SST:Single-Stream Temporal Action Proposals论文笔记
SST:Single-Stream Temporal Action Proposals
这是本仙女认认真真读完且把算法全部读懂(其实也不是非常懂)的第一篇论文
CVPR2017
一作

论文写作的动机motivation
这篇文章介绍了一个时间维度上的proposal方法,用来进行动作识别
Introduction
视频中记录了大量关于人类行为动作的信息,要想处理这些数据,计算机视觉算法需要能够进行人类动作识别和检测的能力
以往所用的动作识别的方法:
一开始动作识别被简单的看作是视频分割,也就是把原本的 长视频分割成包含单个动作的小片段,但是由于相机记录人类动作是持续不断进行的,所以如果要实现这种想法,算法必须在识别发生动作的起止时间的同时识别动作的种类
后来使用proposal的方法
就是先生成包含动作的proposal,然后使用分类器进行分类,
Proposal是使用滑动的时间窗口,把视频分割成短的并且含有大量重叠内容的片段
这种方法计算量大,而且处理重叠的时间窗口或许不止一次
本文提出的方法,是一个专用于长视频序列的框架,只需要single pass,一次就可以处理完整个视频(找proposal的时候)也就是说不需要分开的处理重叠的时间窗口了
贡献:
1. 可以处理long video sequence,只需要向前传播一次就能处理完整个video,可以处理任意长度的video,不需要处理重叠的时间窗口
2. 在proposal generation task上取得了顶尖成果
3. SST proposals提供了一个较强的基准,进行temporal action localization将该方法结合到现有的分类中可以改善分类的性能
Related Work
作者做的一部分相关调查工作,总结方法
主要看作者把他们分了哪几类,使用了什么模型,怎么用这些模型
这篇文章使用的主要是RNN模型
序列化,连续化,判断动作不止要看动作本身还要看前后相关的帧
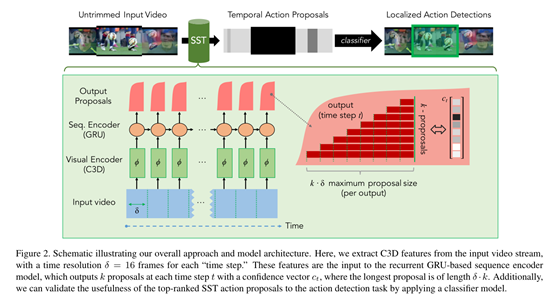
Input 输入的是未经处理的长视频序列,共有L个frame
Visual encoding 感知输入的video
选用C3D网络,因为它能在小的时间分辨率δ内有效地捕捉视觉和运动信息
我们初始化使δ = 16 frames,并且把视频分割成T = L/δ个不相互重叠的time step(视频短序列),每一个time step使用C3D网络进行特征编码,最后使用PCA进行降维处理。
Sequence encoding这一步的主要目的是accumulate evidence across time as the video sequence progresses也就是说随着视频序列编码的进行逐步确定视频到底做了什么动作,这里接受的是降维后的C3D特征信息,到这一步,收集信息直到确定某个动作已经发生了,与此同时,扔掉不相关的背景信息。
(
从流程上可以看出每一个time step所接收的信息包括两部分,一部分是来自visual encoding的经过降维的C3D特征,一部分是上一步的time step,输出也是两部分,proposal和下一个time step,这里使用的是GRU进行处理
【具体为啥用RNN不用CNN,,因为这里的循环迭代,还有,他自己实验试出来的。。作者觉得RNN比CNN好用】
)
Output proposals 输出proposal
其实每一个time step都会输出一个confidence score 这些score对应着k组从bt-1到bt的proposal,每次output最大值就是kδframe的proposal,
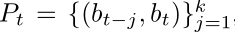
需要注意的是这里他用了一个single forward pass at each time step ,也就是说他每次找proposal都只需要一次前向传播就能处理完整个视频序列
但是这里其实相当于输出了一系列的概率值,并没有确定哪一个是真正的proposal,所以还需要一个groudtruth来评定哪一个是最好的
Training
这一部分的主要目的是来估计SST模型里的各项参数值
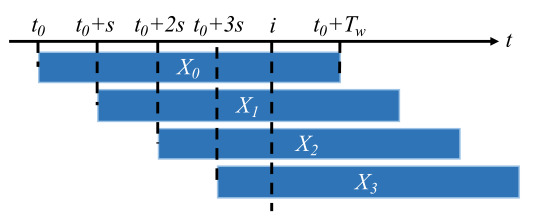
对于每一段训练的视频,长为Lframes ,分割成T = L/δ个time step,使用一个滑动窗口,设定窗口长度为Tw,使Tw = Lw /δ,设定Lw>>kδ(即窗口长度为每一个time step的k倍)步长固定为s,并且s保持较小的数值,以便进行密集取样
密集取样能够保证每个time step能够被多次考虑到,
每一次取样都使用label来进行标记,把这些已经选出来的proposal分为positive和negative,比如说在上图的X0,此时此刻计算他的IOU值,如果超过0.5label为1,低于0.5标0,做一个二分类
这里使用了一个交叉熵损失函数来作为loss function
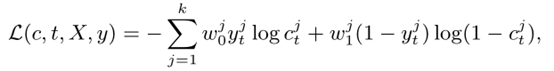
最后总的loss是以上loss的和
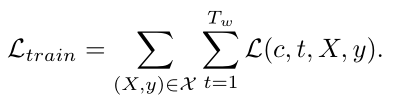
Training是离线进行的并不是随视频序列实时的,这里不是single pass,对样本进行密集采样有重叠的,便于检测前后的帧的动作是否有联系,以此判断动作的连续性
给出了loss function和label,是有监督的学习
Experiment
数据集是THUMOS14和ActivityNet
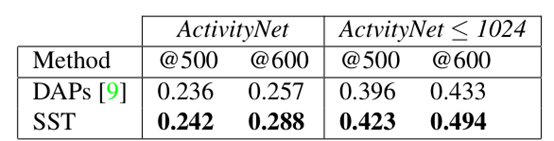
接下来把SST和DAPs等一堆方法进行了一个比较
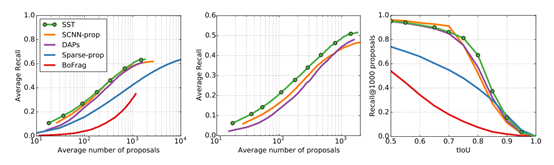
几种不同的方法在处理等量的proposal时候的recall进行对比,SST明显优于其他的方法
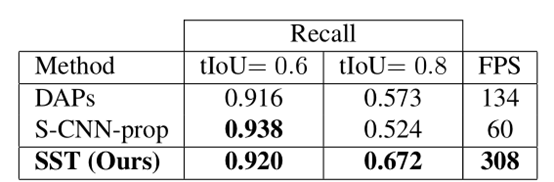
对比可以看出SST和其他方法相比,在IOU较高的状态下效率更高,也就是说我们可以进行密集取样捕获真实的动作片段以便分辨出视频动作
另外相比其他的方法来说,SST的运行速度更快
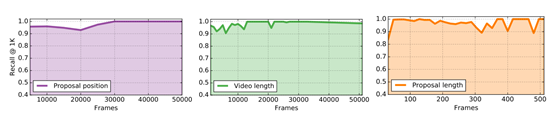
从鲁棒性方面来说
SST网络能够在长视频序列下很好的展开并不会影响性能

检测结果
SST检测到的proposal和groundtruth高度吻合
扩展性建议

SST用于动作检测方面
不止可以用来检测哪些部分有动作的进行,而且可以检测动作的种类。
SST生成proposal,把SST和其他的分类器来叠加使用,能够提高性能、
总结
SST能做到introduction所说的那些东西
…………………………………………
SST:Single-Stream Temporal Action Proposals论文笔记的更多相关文章
- 论文笔记之 SST: Single-Stream Temporal Action Proposals
SST: Single-Stream Temporal Action Proposals 2017-06-11 14:28:00 本文提出一种 时间维度上的 proposal 方法,进行行为的识别.本 ...
- TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals(ICCV2017)
Motivation 实现快速和准确地抽取出视频中的语义片段 Proposed Method -提出了TURN模型预测proposal并用temporal coordinate regression来 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- 深度学习论文笔记:Fast R-CNN
知识点 mAP:detection quality. Abstract 本文提出一种基于快速区域的卷积网络方法(快速R-CNN)用于对象检测. 快速R-CNN采用多项创新技术来提高训练和测试速度,同时 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- Temporal Action Detection with Structured Segment Networks (ssn)【转】
Action Recognition: 行为识别,视频分类,数据集为剪辑过的动作视频 Temporal Action Detection: 从未剪辑的视频,定位动作发生的区间,起始帧和终止帧并预测类别 ...
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
随机推荐
- 如何处理Entity Framework / Entity Framework Core中的DbUpdateConcurrencyException异常(转载)
1. Concurrency的作用 场景有个修改用户的页面功能,我们有一条数据User, ID是1的这个User的年龄是20, 性别是female(数据库中的原始数据)正确的该User的年龄是25, ...
- DDL-库的管理
一.创建库create database [if not exists] 库名[ character set 字符集名]; 二.修改库alter database 库名 character set 字 ...
- oracle 子查询的几个种类
1.where型子查询: select cat_id,good_id,good_name from goods where good_id in (selct max(good_id) from go ...
- [Oracle]Oracle良性SQL建议
(1)选择最有效率的表名顺序(只在基于规则的优化器中有效): Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处 ...
- OO 第五、六、七次作业总结
第五次作业 算法与实现 这次的电梯因为要使用系统时间进行模拟,所以又是推倒了之前的重写的.最后采用三个电梯线程,一个调度线程,一个输入线程的方式. 源码分析图示 类图 方法分析 类分析 由上图看,由于 ...
- MySQL语句详解(用户表、密码、权限、远程)
注: mysql.user表中Host为%的含义 Host列指定了允许用户登录所使用的IP,比如user=root Host=192.168.1.1.这里的意思就是说root用户只能通过192.168 ...
- tp框架如何处理mysql先排序在分组
$giModel = M('GroupIntegral'); $gi_table = $giModel->order('id desc')->limit('999')->buildS ...
- 基于STM32F103ZET6 HC_SR501人体红外感应
这是最后的实验现象,有人走过会一直输出有人,离开范围时则输出没人 开发板 PZ6086L ,HC_SR501模块 这是HC_SR501的示意图,,VCC和GND不再多做介绍,5V供电就行, OUT接口 ...
- PTA(Basic Level)-1076 Wifi密码
一 题目介绍: 现将 wifi 密码设置为下列数学题答案:A-1:B-2:C-3:D-4.本题就要求你写程序把一系列题目的答案按照卷子上给出的对应关系翻译成 wifi 的密码.这里简单假设每道 ...
- electron安装与使用
系统 WIN10 X64 1. python-2.7.15.amd64.msi 2. node-v10.4.1-x64.msi 3. VS2015 community(社区版) 4. npm conf ...