【Java面试题】解释内存中的栈(stack)、堆(heap)和静态存储区的用法
Java面试题:解释内存中的栈(stack)、堆(heap)和静态存储区的用法
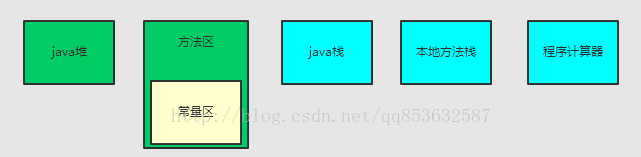
堆区: 专门用来保存对象的实例(new 创建的对象和数组),实际上也只是保存对象实例的属性值,属性的类型和对象本身的类型标记等,并不保存对象的方法(方法是指令,保存在Stack中)
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身.
3.一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。
栈区: 对象实例在Heap 中分配好以后,需要在Stack中保存一个4字节的Heap内存地址,用来定位该对象实例在Heap 中的位置,便于找到该对象实例。
1.每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
4.由编译器自动分配释放 ,存放函数的参数值,局部变量的值等.
静态区/方法区:
1.方法区又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
3.静态常量存放在方法区的常量区中,静态常量初始化后不可更改。
附:
堆和栈是程序运行的关键,应该将其理解清楚。
栈是运行时的单位,而堆是存储时的单位。
堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处)。
为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?
第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。不得不承认,面向对象的设计,确实很美。
【Java面试题】解释内存中的栈(stack)、堆(heap)和静态存储区的用法的更多相关文章
- java - 解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用JVM中的栈空间: 而通过new关键字和构造器创建的对象则放在堆空间,堆是垃圾收集器管理的主要区域,由于现在的垃圾收 ...
- 解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法?
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用JVM中的栈空间:而通过new关键字和构造器创建的对象则放在堆空间,堆是垃圾收集器管理的主要区域,由于现在的垃圾收集 ...
- 解释内存中的栈(stack)、堆(heap)和方法区(method area) 的用法?
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的 现场保存都使用 JVM 中的栈空间:而通过 new 关键字和构造器创建的对象则放在 堆空间,堆是垃圾收集器管理的主要区域,由于现 ...
- 解释内存中的栈(stack)、堆(heap)和静态区(static area)的用法
堆区:专门用来保存对象的实例(new 创建的对象和数组),实际上也只是保存对象实例的属性值,属性的类型和对象本身的类型标记等,并不保存对象的方法(方法是指令,保存在Stack中) 1.存储的全部是对象 ...
- 面试01:解释内存中的栈(stack)、堆(heap)和方法区(method area)的用法
栈的使用:通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用JVM中的栈空间. 队的使用:通过new关键字和构造器创建的对象则放在堆空间,堆是垃圾收集器管理的主要区域 ...
- Java基本类型的内存分配在栈还是堆
我们都知道在Java里面new出来的对象都是在堆上分配空间存储的,但是针对基本类型却有所区别,基本类型可以分配在栈上,也可以分配在堆上,这是为什么? 在这之前,我们先看下Java的基本类型8种分别是: ...
- java基础学习之内存分析(栈、堆、方法区)
栈存放:会为每个方法(包括构造函数)开辟一个栈指针,方法执行完毕后,会自动退出,并释放空间,主要每个方法中的存放局部变量 局部变量 先进后出 自下而上存储 方法执行完毕 自动释放空间 堆: 存放n ...
- 【转】C中的静态存储区和动态存储区
一.内存基本构成 可编程内存在基本上分为这样的几大部分:静态存储区.堆区和栈区.他们的功能不同,对他们使用方式也就不同. 静态存储区:内存在程序编译的时候就已经分配好,这块内存在程序的整个 ...
- Java中的堆内存、栈内存、静态存储区
一.栈 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用.但缺点是,存在栈中的数据大小与生存 ...
随机推荐
- props的写法
简写 props: ['demo-first', 'demo-second'] 带类型 props: { 'demo-first': Number, 'demo-second': Number } 带 ...
- 使用ViewFlipper实现广告图片的自动轮播的效果
轮播资源图片的实现 package com.loaderman.viewflipperdemo; import android.os.Bundle; import android.support.v7 ...
- Ironic 裸金属管理服务的网络模型
目录 文章目录 目录 Bare-Metal networking in Neutron 核心网络类型 网络拓扑 抽象网络拓扑图 Neutron Implementation Neutron 了解裸金属 ...
- C/C++之编程语言学习资源
前言 因朋友相问,藉以帮助需要学习C.C++语言的后来小伙伴. 网络视频资源 选择其中一系列即可,切忌贪多嚼不烂. [系列1:可能会面临开课时间错过的问题,二门课程只要能上其一即可,均为浙大翁恺老师的 ...
- Xcode8.1 真机测试 ,添加iOS10.3的idk到Xcode8.1中
1.下载iOS10.3的idk包; 2.解压, 找到路径 Finder -> 应用程序 -> 右键Xcode -> 显示包内容 -> Contents -> Develo ...
- asp.netMVC中配置automap
第一.新建类库,以解决方案名XXX为例,建立子类库名为 XXX.AutoMapper. 第二. XXX.AutoMapper类库中,添加对automap的引用. 第三.创建映射文件类 ModelPr ...
- spark基础概念(一):幂等性。
1) 出处:幂等性源自数学概念,表示f(x) = f(f(x)); 含义:多次执行一个函数得到的值和执行一次得到的值相同. 如:f(x) = pow(x, 1); f(x) = abs(x); 2) ...
- JavaScript基础入门06
目录 JavaScript 基础入门06 Math 对象 Math对象的静态属性 Math对象的静态方法 指定范围的随机数 返回随机字符 三角函数 Date对象 基础知识 日期对象具体API 构造函数 ...
- jmeter响应数据中文乱码处理
1.在jmeter的bin目录下找到 jmeter.properties 文件并打开 2.搜索关键字 “default.encoding”,将1084行(以搜索到的位置为准)改成下图所示:samp ...
- 抓包分析IP如何设置详细步骤
首先,要知道的是,我们直接改以太网(校园网)的IP地址是不行的,校园网识别不了 如下图: 我们必须通过让电脑连接个人热点才能完成IP修改. 第一步,连接上热点后打开电脑的cmd命令程序,在命令窗口中输 ...