【转载】 AutoML总结
原文地址:
https://jinxin0924.github.io/2017/12/21/AutoML%E6%80%BB%E7%BB%93/
Posted by JxKing on December 21, 2017
---------------------------------------------------------------------------------------------------------------
前言
AutoML是指尽量不通过人来设定超参数,而是使用某种学习机制,来调节这些超参数。这些学习机制包括传统的贝叶斯优化,(multi-armed bandit),进化算法,还有比较新的强化学习。
我将AutoML分为传统AutoML ,自动调节传统的机器学习算法的参数,比如随机森林,我们来调节它的max_depth, num_trees, criterion等参数。 还有一类AutoML,则专注深度学习。这类AutoML,不妨称之为深度AutoML ,与传统AutoML的差别是,现阶段深度AutoML,会将神经网络的超参数分为两类,一类是与训练有关的超参数,比如learning rate, regularization, momentum等;还有一类超参数,则可以总结为网络结构。对网络结构的超参数自动调节,也叫 Neural architecture search (nas) 。而针对训练的超参数,也是传统AutoML的自动调节,叫 Hyperparameter optimization (ho) 。
贝叶斯优化
贝叶斯优化是一种近似逼近的方法,用各种代理函数来拟合超参数与模型评价之间的关系,然后选择有希望的超参数组合进行迭代,最后得出效果最好的超参数组合。
算法流程
- 初始化,随机选择若干组参数x,训练模型,得到相应的模型评价指标y
- 用代理函数来拟合x,y
- 用采集函数来选择最佳的x*
- 将x*带入模型,得到 新的y,然后进入第2步
具体算法
| 算法 | 代理函数 | 采集函数 | 优缺点 |
|---|---|---|---|
| BO | 高斯过程 | Expected Improvement | 应用广泛,在低维空间表现出色 |
| SMAC | 回归随机森林 | Upper Confidence Bound | 对离散型变量表现出色 |
| TPE | 高斯混合模型 | Expected Improvement | 高维空间表现出色,有论文表明最实用 |
特点
需要消耗大量资源及时间。由于需要至少几十次迭代,即需要训练几十次的模型,因而会造成大量资源、时间消耗。基于这个特点,可以说贝叶斯优化算法适合传统AutoML ,而不适合深度AutoML
效果不稳定。由于初始化存在随机性,其效果不稳定。也有论文表明,贝叶斯优化算法并不显著优于随机搜索(random search)
Multi-armed Bandit
multi-armed bandit是非常经典的序列决策模型,要解决的问题是平衡“探索”(exploration)和“利用”(exploitation)。
举一个bandit例子,你有20个按钮,每个按钮按一次可能得到一块钱或者拿不到钱,同时每个按钮的得到一块钱的概率不同,而你在事前对这些概率一无所知。在你有1000次按按钮的机会下,呼和得到最大收益。
这类算法,通过将自动调参问题,转化为bandit问题,配置更多资源给表现更优异的参数模型。
具体算法
Hyperband是一个颇具代表的算法。总体思路我们由一个自动调节LeNet的例子来展示:

R=81代表总资源,$\mu$ 代表每次筛选的比例,ni代表参数配置的组合数,ri代表资源数,这里代表一个epoch,第一行代表随机得到ni个参数配置,然后经过第ri次迭代之后,根据模型validation loss选择出top k个表现好的模型,继续下一行ri的训练。
特点
- Bandit思想还是很重要的,是一类针对资源配置的算法,可以有效避免资源浪费在很差的参数配置上。
- Bandit结合贝叶斯优化,就构成了传统的AutoML的核心,比如伯克利的这篇paper,或者今年cmu的atm 。事实上,在华为,我也搞了这方面的专利,核心也是Bandit与贝叶斯优化。
- Bandit同样适合于深度AutoML中nas任务,但是对ho任务的应用,我是存疑的,比如学习率lr 一大一小两组实验,在前期极有可能是大lr那组的loss下降快,如果用bandit判断这个lr优秀,而停止了另一组的实验,很有可能造成错误。因为大的学习率,在前期可能确实会加快收敛,但是一段时间后,可能就会震荡了,最后的收敛精度可能就很低。
进化算法
一般的进化算法其实大同小异,差别在如何选择变异,有比较细的变异,比如在Large-Scale Evolution of Image Classifiers 这篇文章中,就定义了非常具体的变异,比如有改变通道数量,改变filter大小,改变stride等等;而在Simple And Efficient Architecture Search for Convolutional Neural Networks这篇论文中,它的变异,就借鉴了现有公认的比较好的结构,加深网络就用conv-bn-relu3件套,加宽网络加大通道数量,增加skip connection。
这些进化算法在做自动模型选择时,每次迭代都不可避免的需要在整个数据集上跑若干个epoch,而每次迭代都有许多个变异,又需要很多次迭代,导致最后的训练时间太久。
fine-tune基础上的进化
Simple And Efficient Architecture Search for Convolutional Neural Networks 这篇论文提出,我们先用一个成熟的模型去训练(也可以fine-tune训练),然后在这个模型的基础上去变异,变异之后用fine-tune训练几个epoch即可。这带来两个好的结果:
- fine tune减少了大量的训练时间
- 我们最后拿出来的模型,至少不比成熟模型差
个人认为,这篇论文很有实际意义。
辅助网络初始化参数
SMASH: One-Shot Model Architecture Search through HyperNetworks 在这篇论文中,介绍了一种利用辅助网络给不同的网络初始化参数,从而无需重训练的方法。
其大致流程是在一堆待搜索的网络结构中,随机挑选数据和网络结构,用辅助网络负责参数初始化,然后训练用梯度下降训练这个辅助网络。在该辅助网络训练的足够好之后,就可以用它给各个不同的网络初始化参数,然后测试validation loss,最后挑出最优的网络结构,从头开始正常训练。
该方法通过训练一次辅助网络,避免每个网络都需要训练的情况,使得训练时间大大减小。该方法非常具有参考意义。
强化学习
强化学习在nas和ho两方面都有应用。
强化学习-自动网络结构搜索
Learning Transferable Architectures for Scalable Image Recognition
用RNN作为controller,产生网络结构,然后根据收敛精度调节rnn。
将整个网络分为两种cell,Normal cell 和 Reduction cell,每个cell有B个block组成,而一个cell由rnn生成的过程如图所示:

- 选择一个hidden layer A
- 选择一个hidden layer B
- 为A选择一个op
- 为B选择一个op
- 选择一个结合op
- 重复1-5步骤B次,生成一个cell
该方法现在cifar10上寻找到两种cell的结构,然后迁移到imagenet上。
值得注意的是,该方法虽然效果惊人,但是人为的提前设定非常多:
- 每个cell有B个block组成,B是人为设定的值,这里被设为了5;
- cell的数量及cell的排序顺序都是提前订好的;
因此在这个网络结构的搜索中,模型的探索空间有限,同时它在cifar10上进行训练,因此它的速度还不错。
强化学习-超参数
Neural Optimizer Search with Reinforcement Learning
用RNN作为optimizer的controller,产生optimizer,然后用小的cnn模型训练5个epoch,得到的val_acc作为reward,训练。
将每个optimizer抽象的表达为:
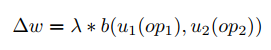
比如:

最后产生了两类optimizer:

【转载】 AutoML总结的更多相关文章
- 【转载】 什么是AutoML
文章来源:企鹅号 - 仲耀晖的碎碎念 tzattack Studio presents 来源:Google AI Blog 编译:仲耀晖 ------------------------------- ...
- 【转载】 第四范式涂威威:AutoML技术现状与未来展望
原文地址: https://www.jiqizhixin.com/articles/2018-07-12-17 -------------------------------------------- ...
- (转载) AutoML 与轻量模型大列表
作者:guan-yuan 项目地址:awesome-AutoML-and-Lightweight-Models 博客地址:http://www.lib4dev.in/info/guan-yuan/aw ...
- 【转载】 AutoML相关论文
原文地址: https://www.cnblogs.com/marsggbo/p/9308518.html ---------------------------------------------- ...
- 【转载】 AutoML技术现状与未来展望
原文地址: https://www.cnblogs.com/marsggbo/p/9309520.html ---------------------------------------------- ...
- 【转载】 一文看懂深度学习新王者「AutoML」:是什么、怎么用、未来如何发展?
原文地址: http://www.sohu.com/a/249973402_610300 原作:George Seif 夏乙 安妮 编译整理 ============================= ...
- 【转载】 自动化机器学习(AutoML)之自动贝叶斯调参
原文地址: https://blog.csdn.net/linxid/article/details/81189154 ---------------------------------------- ...
- 实录分享 | 计算未来轻沙龙:揭秘AutoML技术(视频 + PPT)
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/83542784 10 月 27 日 ...
- Crystal Clear Applied: The Seven Properties of Running an Agile Project (转载)
作者Alistair Cockburn, Crystal Clear的7个成功要素,写得挺好. 敏捷方法的关注点,大家可以参考,太激动所以转载了. 原文:http://www.informit.com ...
随机推荐
- Linux VPS搭建蚂蚁笔记Leanote私有云笔记存储平台
一.基础环境LNMP 安装nginx: yum install epel-release -y yum install nginx -y # 启动 nginx systemctl start ngin ...
- Linux的desktop文件正常编写赋权,仍无法打开解决办法
Linux的desktop文件正常编写赋权,仍无法打开解决办法 如果你像我一样遇到了这个问题, 明明都没有问题, desktop文件不显示图标, 双击打开是文本编辑器, 同时也有执行权限 打开却是这样 ...
- concat以及group_concat的用法
concat()函数 1.功能:将多个字符串连接成一个字符串. 2.语法:concat(str1, str2,...) 返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null ...
- 洛谷P2396 yyy loves Maths VII【状压dp】
题目:https://www.luogu.org/problemnew/show/P2396 题意:有n个数,每次选择一个表示走$a[i]$步,每个数只能选一次. 最多有两个厄运数字,如果走到了厄运数 ...
- idea在src/main/java下新建包后项目中只显示src/main,后面的东西不显示,但在本地磁盘中是存在的
去掉图中的勾
- sql server 计算属性,计算字段的用法与解析
SQL学习之计算字段的用法与解析 一.计算字段 1.存储在数据库表中的数据一般不是应用程序所需要的格式.大多数情况下,数据表中的数据都需要进行二次处理.下面举几个例子. (1).我们需要一个字段同 ...
- VSCodeUserSetup安装教程
VSCodeUserSetup: isual Studio Code是一个轻量级但功能强大的源代码编辑器,可在桌面上运行,适用于Windows,macOS和Linux.它内置了对JavaScript, ...
- mongodb 开发规范
一.命名规则 1.数据库命名规则 数据库名可以是满足以下条件的任意UTF-8字符串: (1)不能是空字符串(”") : (2)不能含有”(空格)...$./..和(空字符): (3)应全部小 ...
- Jquery使用心得
1.<form>提交时,会提交里面有name属性的元素,而不是id属性 $("#form").serialize(); 得到里面每个元素的拼接值 id=1& ...
- 51 NOD 1244 莫比乌斯函数之和(杜教筛)
1244 莫比乌斯函数之和 基准时间限制:3 秒 空间限制:131072 KB 分值: 320 难度:7级算法题 收藏 关注 莫比乌斯函数,由德国数学家和天文学家莫比乌斯提出.梅滕斯(Mertens) ...