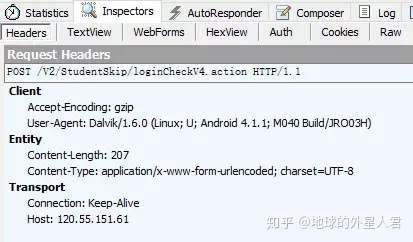
3.登录
登录代码:
import urllib2
from cookielib import CookieJar
loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action' headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
print loginResult
登录成功 会返回一串账号信息的json数据

和抓包时返回数据一样,证明登录成功
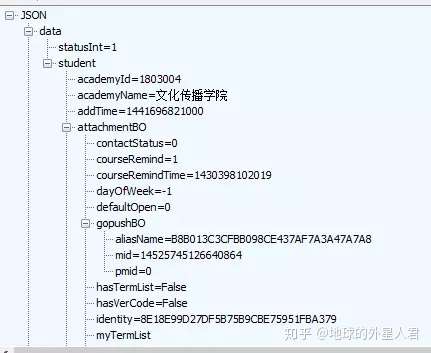
3.抓取数据
用同样方法得到话题的url和post参数
做法就和模拟登录网站一样。
下见最终代码,有主页获取和下拉加载更新。可以无限加载话题内容。
#!/usr/local/bin/python2.7 # -*- coding: utf8 -*- """
超级课程表话题抓取
""" import urllib2
from cookielib import CookieJar
import json
''' 读Json数据 ''' def fetch_data(json_data):
data = json_data['data']
timestampLong = data['timestampLong']
messageBO = data['messageBOs']
topicList = []
for each in messageBO:
topicDict = {}
if each.get('content', False):
topicDict['content'] = each['content']
topicDict['schoolName'] = each['schoolName']
topicDict['messageId'] = each['messageId']
topicDict['gender'] = each['studentBO']['gender']
topicDict['time'] = each['issueTime']
print each['schoolName'],each['content']
topicList.append(topicDict)
return timestampLong, topicList
''' 加载更多 ''' def load(timestamp, headers, url):
headers['Content-Length'] = '159'
loadData = 'timestamp=%s&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&' % timestamp
req = urllib2.Request(url, loadData, headers)
loadResult = opener.open(req).read()
loginStatus = json.loads(loadResult).get('status', False)
if loginStatus == 1:
print 'load successful!'
timestamp, topicList = fetch_data(json.loads(loadResult))
load(timestamp, headers, url)
else:
print 'load fail'
print loadResult
return False loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action' topicUrl = 'http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action' headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
''' ---登录部分--- '''
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
loginStatus = json.loads(loginResult).get('data', False)
if loginResult:
print 'login successful!' else:
print 'login fail'
print loginResult
''' ---获取话题--- '''
topicData = 'timestamp=0&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
headers['Content-Length'] = '147'
topicRequest = urllib2.Request(topicUrl, topicData, headers)
topicHtml = opener.open(topicRequest).read()
topicJson = json.loads(topicHtml)
topicStatus = topicJson.get('status', False)
print topicJson
if topicStatus == 1:
print 'fetch topic success!'
timestamp, topicList = fetch_data(topicJson)
load(timestamp, headers, topicUrl)
结果:

你想更深入了解学习Python知识体系,你可以看一下我们花费了一个多月整理了上百小时的几百个知识点体系内容:
【超全整理】《Python自动化全能开发从入门到精通》python基础教程笔记
Python爬虫:抓取手机APP的数据的更多相关文章
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Fiddler抓取手机APP程序数据包
1.下载并安装Fiddler 下载地址:https://www.telerik.com/download/fiddler 2.设置Fiddler可监听远程通讯 前提条件:需要监听的手机和Fiddler ...
- Python3爬虫:利用Fidder抓取手机APP的数据
1.什么是Fiddler? Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,ht ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 使用Fiddler抓取手机APP数据包--360WIFI
使用Fiddler抓取手机APP流量--360WIFI 操作步骤:1.打开Fiddler,Tools-Fiddler Options-Connections,勾选Allow remote comput ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- jmeter旅程第一站:Jmeter抓包浏览器或者抓取手机app的包
学习jmeter?从实际出发,我也是一个初学者,会优先考虑先用来做一些简单的抓包.接口测试,在实践的过程中学习jmeter用途.那么接下来,这篇文章我会以jmeter抓包开启我的jmeter旅程. 这 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- Codeforces Round #320 (Div. 2) [Bayan Thanks-Round] D "Or" Game 枚举+前缀后缀
D. "Or" Game ...
- Hierarchyviewer定位Android图片资源的研究
之前就在研究能否通过Hierarchyviewer找到所有所见的资源 在导入Hierarchyviewer之后才发现绑定在View上的drawable与实际的图片资源之间并没有维系着一个固定的对应关系 ...
- 【Dairy】2016.10.30 BirthdayParty
今天又有人生日耶,鹏哥和骥哥两兄弟,Happy Birthday 开始听到这件事,我傻逼的想了一下,咦,这两人这么有缘,同一天生日...脑抽了... 小胖犇极缓音调来了首烟花易冷,劲啊! 发张什么图呢 ...
- Java 基础 —— enum
枚举的遍历: enum Suit { CLUB, DIAMOND, HEART, SPADE } Collection<Suit> suitTypes = Arrays.asList(Su ...
- 第七周 Leetcode 466. Count The Repetitions 倍增DP (HARD)
Leetcode 466 直接给出DP方程 dp[i][k]=dp[i][k-1]+dp[(i+dp[i][k-1])%len1][k-1]; dp[i][k]表示从字符串s1的第i位开始匹配2^k个 ...
- linux下的zookeeper启动
zookeeper的安装目录:/usr/local/zookeeper-3.4.6/bin/zkServer.sh; 配置文件路径:../conf/zoo.cfg 端口 :2181: ZooKeepe ...
- KeepAlived的介绍
KeepAlived介绍 keepalived keepalived是一个类似于layer3, 4 & 7交换机制的软件,也就是我们平时说的第3层.第4层和第7层交换. Keepalived的 ...
- bzoj 1671: [Usaco2005 Dec]Knights of Ni 骑士【bfs】
bfs预处理出每个点s和t的距离d1和d2(无法到达标为inf),然后在若干灌木丛格子(x,y)里取min(d1[x][y]+d2[x][y]) /* 0:贝茜可以通过的空地 1:由于各种原因而不可通 ...
- P3043 [USACO12JAN]牛联盟Bovine Alliance(并查集)
P3043 [USACO12JAN]牛联盟Bovine Alliance 题目描述 Bessie and her bovine pals from nearby farms have finally ...
- SP1043 GSS1 - Can you answer these queries I(猫树)
给出了序列A[1],A[2],…,A[N]. (a[i]≤15007,1≤N≤50000).查询定义如下: 查询(x,y)=max{a[i]+a[i+1]+...+a[j]:x≤i≤j≤y}. 给定M ...