Python爬虫:抓取手机APP的数据
摘要
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。
1.抓取APP数据包
表单:

表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是。
另外必须加header,一开始我没有加header得到的是登录错误,所以要带上header信息。
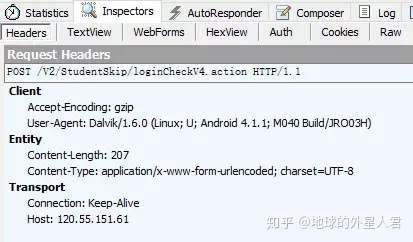
3.登录
登录代码:
import urllib2
from cookielib import CookieJar
loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action' headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
print loginResult
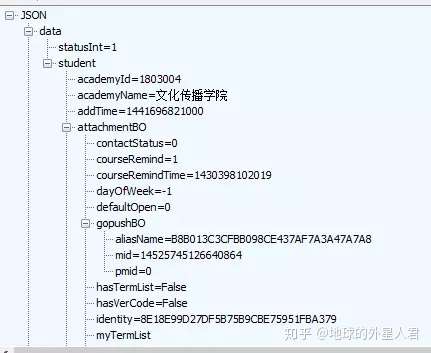
登录成功 会返回一串账号信息的json数据

和抓包时返回数据一样,证明登录成功
3.抓取数据
用同样方法得到话题的url和post参数
做法就和模拟登录网站一样。
下见最终代码,有主页获取和下拉加载更新。可以无限加载话题内容。
#!/usr/local/bin/python2.7 # -*- coding: utf8 -*- """
超级课程表话题抓取
""" import urllib2
from cookielib import CookieJar
import json
''' 读Json数据 ''' def fetch_data(json_data):
data = json_data['data']
timestampLong = data['timestampLong']
messageBO = data['messageBOs']
topicList = []
for each in messageBO:
topicDict = {}
if each.get('content', False):
topicDict['content'] = each['content']
topicDict['schoolName'] = each['schoolName']
topicDict['messageId'] = each['messageId']
topicDict['gender'] = each['studentBO']['gender']
topicDict['time'] = each['issueTime']
print each['schoolName'],each['content']
topicList.append(topicDict)
return timestampLong, topicList
''' 加载更多 ''' def load(timestamp, headers, url):
headers['Content-Length'] = '159'
loadData = 'timestamp=%s&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&' % timestamp
req = urllib2.Request(url, loadData, headers)
loadResult = opener.open(req).read()
loginStatus = json.loads(loadResult).get('status', False)
if loginStatus == 1:
print 'load successful!'
timestamp, topicList = fetch_data(json.loads(loadResult))
load(timestamp, headers, url)
else:
print 'load fail'
print loadResult
return False loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action' topicUrl = 'http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action' headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
''' ---登录部分--- '''
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
loginStatus = json.loads(loginResult).get('data', False)
if loginResult:
print 'login successful!' else:
print 'login fail'
print loginResult
''' ---获取话题--- '''
topicData = 'timestamp=0&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
headers['Content-Length'] = '147'
topicRequest = urllib2.Request(topicUrl, topicData, headers)
topicHtml = opener.open(topicRequest).read()
topicJson = json.loads(topicHtml)
topicStatus = topicJson.get('status', False)
print topicJson
if topicStatus == 1:
print 'fetch topic success!'
timestamp, topicList = fetch_data(topicJson)
load(timestamp, headers, topicUrl)
结果:

你想更深入了解学习Python知识体系,你可以看一下我们花费了一个多月整理了上百小时的几百个知识点体系内容:
【超全整理】《Python自动化全能开发从入门到精通》python基础教程笔记
Python爬虫:抓取手机APP的数据的更多相关文章
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Fiddler抓取手机APP程序数据包
1.下载并安装Fiddler 下载地址:https://www.telerik.com/download/fiddler 2.设置Fiddler可监听远程通讯 前提条件:需要监听的手机和Fiddler ...
- Python3爬虫:利用Fidder抓取手机APP的数据
1.什么是Fiddler? Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,ht ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 使用Fiddler抓取手机APP数据包--360WIFI
使用Fiddler抓取手机APP流量--360WIFI 操作步骤:1.打开Fiddler,Tools-Fiddler Options-Connections,勾选Allow remote comput ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- jmeter旅程第一站:Jmeter抓包浏览器或者抓取手机app的包
学习jmeter?从实际出发,我也是一个初学者,会优先考虑先用来做一些简单的抓包.接口测试,在实践的过程中学习jmeter用途.那么接下来,这篇文章我会以jmeter抓包开启我的jmeter旅程. 这 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- Lein droid
最近尝试使用Clojure,发现有个Lein droid的项目可以方便的在android下使用Clojure. http://clojure-android.info/#get-started 尝试了 ...
- HDU5834Magic boy Bi Luo with his excited tree 树形dp
分析:典型的两遍dfs树形dp,先统计到子树的,再统计从祖先来的,dp[i][0]代表从从子树回来的最大值,dp[i][1]代表不回来,id[i]记录从i开始到哪不回来 吐槽:赛场上想到了状态,但是不 ...
- Cocos2d-x 3.2编译生成Android程序出错Error running command, return code: 2的解决方法
用Cocos2d-x 3.2正式版创建项目,结果使用cocos compile -p android编译生成APK程序,结果悲剧了,出现以下错误. Android NDK: Invalid APP_S ...
- 洛谷 P1314 聪明的质监员 —— 二分
题目:https://www.luogu.org/problemnew/show/P1314 显然就是二分那个标准: 当然不能每个区间从头到尾算答案,所以要先算出每个位置被算了几次: 不知为何自己第一 ...
- 关于mysql的索引原理与慢查询优化
大多情况下我们都知道加索引能提高查询效率,但是应该如何加索引呢?索引的顺序如何呢? 大家看一下下面的sql语句(在没有看下面的优化的方法之前)应该如何优化加索引以及优化sql语句: 1.select ...
- CentOS下实现Flask + Virtualenv + uWSGI + Nginx部署
一.项目简介 在本文中,将一步一步搭建一个简单的Flask + Virtualenv + uWSGI + Nginx 架构的Web服务,可以作为新手的学习也可作为记录备忘. 如果你安装好了环境并有一定 ...
- Hibernate的表之间的关系
表:A.B 一对多关系:A中的一个字段的记录(主键)引用B中的多个记录(外键) 多对一关系:A中的一个字段的记录(外键)引用B中的一个记录(主键) 一对一关系:A.B两个表的关联字段都是主键 多对多关 ...
- 0621补-MVC的基础整理
包括:Model-模型.view-视图.Controller-控制器. 特点: 将功能强制分成两个部分,显示html文件,和逻辑PHP文件: 要求浏览器请求负责功能的PHP逻辑文件,该PHP逻辑文件, ...
- 在数据库中生成txt文件到网络驱动器中(计算机直接创建的网络驱动器在sql server中没有被找到)
环境:sql server 2008 一.创建网络驱动器映射 语法:exec master..xp_cmdshell 'net use Z: \\ip地址\网络路径 密码 /user:用户名' 例如: ...
- bzoj 1016: [JSOI2008]最小生成树计数【dfs+克鲁斯卡尔】
有一个性质就是组成最小生成树总边权值的若干边权总是相等的 这意味着按边权排序后在权值相同的一段区间内的边能被选入最小生成树的条数是固定的 所以先随便求一个最小生成树,把每段的入选边数记录下来 然后对于 ...