python ConfigParser读取配置文件,及解决报错(去掉BOM)ConfigParser.MissingSectionHeaderError: File contains no section headers的方法
先说一下在读取配置文件时报错的问题--ConfigParser.MissingSectionHeaderError: File contains no section headers
问题描述:
在练习ConfigParser读取配置文件时,cmd一直报一个错:ConfigParser.MissingSectionHeaderError: File contains no section headers.如图:
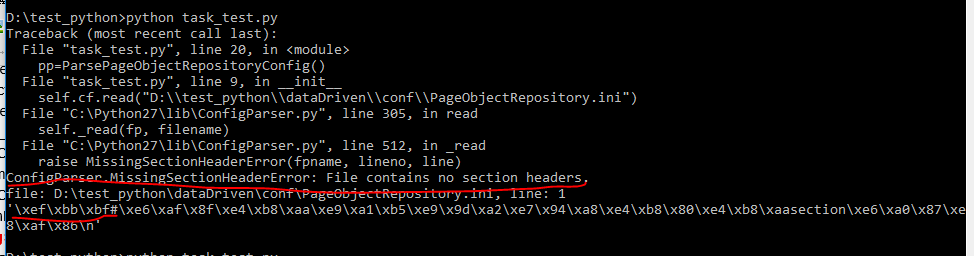
D:\test_python>python task_test.py
Traceback (most recent call last):
File "task_test.py", line 20, in <module>
pp=ParsePageObjectRepositoryConfig()
File "task_test.py", line 9, in __init__
self.cf.read("D:\\test_python\\dataDriven\\conf\\PageObjectRepository.ini")
File "C:\Python27\lib\ConfigParser.py", line 305, in read
self._read(fp, filename)
File "C:\Python27\lib\ConfigParser.py", line 512, in _read
raise MissingSectionHeaderError(fpname, lineno, line)
ConfigParser.MissingSectionHeaderError: File contains no section headers.
file: D:\test_python\dataDriven\conf\PageObjectRepository.ini, line: 1
'\xef\xbb\xbf#\xe6\xaf\x8f\xe4\xb8\xaa\xe9\xa1\xb5\xe9\x9d\xa2\xe7\x94\xa8\xe4\xb8\x80\xe4\xb8\xaasection\xe6\xa0\x87\xe8\xaf\x86\n'
百度了一下网上的解决方案,
报错是因为配置文件PageObjectRepository.ini在windows下经过notepad编辑后保存为UTF-8或者unicode格式的话,会在文件的开头加上两个字节“\xff\xfe”或者三个字节“\xef\xbb\xbf”。 就是--》BOM, BOM是什么?请看结尾
解决的办法就是在配置文件被读取前,把DOM字节个去掉。
网上也给了一个用正则去掉BOM字节的函数:就是把对应的字节替换成空字符串
remove_BOM()函数定义:
def remove_BOM(config_path):
content = open(config_path).read()
content = re.sub(r"\xfe\xff","", content)
content = re.sub(r"\xff\xfe","", content)
content = re.sub(r"\xef\xbb\xbf","", content)
open(config_path, 'w').write(content)
下面贴一下我的配置文件和读取配置文件的代码--:

代码:
#encoding=utf-8
from ConfigParser import ConfigParser
import re
def remove_BOM(config_path):#去掉配置文件开头的BOM字节
content = open(config_path).read()
content = re.sub(r"\xfe\xff","", content)
content = re.sub(r"\xff\xfe","", content)
content = re.sub(r"\xef\xbb\xbf","", content)
open(config_path, 'w').write(content)
class ParsePageObjectRepositoryConfig(object):
def __init__(self,config_path):
self.cf=ConfigParser()#生成解析器
self.cf.read(config_path)
print "-"*80
print "cf.read(config_path):\n", self.cf.read(config_path)
def getItemsFromSection(self,sectionName):
print self.cf.items(sectionName)
return dict(self.cf.items(sectionName))
def getOptionValue(self,sectionName,optionName):#返回一个字典
return self.cf.get(sectionName,optionName)
if __name__=='__main__':
remove_BOM("D:\\test_python\\PageObjectRepository.ini")
pp=ParsePageObjectRepositoryConfig("D:\\test_python\\PageObjectRepository.ini")
remove_BOM
print "-"*80
print "items of '126mail_login':\n",pp.getItemsFromSection("126mail_login")
print "-"*80
print "value of 'login_page.username' under section '126mail_login':\n",pp.getOptionValue("126mail_login","login_page.username")
结果:
D:\test_python>python task_test.py
--------------------------------------------------------------------------------
cf.read(config_path):
['D:\\test_python\\PageObjectRepository.ini']
--------------------------------------------------------------------------------
items of '126mail_login':
[('login_page.frame', 'id>x-URS-iframe'), ('login_page.username', "xpath>//input[@name='email']"), ('login_page.password', "xpath>//input[@name='password']"), ('login_page.loginbutton', 'id>dologin')]
{'login_page.loginbutton': 'id>dologin', 'login_page.username': "xpath>//input[@name='email']", 'login_page.frame': 'id>x-URS-iframe', 'login_page.password': "xpath>//input[@name='password']"}
--------------------------------------------------------------------------------
value of 'login_page.username' under section '126mail_login':
xpath>//input[@name='email']
BOM概念:
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
UTF-8 不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 “Zero Width No-Break Space” 的
UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8编码了。Windows
就是使用 BOM
来标记文本文件的编码方式的。类似WINDOWS自带的记事本等软件,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF
0xBB 0xBF,即BOM)。它是一串隐藏的字符,用于让记事本等编辑器识别这个文件是否以UTF-8编码。
从堆栈信息中可以看到UTF8编码的字符有BOM的字符串前边有:\xef\xbb\xbf
'\xef\xbb\xbf#\xe6\xaf\x8f\xe4\xb8\xaa\xe9\xa1\xb5\xe9\x9d\xa2\xe7\x94\xa8\xe4\xb8\x80\xe4\xb8\xaasection\xe6\xa0\x87\xe8\xaf\x86\n'
python ConfigParser读取配置文件,及解决报错(去掉BOM)ConfigParser.MissingSectionHeaderError: File contains no section headers的方法的更多相关文章
- ConfigParser.MissingSectionHeaderError: File contains no section headers.
今天使用ConfigParser解析一个ini文件,报出如下错误: config.read(logFile) File "C:\Python26\lib\ConfigParser.py&qu ...
- python在读取配置文件存入列表中,去掉回车符号
self.receiver = map(lambda x: x.strip(), receiver_list) # 去掉list中的回车符号
- 记一次用python 的ConfigParser读取配置文件编码报错
记一次用python 的ConfigParser读取配置文件编码报错 ...... raise MissingSectionHeaderError(fpname, lineno, line)Confi ...
- ConfigParser读取配置文件时报错:ConfigParser.MissingSectionHeaderError
使用ConfigParser来读取配置文件,经常会发现经过记事本.notepad++修改后的配置文件读取时出现下面的问题: ConfigParser.MissingSectionHeaderError ...
- python之读取配置文件模块configparser(二)参数详解
configparser.ConfigParser参数详解 从configparser的__ini__中可以看到有如下参数: def __init__(self, defaults=None, dic ...
- Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal multibyte sequence
Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal mul ...
- python中引入包的时候报错AttributeError: module 'sys' has no attribute 'setdefaultencoding'解决方法?
python中引入包的时候报错:import unittestimport smtplibimport timeimport osimport sysimp.reload(sys)sys.setdef ...
- python中读取配置文件ConfigParser
在程序中使用配置文件来灵活的配置一些参数是一件很常见的事情,配置文件的解析并不复杂,在python里更是如此,在官方发布的库中就包含有做这件事情的库,那就是ConfigParser,这里简单的做一些介 ...
- DB2读取CLOB字段-was报错:操作无效:已关闭 Lob。 ERRORCODE=-4470, SQLSTATE=null
DB2读取CLOB字段-was报错:操作无效:已关闭 Lob. ERRORCODE=-4470, SQLSTATE=null 解决方法,在WAS中要用的数据源里面配置连个定制属性: progressi ...
随机推荐
- Android储存
Android储存一共5种方法 一: 手机内置,外部储存 1.获取本地存储 (Android的读写文件及权限设置) getFilesDir() data/data/包名/File getCache ...
- Receiver type for instance message is a forward
本文转载至 http://my.oschina.net/sunqichao/blog?disp=2&catalog=0&sort=time&p=3 这往往是引用的问题.ARC要 ...
- c++11 数值类型和字符串的相互转换
string和数值类型转换 c++11提供了to_string方法,可以方便的将各种数值类型转换为 字符串类型: std::string to_string(int value); std::stri ...
- Linux find、grep命令详细用法
在linux下面工作,有些命令能够大大提高效率.本文就向大家介绍find.grep命令,他哥俩可以算是必会的linux命令,我几乎每天都要用到他们.本文结构如下:find命令 find命令的一般形式 ...
- {sharepoint} SetPermission
using System; using System.Collections.Generic; using System.Linq; using System.Text; using Microsof ...
- eclipse 安装Subversion1.82(SVN)插件
Eclipse下SVN插件的安装,可以选择在线安装和离线安装两种方式: 2.(可选①)使用本地安装包安装插件 --填写插件名(可随意取名) --插件来源地址(①安装包,②使用网址) →Archie→选 ...
- Dcloud开发-- 打开蓝牙
这样打开APP就会直接提示是否要打开蓝牙: <script type="text/javascript"> mui.init(); mui.plusReady(func ...
- 【转】stm32中断嵌套全攻略
断断续续学习STM32一学期了,时间过的好快,现在对STM32F103系列单片机的中断嵌套及外部中断做一个总结,全当学习笔记.废话不多说,ARM公司的Cortex-m3 内核,支持256个中断,其中包 ...
- 修改字段字符集 mysql 修改 锁表 show processlist; 查看进程 Waiting for table metadata lock
ALTER TABLE `question` MODIFY COLUMN `title` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unico ...
- Why Choose Jetty?
https://webtide.com/why-choose-jetty/ Why Choose Jetty? The leading open source app server availab ...