通过爬虫爬取四川省公共资源交易平台上最近的招标信息 --- URLConnection
通过爬虫爬取公共资源交易平台(四川省)最近的招标信息
一:引入JSON的相关的依赖
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
二:通过请求的url获取URLConnection连接
package com.svse.pachong;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;import org.apache.log4j.Logger;
/**
* 通过请求的url获取URLConnection连接
* @author lenovo
* @date 2019年1月22日
* description:
*/
public class open_url_test {public static Logger logger = Logger.getLogger(open_url_test.class);
public boolean openurl(String url_infor) throws Exception{
URL url = new URL(url_infor);
// 连接类的父类,抽象类
URLConnection urlConnection = url.openConnection();// http的连接类
HttpURLConnection httpURLConnection = (HttpURLConnection) urlConnection;/* 设定请求的方法,默认是GET(对于知识库的附件服务器必须是GET,如果是POST会返回405。
流程附件迁移功能里面必须是POST,有所区分。)*/
httpURLConnection.setRequestMethod("GET");
// 设置字符编码 httpURLConnection.setRequestProperty("Charset", "UTF-8");
// 打开到此 URL引用的资源的通信链接(如果尚未建立这样的连接)。
int code = httpURLConnection.getResponseCode();
System.out.println("code:"+code); //连接成功 200
try {
InputStream inputStream = httpURLConnection.getInputStream();
System.out.println("连接成功");
logger.info("打开"+url_infor+"成功!");
return true;
}catch (Exception exception){
logger.info("打开"+url_infor+"失败!");
return false;
}
}
}
三:通过爬取的url解析想要的数据,并以json的格式返回
package com.svse.pachong;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.nio.charset.Charset;
import net.sf.json.JSONException;
import net.sf.json.JSONObject;/**
* 通过爬取的url解析想要的数据,并以json的格式返回
* @param urlString 需要爬取的网站url路径
* @return 返回json结果的数据
* @throws IOException
* @throws JSONException
*/
public class readData {public static JSONObject readData(String urlString) throws IOException, JSONException{
InputStream is = new URL(urlString).openStream();
try {
BufferedReader rd = new BufferedReader(new InputStreamReader(is, Charset.forName("UTF-8")));
StringBuilder sb = new StringBuilder();
int cp;
while ((cp = rd.read()) != -1) {
sb.append((char) cp);
}
String jsonText = sb.toString();
JSONObject json = JSONObject.fromObject(jsonText);
return json;
} finally {
is.close();
}
}
}
四:爬取入口
package com.svse.pachong;
import java.io.IOException;
import net.sf.json.JSONArray;
import net.sf.json.JSONException;
import net.sf.json.JSONObject;/**
* 爬取的入口
* @author lenovo
* @date 2019年1月22日
* description:
*/
public class Main {static String urlString = "http://www.scggzy.gov.cn/Info/GetInfoListNew?keywords=×=4×Start=×End=&province=&area=&businessType=&informationType=&industryType=&page=1&parm=1534929604640";
@SuppressWarnings("static-access")
public static void main(String[] args) {open_url_test oUrl = new open_url_test();
try {
if (oUrl.openurl(urlString)) {
readData rData = new readData();
JSONObject json = rData.readData(urlString);
JSONObject ob=JSONObject.fromObject(json);String data=ob.get("data").toString(); //JSONObject 转 String
data="["+data.substring(1,data.length()-1)+"]";JSONArray json2=JSONArray.fromObject(data); //String 转 JSONArray
for (int i = 0; i < 10; i++) {
JSONObject jsonObject = (JSONObject) json2.get(i);
System.out.println("--------------------------------------------");
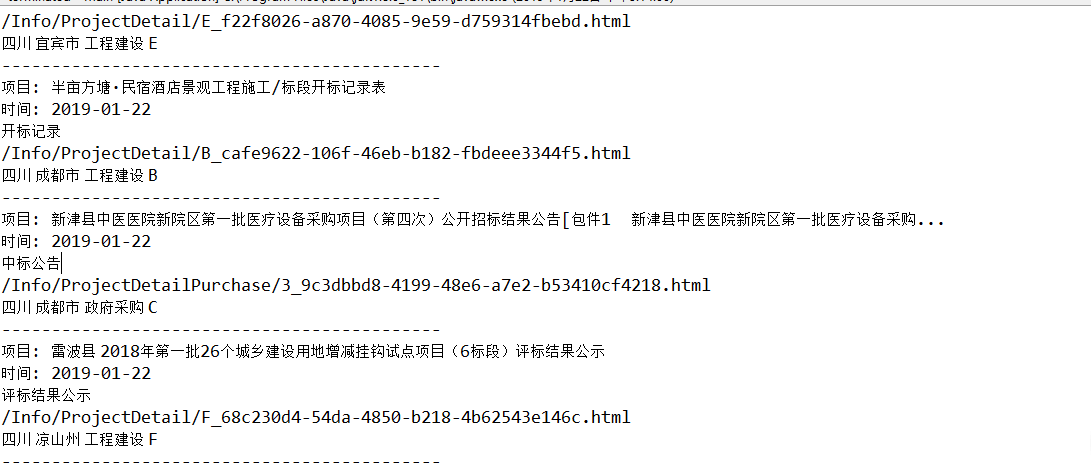
System.out.println("项目: "+jsonObject.get("Title"));
System.out.println("时间: "+jsonObject.get("CreateDateStr"));
System.out.println(jsonObject.get("TableName"));
System.out.println(jsonObject.get("Link"));
System.out.println( jsonObject.get("province") +" "+jsonObject.get("username")+" "+jsonObject.get("businessType")+" "+jsonObject.get("NoticeType"));
}
}else{
System.out.println("解析数据失败!");
}
} catch (JSONException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}}
四:测试结果
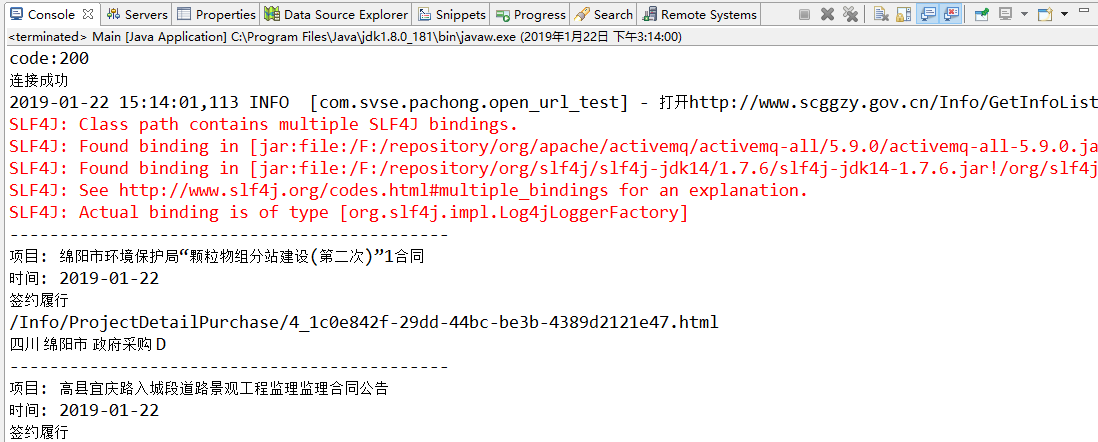

至此,整个爬取的任务就结束了!
通过爬虫爬取四川省公共资源交易平台上最近的招标信息 --- URLConnection的更多相关文章
- python爬虫爬取京东、淘宝、苏宁上华为P20购买评论
爬虫爬取京东.淘宝.苏宁上华为P20购买评论 1.使用软件 Anaconda3 2.代码截图 三个网站代码大同小异,因此只展示一个 3.结果(部分) 京东 淘宝 苏宁 4.分析 这三个网站上的评论数据 ...
- Java爬虫爬取网站电影下载链接
之前有看过一段时间爬虫,了解了爬虫的原理,以及一些实现的方法,本项目完成于半年前,一直放在那里,现在和大家分享出来. 网络爬虫简单的原理就是把程序想象成为一个小虫子,一旦进去了一个大门,这个小虫子就像 ...
- 如何使用robots禁止各大搜索引擎爬虫爬取网站
ps:由于公司网站配置的测试环境被百度爬虫抓取,干扰了线上正常环境的使用,刚好看到每次搜索淘宝时,都会有一句由于robots.txt文件存在限制指令无法提供内容描述,于是便去学习了一波 1.原来一般来 ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- python网络爬虫(10)分布式爬虫爬取静态数据
目的意义 爬虫应该能够快速高效的完成数据爬取和分析任务.使用多个进程协同完成一个任务,提高了数据爬取的效率. 以百度百科的一条为起点,抓取百度百科2000左右词条数据. 说明 参阅模仿了:https: ...
随机推荐
- [Bzoj4540][Hnoi2016] 序列(莫队 + ST表 + 单调队列)
4540: [Hnoi2016]序列 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 1567 Solved: 718[Submit][Status] ...
- Codeforces Round Edu 36
A.B.C 略 D(dfs+强连通分量) 题意: 给出一个n(n<=500)点m(m<=100000)边的有向图,问能否通过删去一条边使得该图无环. 分析: 最简单的想法就是枚举一条边删去 ...
- Java开发笔记(一百)线程同步synchronized
多个线程一起办事固然能够加快处理速度,但是也带来一个问题:两个线程同时争抢某个资源时该怎么办?看来资源共享的另一面便是资源冲突,正所谓鱼与熊掌不可兼得,系统岂能让多线程这项技术专占好处?果然是有利必有 ...
- 白话空间统计之四:P值和Z值(上):零如果
本来今天想要讲讲软件操作的,后来发现好像还有好几个重要的指标没有说,干脆等所有说完在讲操作吧.否则操作出来的结果会发现大量的"不明觉厉". 首先是空间统计里面非常神奇的两个值:P值 ...
- Office EXCEL 复制粘贴 变成 #value,#REF!,#DIV怎么办
这些都是由于相对引用造成的,如下所示,我鼠标点进去之后变成了I10/L10,当数字和文字或空单元格进行加减乘除的运算就会出现这种问题 使用选择性粘贴,只粘贴数值即可.
- D广搜
<span style="color:#330099;">/* D - 广搜 基础 Time Limit:1000MS Memory Limit:30000KB 64b ...
- 报错:Binary XML file line #7: Error inflating class android.support.v7.widget.RecyclerView
近期学习RecyclerView,使用eclipse引用RecyclerView.编写完demo后编译没有问题,一执行就挂掉,错误例如以下: 07-22 23:05:34.553: D/Android ...
- 2016/04/26 权限 数据库mydb2 五个表 分别是 1,用户 2,角色 3,权限 4,用户对应的角色 5,角色对应的权限
权限: 1,后台分配角色 角色对应权限 2,各用户通过登录页面登录 查看到各自的权限 五个页面 加引入一个jquery-1.11.2.min.js 1,guanli.php ...
- while语句字符串的基本操作
1,编码:对现在通用文字编码成计算机文字,便于储存,传递,交流. 最早的计算机编码是ACSII美国人创建的,包含英文字母,数字,以及特殊符号.总共是128个码位:2**7,因为计算机的底层只能识别:& ...
- 问题:IIS部署 MVC项目 (autofac) 错误解决
http://www.cnblogs.com/yelaiju/p/3375168.html Could not load file or assembly 'System.Core, Version= ...