Solr 7.X 安装和配置--Linux篇
1. 关闭防火墙和Selinux
2. 安装所需环境JDK
3. 下载Solr7.4版本
4. 下载并配置solr的中文分词器IK Analyzer
5. 启动Solr
6. 注意事项以及说明
1. 关闭防火墙和Selinux
Linux的防火墙是咱们新手的噩梦,很多情况会出现能ping通,但是访问不了Web页面。所以开始就干掉它!
1.1 关闭防火墙
[root@localhost ~]# /etc/init.d/iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
1.2 开机自动关闭防火墙
[root@localhost ~]# chkconfig iptables off
1.3 查看Selinux状态
[root@localhost ~]# sestatus
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 28
1.4 关闭selinux
[root@localhost ~]# vi /etc/selinux/config
修改 SELINUX=disabled ,重启机器。
注:永久开启->改成:SELINUX=enforcing
2. 安装所需环境JDK
JDK版本: 1.8
直接参考本文:https://my.oschina.net/u/3209432/blog/1576928
3. 下载并安装Solr 7.4版本
注:为了方便管理,创建一个文件夹专门放所需软件
[root@localhost /]# mkdir developer
[root@localhost /]# cd developer
3.1 下载Solr 7.4
[root@localhost developer]# wget http://mirror.bit.edu.cn/apache/lucene/solr/7.4.0/solr-7.4.0.tgz
注:Solr7.4 官网url如下:
http://www.apache.org/dyn/closer.lua/lucene/solr/7.4.0
有三个单独的包:
solr-7.4.0.tgz适用于Linux / Unix / OSX系统solr-7.4.0.zip适用于Microsoft Windows系统solr-7.4.0-src.tgz包Solr源代码。如果您想在不使用官方Git存储库的情况下在Solr上进行开发,这将非常有用。
3.2 解压Solr 7.4
[root@localhost developer]# tar -zxvf solr-7.4.0.tgz
4. 下载并配置solr的中文分词器IK Analyzer
4.1 下载中文分词器IK Analyzer
[root@localhost developer]# wget https://download.loubobooo.com/Solr/ikanalyzer-solr5.5.zip
4.2 解压
[root@localhost developer]# unzip ikanalyzer-solr5.5.zip
注意:如果没有unzip的话,输入 yum -y install unzip 来进行安装
4.3 配置中文分词器IK Analyzer
4.3.1 进入IK Analyzer文件夹
[root@localhost developer]# cd ikanalyzer-solr5
4.3.2 把IKAnalyzer依赖的jar包添加到solr工程中
[root@localhost ikanalyzer-solr5]# cp *.jar /developer/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/lib/
4.3.3 创建所需文件夹
[root@localhost ikanalyzer-solr5]# mkdir /developer/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/classes
4.3.4 复制分词的配置文件到solr目录下
[root@localhost ikanalyzer-solr5]# cp ext.dic IKAnalyzer.cfg.xml stopword.dic /developer/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/classes
4.4 手动创建core(此处可以选择在solr的管理页面创建)
4.4.1 进入solr目录
[root@localhost ikanalyzer-solr5]# cd /developer/solr-7.4.0/server/solr
4.4.2 创建core
[root@localhost solr]# mkdir test_core
4.4.3 进入test_core
[root@localhost solr]# cd test_core
4.4.4 编辑core.properties
[root@localhost test_core]# vim core.properties
4.4.5 创建data文件目录
[root@localhost test_core]# mkdir data
4.4.6 拷贝一个conf到test_core下面
[root@localhost test_core]# cp -r developer/solr-7.4.0/server/solr/configsets/sample_techproducts_configs/conf/ ./
此时core创建完成,重启solr,进入管理页面,便可以看到刚创建的core
4.5 编辑managed-schema配置文件
[root@localhost test_core]# cd conf
[root@localhost test_core]# vim managed-schema
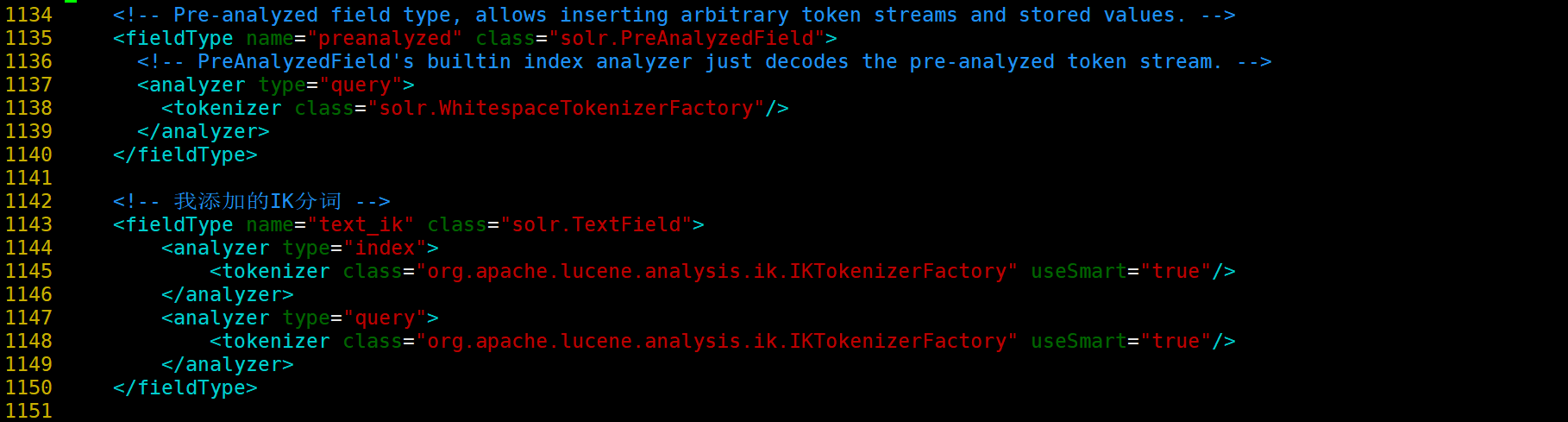
添加如下配置
<!-- 我添加的IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
4.6 继续添加业务域
在managed-schema文件末尾继续添加如下配置:
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="plong" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" /><field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>
5. 启动solr
5.1 进入solr根目录
[root@localhost test_core]# cd /developer/solr-7.4.0
5.2 启动solr
[root@localhost solr-7.4.0]# bin/solr start -force
注意:用户若是root,则需要加 -force 来启动
5.3 查看solr状态
[root@localhost solr-7.4.0]# bin/solr status
5.4 打开并查看solr管理页面
打开浏览器,输入ip:8983/solr
http://192.168.182.128:8983/solr
5.5 关闭solr
[root@localhost solr-7.4.0]# bin/solr stop
6. 注意事项以及说明
注意事项:
Solr 7.4 有对应的JDK版本最低为1.8,检查jdk版本是否匹配,不则启动Solr就会报错
检查jdk:
[root@localhost ~]# java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
说明:本次使用
操作系统:CentOS 6.8 64位
Solr版本:7.4
JDK版本:1.8.0_144
Solr 7.X 安装和配置--Linux篇的更多相关文章
- Ubuntu下VIM的安装及其配置——Linux篇
一.Ubuntu系统默认内置: 实际上ubuntu默认没有安装老版本的vi,只装了vim.vi是vim.tiny(vim的最小化版本,不含 GUI,并且仅含有一小部分功能,并且默认与vi兼容.此软件包 ...
- 在hyper-v虚拟机中安装并配置linux
虽然都是自己写的,还是贴个原文链接吧,如果文章里的图片错乱了,可能就是我贴错了,去看原文吧. 多图警告 WSL2真香? WSL2相比于WSL1前者更类似于虚拟机,配合上Windoes Terminal ...
- 磁盘分区对齐详解与配置 – Linux篇
在之前一篇<磁盘分区对齐详解与配置 – Windows篇>中,我介绍了磁盘分区对齐的作用和适用于MBR和GPT的两种磁盘类型的配置,以及Windows平台设置磁盘分区对齐的方法. 本文作为 ...
- 最新版redis的安装及配置 linux系统
1.redis下载 官网地址:https://redis.io/download 百度云地址:链接:http://pan.baidu.com/s/1c1Hu2gK 密码:h17z 2.解压 [root ...
- zabbix_agentd客户端安装与配置(Linux操作系统)
标注:官网下载zabbix安装包(zabbix安装包里包含了zabbix_agentd客户端安装包,我们只选择zabbix_agentd客户端安装) zbbix官网下载地址: http://www. ...
- Haroopad安装与配置: Linux系统下最好用的Markdown编辑器
1. Haroopad概述 Haroopad is a markdown enabled document processor for creating web-friendly documents. ...
- nagios客户端安装与配置windows篇
一.被监控的windows xp客户端的配置 1.安装NSClient++并安装下载地址: http://sourceforge.net/projects/nscplusNSClient++-0.3. ...
- JDK安装及配置——Linux系统
一.首先下载JDK版本 链接如下:https://www.oracle.com/technetwork/java/javase/downloads/index.html 截止写博客时,最新版已经到12 ...
- 安装和配置Linux系统虚拟机
1.打开虚拟机软件 2.点击创建新的虚拟机,选择典型(推荐)类型的配置. 3.点击稍后安装操作系统. 4.客户机操作系统选择Linux,版本选择CentOS 7 64位. 5.虚拟机名称可自行更改,位 ...
随机推荐
- 22-MySQL DBA笔记-其他产品的选择
第22章 其他产品的选择 本章将为读者介绍其他的数据库产品,主要是NoSQL产品的选择.读者在熟悉MySQL之外,也应该了解其他的数据库产品.本章的目的是给读者一个引导,如何选择一些NoSQL产品,而 ...
- D盘Program Files 文件夹里文件不显示,没隐藏。怎么才能显示出来?
D盘里有两个一模一样的Program Files 文件夹,文件夹里文件不显示,没隐藏.怎么才能显示出来?新买不久的电脑,win8.1系统 点击开始---运行---输入“cmd”(没有引号)---在弹出 ...
- MySQL INNER JOIN子句介绍
MySQL INNER JOIN子句介绍 MySQL INNER JOIN子句将一个表中的行与其他表中的行进行匹配,并允许从两个表中查询包含列的行记录. INNER JOIN子句是SELECT语句的可 ...
- 国际化(i18n)学习
一 软件的国际化:软件开发时,要使它能同时应对世界不同地区和国家的访问,并针对不同地区和国家的访问,提供相应的.符合来访者阅读习惯的页面或数据. 国际化(internationalization)又称 ...
- [JZOJ5888]GCD生成树
[JZOJ5888]GCD生成树 题目链接 gugugu 分析 对于N很小的情况,暴力Prim即可 对于值域很小的情况,我的想法与solution不太一样,将值相同的缩成一个点,\(O(w^2)\)预 ...
- java实现当前时间往前推N小时
import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.Date; /** * @author sha ...
- moment.js(日期处理类库)的使用
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 关于vue.js的部分总结
1.MVVM和MVC的区别: MVVM:是Model-View-ViewModel的简写,即模型-视图-视图模型 模型:后端传递的数据 试图:所看到的页面 视图模型:mvvm模式的核心,它是连接vie ...
- 堆(heap)和栈(stack)、内存泄漏(memory leak)和内存溢出
来源:http://blog.itpub.net/8797129/viewspace-693648/ 简单的可以理解为:heap:是由malloc之类函数分配的空间所在地.地址是由低向高增长的.sta ...
- Java学习第二天之Java程序的基本规则
一.Java程序的组织形式 Java程序是一种纯粹的面向对象的程序设计语言,因此Java程序必须以类(即class)的形式存在,类(class)是Java程序的最小程序单位.Java程序不允许可执行性 ...