测试拆分比较大SQL Server数据库
有2个办法拆分比较大的数据库。
1.重建聚集索引
2.收缩数据库
一、准备测试数据
1 create table blocktable(blockno int,binno int,rack int,chipcount int,machineno varchar(10))
2 go
3
4 insert into blocktable(blockno,binno,rack,chipcount,machineno)
5 select cast((rand(checksum(newid()))*130) as int),cast((rand(checksum(newid()))*10) as int),
6 cast((rand(checksum(newid()))*130) as int),0,''
7 from master..spt_values
8 where [type] = 'p' and number <= 10000000000
9
10 select *
11 from blocktable
12
13 insert into blocktable select * from blocktable
14
15 drop table blocktable
16
17 select @@servername
拆分前:
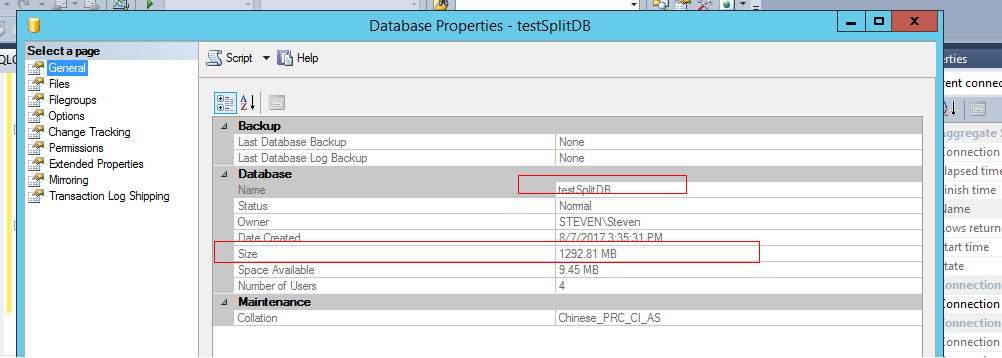
添加3个数据文件

此时主数据文件大小不变,ndf文件大小为初始大小100M, 说明数据还没有移动到ndf文件中.
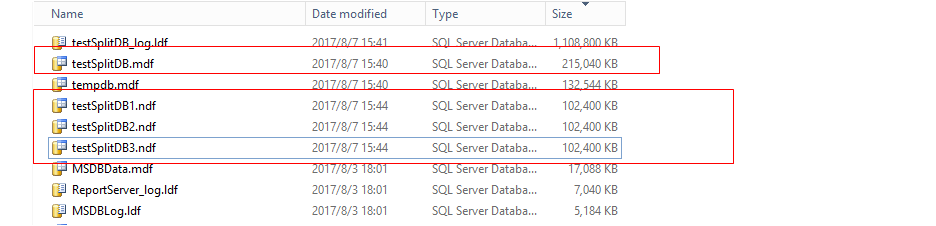
收缩数据库
USE [testSplitDB]
GO
DBCC SHRINKDATABASE(N'testSplitDB' )
GO
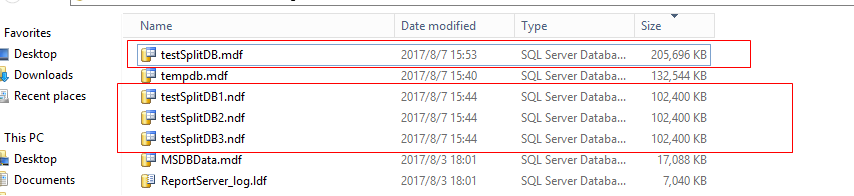
这个命令没起作用
下面测试清空rimary DB file
清空primary DB file遇到错误,原因未知.
下面测试重建聚集索引.
重建狙击索引有效
下面再测试一遍
测试数据库大小

加入3个ndf文件

测试收缩数据库
---没有效果
使用下面的选项移动成功, 并且ndf文件是轮流写,所以ndf文件大小相近. 但是花费时间比较长. 如果操作的是mdf文件, 最后可能报错,提示不能移动所有object, 这个错误可以忽略. 完成后再释放mdf文件的空间就可以了.

收缩完成后结果:
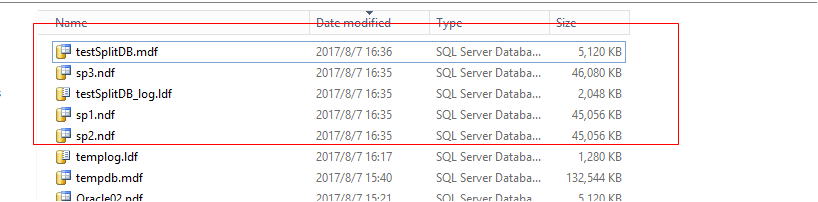
当再次写入数据时,所有文件会被轮流写入
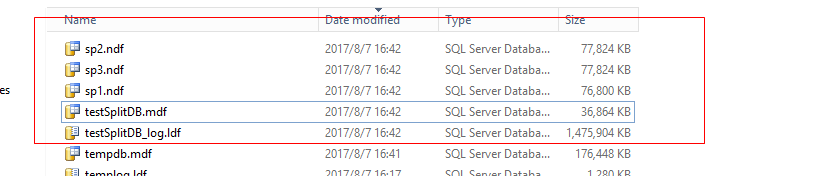
• 第三次测试
再次确认普通收缩数据库不行,必须选择清空数据库文件才可以移动数据到ndf文件.
再次确认新建聚集索引有效,收缩的时候选择重新组织页.
测试拆分比较大SQL Server数据库的更多相关文章
- .NET客户端下载SQL Server数据库中文件流保存的大电子文件方法(不会报内存溢出异常)
.NET客户端下载SQL Server数据库中文件流保存的大电子文件方法(不会报内存溢出异常) 前段时间项目使用一次性读去SQL Server中保存的电子文件的文件流然后返回给客户端保存下载电子文件, ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
- SQL SERVER 数据库备份的三种策略及语句
1.全量数据备份 备份整个数据库,恢复时恢复所有.优点是简单,缺点是数据量太大,非常耗时 全数据库备份因为容易实施,被许多系统优先采用.在一天或一周中预定的时间进行全数据库备份使你不用动什么脑筋 ...
- SQL Server - 数据库初识
在互联网笔试中,常遇到数据库的问题,遂来简单总结,注意,以 Sql Server 数据库为例. 数据库 数据库系统,Database System,由数据库和数据库管理系统组成. 数据库,Data ...
- 你所不知道的SQL Server数据库启动过程(用户数据库加载过程的疑难杂症)
前言 本篇主要是上一篇文章的补充篇,上一篇我们介绍了SQL Server服务启动过程所遇到的一些问题和解决方法,可点击查看,我们此篇主要介绍的是SQL Server启动过程中关于用户数据库加载的流程, ...
- 《SQL Server企业级平台管理实践》读书笔记——关于SQL Server数据库的还原方式
本篇是继上篇的备份方式,本篇介绍的是还原方案,在SQL Server在2005以上现有的还原方案一般分为以下4个级别的数据还原: 1.数据库完整还原级别: 还原和恢复整个数据库.数据库在还原和恢复操作 ...
- SQL Server数据库的三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式(转载)
SQL Server数据库有三种恢复模式:简单恢复模式.完整恢复模式和大容量日志恢复模式: 1.Simple 简单恢复模式, Simple模式的旧称叫”Checkpoint with truncate ...
- 转:SQL SERVER数据库中实现快速的数据提取和数据分页
探讨如何在有着1000万条数据的MS SQL SERVER数据库中实现快速的数据提取和数据分页.以下代码说明了我们实例中数据库的“红头文件”一表的部分数据结构: CREATE TABLE [dbo]. ...
- (火炬)MS SQL Server数据库案例教程
(火炬)MS SQL Server数据库案例教程 创建数据库: CREATE DATABASE TDB //数据库名称 ON ( NAME=TDB_dat,//逻辑文件名 在创建数据库完成之后语句中引 ...
随机推荐
- codeblocks c++ 编译出错
codeblocks编译出错 今天编译一个c++程序调用模板的时候,出现错误 error This file requires compiler and library support for the ...
- TortoiseGit学习系列之TortoiseGit基本操作拉取项目(图文详解)
前面博客 TortoiseGit学习系列之TortoiseGit基本操作克隆项目(图文详解) TortoiseGit学习系列之TortoiseGit基本操作修改提交项目(图文详解) TortoiseG ...
- docker搭建gitlab,设置邮件提醒,并运行runner
接着http://www.cnblogs.com/wsy1030/p/8431837.html 在另一台机子运行gitlab: docker run --name='gitlab' -d -p 222 ...
- linux 将一个服务器上的文件或者文件夹复制到另一台服务器上
使用scp将一个Linux系统中的文件或文件夹复制到另一台Linux服务器上 复制文件或文件夹(目录)命令: 一.复制文件: (1)将本地文件拷贝到远程 scp 文件名 用户名@计算机IP或者计 ...
- [作业] Python入门基础--猜年龄
age = 20 while True: try: guess_age = int(input('guess age:')) if guess_age > age: print('Is bigg ...
- 关于service相关知识的认识
做android的程序开发也有了许久了,当做一个大程序的时候,越来越发现service是非常有用的方法,当你想后台运行数据或者音乐播放操作的时候,都可以才有service,根据实际情况,写成local ...
- WCF-异步调用和两种客户端形式
当发布一个服务端之后,客户端可以通过服务端的元数据,用VS2010添加服务引用的方式生成对应的代码.并且可以选择生成相应的异步操作. WCF实现代码,Add操作延时5秒后再返回结果. [Service ...
- JavaScript内置对象与原生对象【转】
原文:https://segmentfault.com/a/1190000002634958 内置对象与原生对象 内置(Build-in)对象与原生(Naitve)对象的区别在于:前者总是在引擎初始化 ...
- Java反射学习总结
我开始学习反射的初衷是为了理解Spring 里的控制反转,其次可以利用反射来达到类中的解耦. 自己写的一些心得,希望能帮到大家 1.反射指的是对象的反向处理操作,是根据对象来取得对象的来源信息. 反射 ...
- hdu 3999 二叉查找树
The order of a Tree Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Othe ...