(转)全文检索技术学习(二)——配置Lucene的开发环境
http://blog.csdn.net/yerenyuan_pku/article/details/72589380
Lucene下载
Lucene是开发全文检索功能的工具包,可从官方网站http://lucene.apache.org/下载,这里我下载的是Lucene4.10.3,所以后续有关Lucene的讲解都是基于这个版本的。下载之后解压。
注意:Lucene4.10.3这个版本要求JDK的版本至少是1.7。比较幸运的是,本人使用的JDK的版本是1.8。
Lucene的开发环境配置好之后,接下来我就写一个例子来使用Lucene实现全文检索。
创建索引库
使用IndexWriter对象创建索引。
实现步骤
- 创建一个普通的java工程,并导入jar包。
- 创建一个IndexWriter对象。
- 1)使用Directory对象指定索引库的存放位置。
- 2)指定一个分析器,对文档内容进行分析。
- 创建Document对象。
- 创建Field对象,将Field添加到Document对象中。
- 使用IndexWriter对象将Document对象写入索引库,此过程进行索引创建。并将索引和Document对象写入索引库。
- 关闭IndexWriter对象。
以上步骤说完之后,大家可能一头雾水,没关系,后面会用代码进行解释。还有我们创建完一个普通的java工程之后,要用到Lucene这个技术,必然要导入实现全文检索的类库,导入的jar包有:
- Lucene包
- lucene-core-4.10.3.jar

- lucene-analyzers-common-4.10.3.jar

- lucene-core-4.10.3.jar
- 其它(须读取文件)
- commons-io-2.4.jar
- junit-4.9.jar(该包可不用导入,因为Eclipse本身就自带了)
常用域分析
我们可对常用域从以下几个方面分析:
- 是否分析:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
- 是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。比如:商品名称、商品简介分析后进行索引,商品id、订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
- 是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取。比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
- 是否存储的标准:是否要将内容展示给用户。
常用域如表所示: 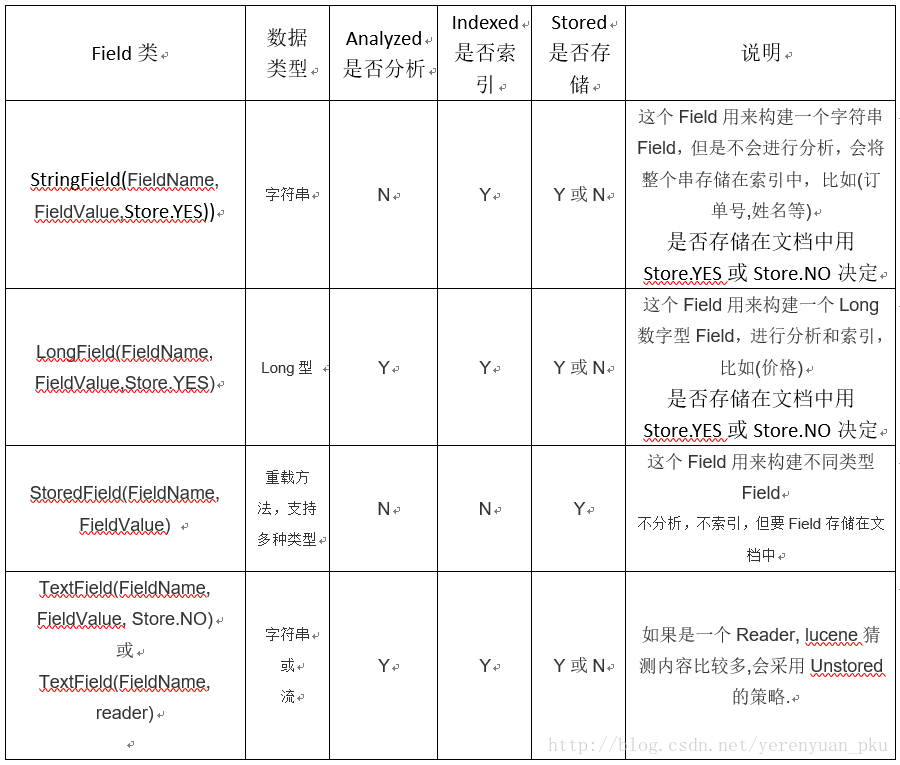
创建索引库——代码实现
在src目录下新建一个com.itheima.luence包,然后在该包下编写一个单元测试类——LuenceFirst.java,紧接着在该类中编写一个方法创建索引库。
public class LuenceFirst {
@Test
public void createIndex() throws IOException {
// 1、指定索引库存放的位置,它可以是内存也可以是磁盘
// 索引库保存到内存中,一般不用
// Directory directory = new RAMDirectory();
// 保存到磁盘上
Directory directory = FSDirectory.open(new File("f:\\temp\\index"));
// 2、创建一个IndexWriter对象,需要一个分析器对象(分词的过程是由分析器对象来实现的)。
Analyzer analyzer = new StandardAnalyzer(); // 标准分析器
// 参数1:当前使用lucene的版本号,第二个参数:分析器对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
// 参数1:索引库存放的路径,参数2:配置信息,其中包含分析器对象
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 3、获得原始文档,使用IO流读取文本文件
File docPath = new File("F:\\searchsource");
for (File f : docPath.listFiles()) {
// 取文件名
String fileName = f.getName();
// 取文件路径
String filePath = f.getPath();
// 文件的内容(将文件读到一个字符串里面)
String fileContent = FileUtils.readFileToString(f);
// 文件的大小
long fileSize = FileUtils.sizeOf(f);
// 4、创建文档对象
Document document = new Document();
// 创建域
// 参数1:域的名称(可随便起),参数2:域的内容,参数3:是否存储
TextField fileNameField = new TextField("name", fileName, Store.YES);
StoredField fieldPathField = new StoredField("path", filePath);
TextField fileContentField = new TextField("content", fileContent, Store.NO);
LongField fileSizeField = new LongField("size", fileSize, Store.YES);
// 5、向文档中添加域,这个域是有说道的,域即文件属性——文件名、文件路径、文件内容、文件大小等
document.add(fileNameField);
document.add(fieldPathField);
document.add(fileContentField);
document.add(fileSizeField);
// 6、将文档对象写入索引库
indexWriter.addDocument(document);
}
// 7、关闭IndexWriter对象
indexWriter.close();
}
}- 1
运行以上方法,可发现F:\temp\index目录下创建了一个索引库,如下: 
查询索引库
实现步骤
- 创建一个Directory对象,也就是索引库存放的位置。
- 创建一个IndexReader对象,需要指定Directory对象。
- 创建一个Indexsearcher对象,需要指定IndexReader对象。
- 创建一个TermQuery对象,指定查询的域和查询的关键词。
- 执行查询。
- 返回查询结果,遍历查询结果并输出。
- 关闭IndexReader对象。
查询索引库的实现步骤虽然写得已明明白白了,我相信不少初学者仍然摸不着北,没关系,只要你后面用代码实现查询索引库了,回过头来,你就会觉得也并没那么难理解嘛!在用代码实现查询索引库之前,我们还得知道IndexSearcher类与TopDocs类的常用属性或方法。
IndexSearcher类的常用搜索方法
IndexSearcher类的常用搜索方法如下: 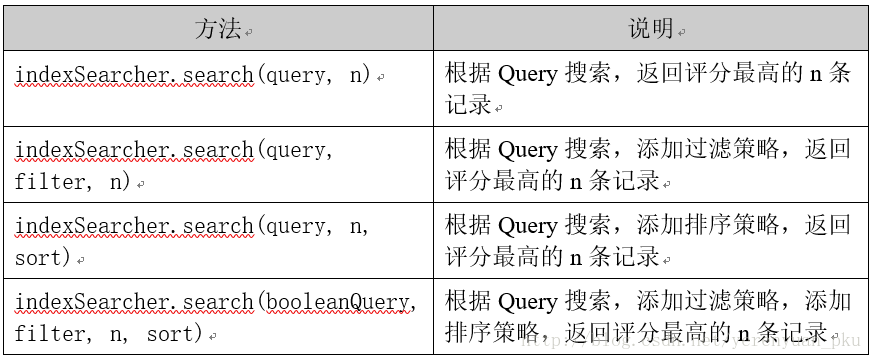
注意:search方法需要指定匹配记录数量n。这个匹配记录数量到底该怎样理解呢?假设n=10,用大白话说就是如果我们搜索结果有10万条,这10万条不应该都返回来,因为我们用不了那么多,这时就要把它的范围缩小,即便有10万条,也只让其只返回10条。
TopDocs常用属性
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下: 
* TopDocs.totalHits:是匹配索引库中所有记录的数量。
* TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法中指定的参数n。
查询索引库——代码实现
在LuenceFirst类中编写一个方法查询索引库,如下:
public class LuenceFirst {
@Test
public void searchIndex() throws IOException {
// 1、指定索引库存放的位置
Directory directory = FSDirectory.open(new File("f:\\temp\\index"));
// 2、使用IndexReader对象打开索引库
IndexReader indexReader = DirectoryReader.open(directory);
// 3、创建一个IndexSearcher对象,其构造方法需要一个IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 4、创建一个查询对象,需要指定查询的域及查询的关键字(关键词)
// term的参数1:要搜索的域,参数2:要搜索的关键字
Query query = new TermQuery(new Term("name", "apache"));
// 参数1:查询条件,参数2:查询结果返回的最大值
TopDocs topDocs = indexSearcher.search(query, 10);
// 5、取查询结果
// 取查询结果的总记录数
System.out.println("查询结果总记录数:" + topDocs.totalHits);
// 6、遍历查询结果,并打印
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// 取文档id
int id = scoreDoc.doc;
// 从索引库中取文档对象
Document document = indexSearcher.doc(id);
// 取属性
System.out.println(document.get("name"));
System.out.println(document.get("size"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
}
// 7、关闭IndexReader对象
indexReader.close();
}
}运行以上方法,Eclipse控制台打印: 
总结
要编写代码实现查询索引库,可参考下图来编写,这样大家脑子不会一团糟。 
(转)全文检索技术学习(二)——配置Lucene的开发环境的更多相关文章
- [eShopOnContainers 学习系列] - 02 - vs 2017 开发环境配置
[eShopOnContainers 学习系列] - 02 - vs 2017 开发环境配置 https://github.com/dotnet-architecture/eShopOnContain ...
- GO学习-(3) VS Code配置Go语言开发环境
VS Code配置Go语言开发环境 VS Code配置Go语言开发环境 说在前面的话,Go语言是采用UTF8编码的,理论上使用任何文本编辑器都能做Go语言开发.大家可以根据自己的喜好自行选择.编辑器/ ...
- 联盛德 HLK-W806 (二): Win10下的开发环境配置, 编译和烧录说明
目录 联盛德 HLK-W806 (一): Ubuntu20.04下的开发环境配置, 编译和烧录说明 联盛德 HLK-W806 (二): Win10下的开发环境配置, 编译和烧录说明 联盛德 HLK-W ...
- mac下配置Node.js开发环境、express安装、创建项目
mac下配置Node.js开发环境.express安装.创建项目 一.node.js的安装 去官网下载对应的平台版本就可以了,https://nodejs.org 二.express安装 sudo n ...
- VS、C#配置R语言开发环境
R语言学习笔记(一)——在Vs.C#中配置R语言开发环境. 最近在学习小众的R语言,所以将遇到的问题记录下来供大家参考,不足之处欢迎大家交流指正. 至于R语言的介绍就不多说了,它集成了复杂的数学算法, ...
- 一网成擒全端涵盖,在不同架构(Intel x86/Apple m1 silicon)不同开发平台(Win10/Win11/Mac/Ubuntu)上安装配置Python3.10开发环境
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_200 时光荏苒,过隙白驹,即将进入2022年,著名敏捷开发语言Python也放出了3.10最终版,本次我们来展示一下在不同的系统和 ...
- EditPlus+VisualStudio配置VC简易开发环境环境
对于C++开发, 我想在Windows下大家用的最多的应该是MS的VC++.但其强大的功能背后却有着"启动速度慢","占用资源多"的缺点,尤其是VS后 ...
- Ubuntu下配置C/C++开发环境
在 Ubuntu 下配置 C/C++ 开发环境 转自:白巴的临时空间 Submitted by 白巴 on 2009-04-27 19:52:12. 学习笔记 虽然 Ubuntu 的版本已经是9.04 ...
- 在VMware虚拟机中配置DOS汇编开发环境!!
操作系统:win7 32位 DOS环境:DosBox 下载:http://www.dosbox.com/ 选择当前适合自己版本,下载就可以了. 汇编编译器:MASM 5.0 下载:http://do ...
随机推荐
- 我怎么在AD里面找到已经改名的Administrator账户?
近期有博友问我一个问题,他是一个企业里面的IT管理员,他非常苦恼.他是一个新手,之前管理员交接的时候,没有交接更改的管理员username和password.他如今不知道哪个才是系统之前内置的admi ...
- python搭建web server
假设你急需一个简单的Web Server,但你又不想去下载并安装那些复杂的HTTP服务程序,比方:Apache,ISS等.那么, Python 可能帮助你.使用Python能够完毕一个简单的内建 HT ...
- 读书笔记:Information Architecture for the World Wide Web, 3rd Edition 北极熊 第一部分 1-3
Introducing Information Architecture 信息架构简介 Chapter 1 Defining Information Architecture 信息架构的意义(我们盖房 ...
- 使用MyBatis Generator自动生成MyBatis的代码
这两天需要用到MyBatis的代码自动生成的功能,由于MyBatis属于一种半自动的ORM框架,所以主要的工作就是配置Mapping映射文件,但是由于手写映射文件很容易出错,所以可利用MyBatis生 ...
- jdk、jre、spring、java ee、java se
1 java se.java ee和java me 这三个是java的标准.java se是根本,java ee建立在java se上,用于server.java me是java se的子集,用于终端 ...
- OSS与文件系统的对比
基本概念介绍_开发指南_对象存储 OSS-阿里云 https://help.aliyun.com/document_detail/31827.html 强一致性 Object 操作在 OSS 上具有 ...
- 01排序的Java实现
比赛描写叙述: 的个数同样时再按ASCII码值排序. 输入: 个字符. 输出: 串的顺序.使得串按基本描写叙述的方式排序. 例子输入: 例子输出: 被AC的代码例如以下: import java.ut ...
- Android6.0源码分析之录音功能(一)【转】
本文转载自:http://blog.csdn.net/zrf1335348191/article/details/54949549 从现在开始一周时间研究录音,下周出来一个完整的博客,监督,激励!!! ...
- 蓝书2.2 KMP算法
T1 Radio Transmission bzoj 1355 题目大意: 一个字符串,它是由某个字符串不断自我连接形成的 但是这个字符串是不确定的,现在只想知道它的最短长度是多少 思路: kmp 输 ...
- luogu 3388 【模板】割点(割顶)
点双. #include<iostream> #include<cstdio> #include<cstdlib> #include<cstring> ...