Interacted Action-Driven Visual Tracking Algorithm
文章来源:Attentional Action-Driven Deep Network for Visual Object Tracking 博士论文(2017年8月份完稿)
http://s-space.snu.ac.kr/bitstream/10371/136793/1/000000145905.pdf
Chapter 4. Interacted Action-Driven Visual Tracking
4.1 Overview:
之前作者提出的 Single Agent Reinforcement Learning Tracking Algorithm 存在相似物体遮挡导致失效的问题:

这种情况下,由于只考虑到物体的那一小块区域,由于有相似物体的存在,非常容易导致物体遮挡后,跟着其他物体乱跑的情况:
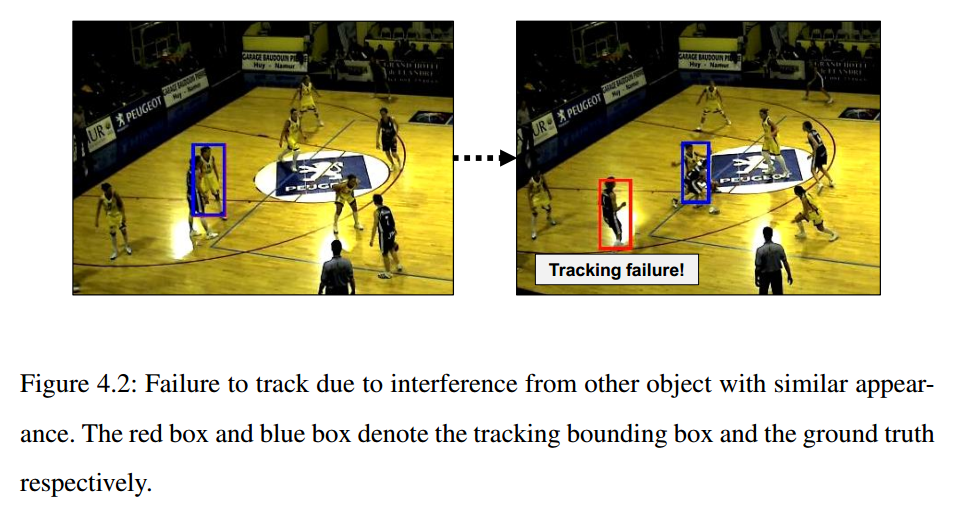
那么,如何解决这种问题呢?
作者提出了一种新颖的结合多个物体 patch 的方法来解决上述问题,并且结合 多智能体强化学习方法,提出了一种基于智能体之间相互交流的方法:
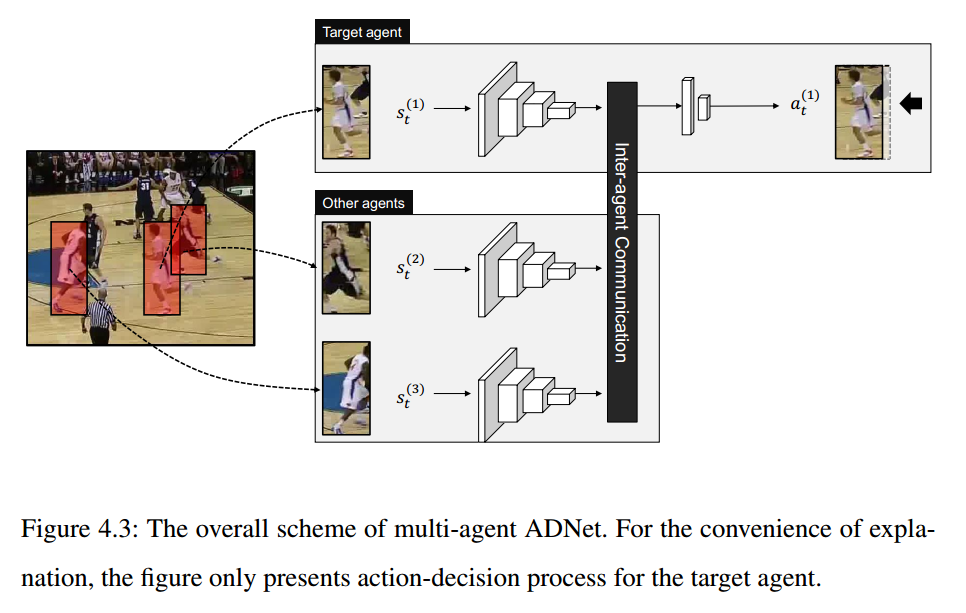
多智能体之间进行交流本来也是非常热的一个研究问题,本文将其结合到跟踪问题中去,来解决 Context 信息的问题,并且设计出了上述的网络结构,思路是比较直观的。
那么,本文的baseline 方法是:多个 agent 无交流的进行动作的选择的网络:
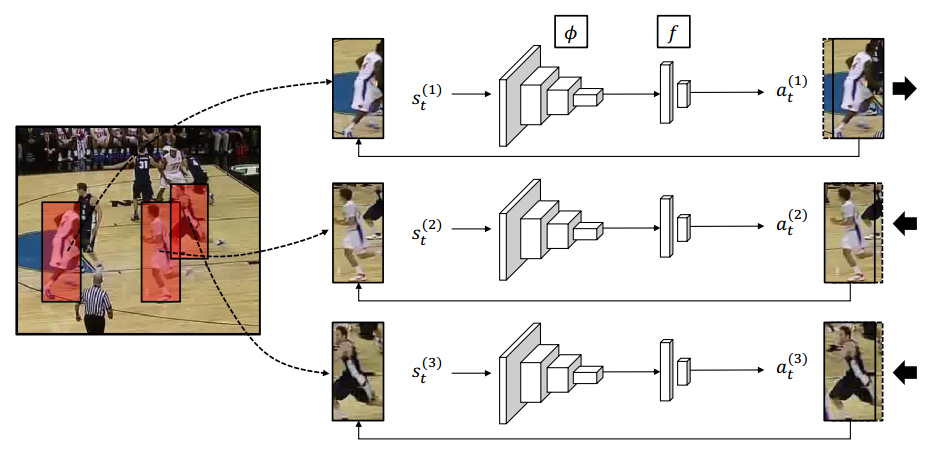
==================================================================================================================================
==================================================================================================================================
==================================================================================================================================
本文所提出的方法框架为:
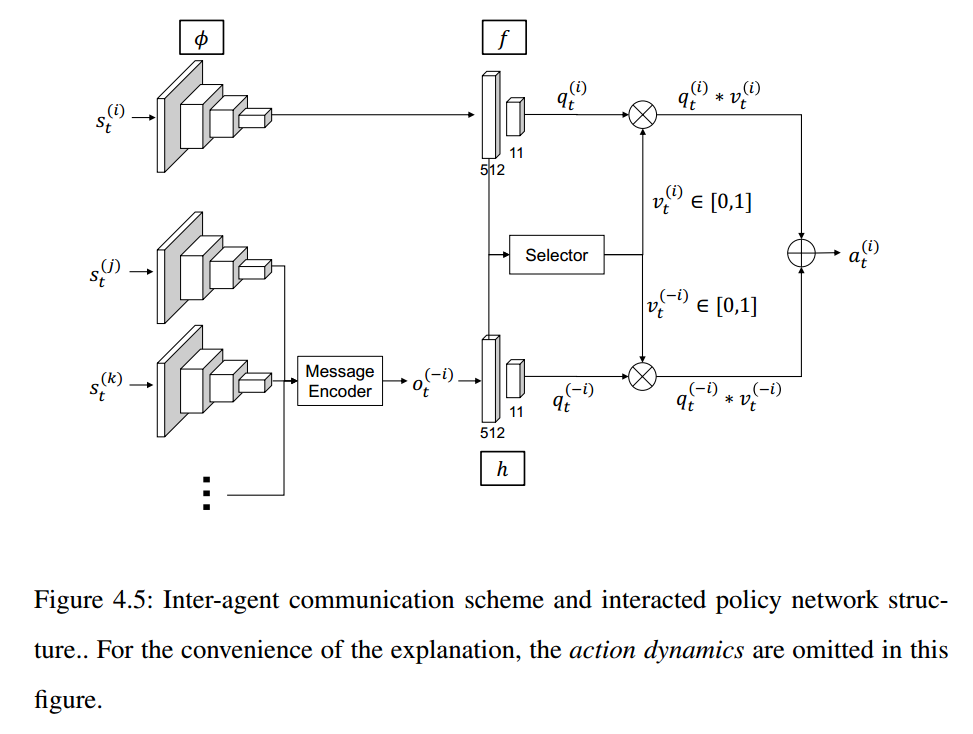
该网络主要有三个部分构成:
1. Feature Encoder;
2. Message Encoder;
3. Selector;
==================================================================================================================================
==================================================================================================================================
==================================================================================================================================
接下来,分别进行介绍:
1. feature encoder 没啥好介绍的,就是用 CNN 提取特征;
2. 信息编码网络,就是特征的叠加;
3. Selector: In order to combine the two primitive actions, the action selector module (Section 4.3.2.2) is proposed.
可以看出,本文引入这个,就是为了将两个网络的输出,进行叠加,融合两个网络的输出。

该选择器,有两维的输出,将两个网络初始的 action 分布,进行加权处理,最终融合为一个网络(多么熟悉的套路)。

可以看出,这个网络的设计,考虑到了 patch块的空间位置信息(Context 信息)。

然后,就是网络的训练,本文采用的是分阶段训练的(虽然可以 end to end 的进行 training),分别对这三个子网络进行训练。


Interacted Action-Driven Visual Tracking Algorithm的更多相关文章
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space 2018-01-04 ...
- Correlation Filter in Visual Tracking
涉及两篇论文:Visual Object Tracking using Adaptive Correlation Filters 和Fast Visual Tracking via Dense Spa ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- Particle filter for visual tracking
Kalman Filter Cons: Kalman filtering is inadequate because it is based on the unimodal Gaussian dist ...
- Siam R-CNN: Visual Tracking by Re-Detection
Siam R-CNN: Visual Tracking by Re-Detection 2019-12-02 22:21:48 Paper:https://128.84.21.199/abs/1911 ...
- Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking 2019-07-30 14:55:31 Paper: http ...
- Adaptive Decontamination of the Training Set: A Unified Formulation for Discriminative Visual Tracking
Martin Danelljan 判决类追踪模型是由训练样本学习得到,但是为了适应目标和背景的变化sample set在每一帧中都会更新. 令(xjk, yjk)表示第k帧k={1,2,...,t}中 ...
- (转)CVPR 2016 Visual Tracking Paper Review
CVPR 2016 Visual Tracking Paper Review 本文摘自:http://blog.csdn.net/ben_ben_niao/article/details/52072 ...
- 论文笔记之: Hierarchical Convolutional Features for Visual Tracking
Hierarchical Convolutional Features for Visual Tracking ICCV 2015 摘要:跟卢湖川的那个文章一样,本文也是利用深度学习各个 layer ...
随机推荐
- 爬虫之 BeautifulSoup与Xpath
知识预览 BeautifulSoup xpath BeautifulSoup 一 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: '' ...
- Mongodb数据存储优缺点
相对于Mysql来说 在项目设计的初期,我当时有了这样的想法,同时也是在满足下面几个条件的情况下来选择最终的nosql方案的: 1.需求变化频繁:开发要更加敏捷,开发成本和维护成本要更低,要能够快速地 ...
- 【视频】谷歌大佬30分钟让你入门机器学习(2019谷歌I/O资源分享)
如果你是个谷粉,就一定会知道: 谷歌向来都很大胆.当所有的科技公司都在讲产品.讲利润的时候,2019年的谷歌开发者大会的主题却是:人文关怀.要知道,这是政府操心的事,而不是一家公司的任务. 谷歌敢这样 ...
- TLS1.3 握手协议的分析
1.LTS支持的三种基本的密码交换模式 (EC)DHE (Diffie-Hellman both the finte field and ellptic curve varieties) PSK-on ...
- PAT基础级-钻石段位样卷2-7-3 大笨钟 (10 分)
微博上有个自称“大笨钟V”的家伙,每天敲钟催促码农们爱惜身体早点睡觉.不过由于笨钟自己作息也不是很规律,所以敲钟并不定时.一般敲钟的点数是根据敲钟时间而定的,如果正好在某个整点敲,那么“当”数就等于那 ...
- How to parse unix timestamp to time.Time
The time.Parse function does not do Unix timestamps. Instead you can use strconv.ParseInt to parse ...
- Git 的用法
对于GIT 的用法,最近一直在寻找方法.网上也能找到一些方法.但是感觉说的不是很清楚,在这里我基于自己经验写一些. 对于任何一种方法都要安装GIT. 我是基于VS Code 2015 来做的. 在安 ...
- java UDP 通信:服务端与客服端
import java.io.IOException; import java.net.DatagramPacket; import java.net.DatagramSocket; import j ...
- 使用Anaconda管理Python环境
修改镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda con ...
- BZOJ3514 GERALD07加强版
GERALD07 Description N个点M条边的无向图,询问保留图中编号在[l,r]的边的时候图中的联通块个数. Input 第一行四个整数N.M.K.type,代表点数.边数.询问数以及询问 ...