关联规则&Apriori算法
2017-12-02 14:27:18
一、术语
Items:项,简记I
Transaction:所有项的一个非空子集,简记T

Dataset:Transaction的一个集合,简记D
关联规则:
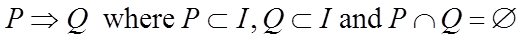
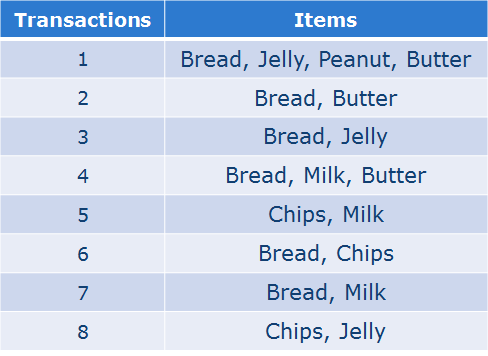
一个Dataset的例子:
我们的目的就是找到类似买了面包->黄油这样的关联关系。
二、支持度与置信度
- 支持度
支持度就是相应的Item或者ItemSet在Dataset中出现的频率:

比如上图的D中的支持度为:
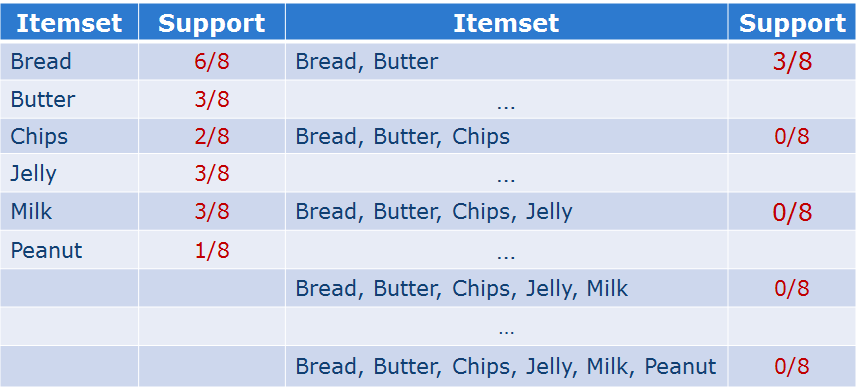
从这个图中我们可以看到一般来说支持度是单调不增的,也就是说,随着商品的增加,支持度是会减小的。
另外,类似X->Y这种购买了X又购买了Y的支持度就是这两者同时购买的频率:
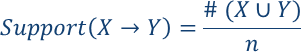
- 置信度
关联规则X->Y的置信度就是T中包含X,Y的交易数目比上单独出现X的交易数目。
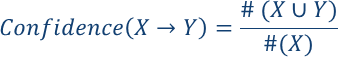
也可以理解为条件概率
 ,
,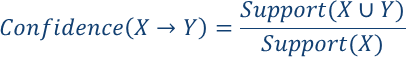
举个例子:

一般来说会给出支持度和置信度的一个下限,也就是规定了支持度和置信度要高于某个阈值才表示当前的规则是有效的:

所以一个关联规则的问题就是:

一个简单的思想就是首先找到所有的频繁项,然后对频繁项中的数据进行排列组合找出其中符合条件的规则。但是这种暴力检索的方式是非常麻烦的,主要问题就是排列组合的过程中的算法的复杂度会达到指数级。
三、Apriori算法
我们必须设法降低产生频繁项集的计算复杂度。此时我们可以利用支持度对候选项集进行剪枝。
Apriori定律1:如果一个集合是频繁项集,则它的所有子集都是频繁项集。
Apriori定律2:如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
举个例子:
下图表示当我们发现{A,B}是非频繁集时,就代表所有包含它的超级也是非频繁的,即可以将它们都剪除。

算法的具体步骤:

关键的步骤是如何生成Ck+1;

通过上述的算法就可以生成一个Ck+1,算法的步骤是前k-1项相同,第k项不同,将不同的项合并就可以生成一个k+1的C。不过这种算法也会有出错的时候比如:

证明该种生成算法有效的过程如下:

举个例子:

一个更具体的例子如下:



保留了所有的频繁集之后再来进行计算置信度:
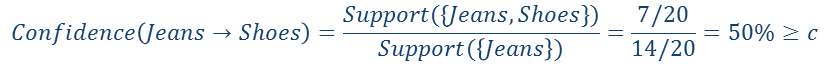
这里需要警惕的是,P(X|Y)<=P(X)的时候,这条关联规则就没有什么作用。
四、序列模式
序列是前后有一定关系的元素的列表。

子序列的概念:

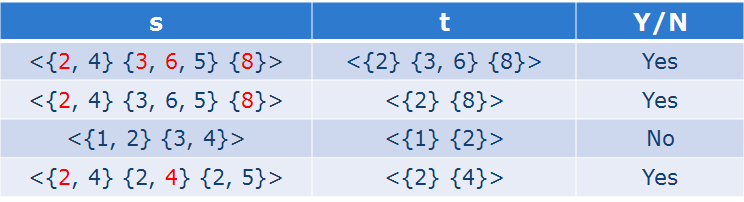
注意,这里的子序列中的前后是有顺序的概念的,也就说,子序列中2在3前面,那么在原序列中也应该是这个顺序。
序列中的支持度:
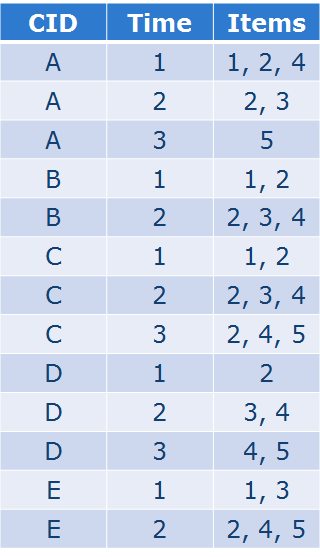
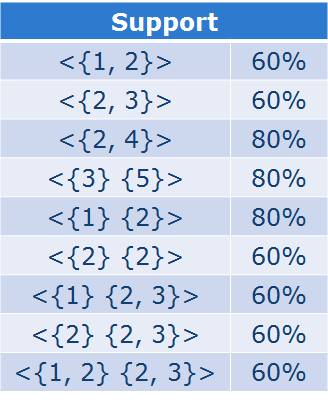
序列的组合要更为复杂:

那么这里就需要一种新的生成算法:

关联规则&Apriori算法的更多相关文章
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 一步步教你轻松学关联规则Apriori算法
一步步教你轻松学关联规则Apriori算法 (白宁超 2018年10月22日09:51:05) 摘要:先验算法(Apriori Algorithm)是关联规则学习的经典算法之一,常常应用在商业等诸多领 ...
- 详细介绍关联规则Apriori算法及实现
看了很多博客,关于关联规则的介绍想做一个详细的汇总: 一.概念 ...
- python实现简单关联规则Apriori算法
from itertools import combinations from copy import deepcopy # 导入数据,并剔除支持度计数小于min_support的1项集 def lo ...
- 数据挖掘:关联规则的apriori算法在weka的源码分析
相对于机器学习,关联规则的apriori算法更偏向于数据挖掘. 1) 测试文档中调用weka的关联规则apriori算法,如下 try { File file = new File("F:\ ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 关联规则挖掘之apriori算法
前言: 众所周知,关联规则挖掘是数据挖掘中重要的一部分,如著名的啤酒和尿布的问题.今天要学习的是经典的关联规则挖掘算法--Apriori算法 一.算法的基本原理 由k项频繁集去导出k+1项频繁集. 二 ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
随机推荐
- Linux系统下 Rsync 环境安装搭建
一.Rsync简介 1.认识 Rsync(remote synchronize)是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件.Rsync使用所谓的“Rsync算法”来使本地和远 ...
- 【巷子】:关于Apply、call、bind的详解
call方法: 语法:call(thisObj,'',''........) 定义:调用一个对象的一个方法,以另一个对象替换当前对象 说明:call方法可以用来代替另一个对象调用一个方法.call方法 ...
- | unauthenticated user (1130, "Host '127.0.0.1' is not allowed to connect to this MySQL server")
mysql> show processlist;+----+----------------------+-----------------+------+---------+------+-- ...
- 数据去重优化 MemoryError 内存不足
from ProjectUtil.usingModuleTOMODIFY import getNow export_q_f, q_l, start_ = '/mnt/mongoexport/super ...
- php引用(&)详解及注意事项——引用返回function &a();&a()
http://www.cnblogs.com/xiaochaohuashengmi/archive/2011/09/10/2173092.html 函数的引用返回 先看代码 <?php func ...
- SQL基础--查询之二--连接查询
SQL基础--查询之二--连接查询
- 省市县三级联动的SQL
完整版见https://jadyer.github.io/ 首先是建表语句 CREATE TABLE `t_address_province` ( `id` INT AUTO_INCREMENT PR ...
- PHP接收json格式的POST数据
/** * 获取 post 参数; 在 content_type 为 application/json 时,自动解析 json * @return array */ private function ...
- [sql] 同库表(结构)的备份和sql聚合&navicat使用
同库表的备份-赋值表结构和数据SQL语句 参考 有时候我们处理某个表时,需要先备份下这个表到当前这个库,然后再执行sql. 站在sql角度,就无需在mysqldump或者诸如导出sql的方式来备份了. ...
- t检验&z检验学习[转载]
转自:https://blog.csdn.net/m0_37777649/article/details/74937242 1.什么是T检验? T检验是假设检验的一种,又叫student t检验(St ...