负样本采样及bias校准、ctr平滑
参考:https://zhuanlan.zhihu.com/p/31529643
在CTR预估中,负样本采样是一种常见的特征工程方法。一般CTR预估的原始正负样本比可能达到1:1000~1:10000左右,而要获取好的效果,一般需要采样到1:5~1:15之间(VC维可推导)。
我们详细分析采样对于pCTR的影响。
设采样前CTR为 ,采样后CTR为
,正样本数为
,负样本数为
,正样本采样概率为
,负样本采样概率为
,其中 $n=m/l$。
$ p = \frac{a}{a + b}$
$p' = \frac{la}{la + mb} = \frac{a}{(a + nb)} $
两者化简得到:$p = \frac{p'}{p' + (1 - p') / n}$
注意 $p$为我们希望得到的校准后概率;但由于我们用采样的数据进行训练,模型计算出的pCTR实际为校准前概率$p'$ 。
可以看到,负采样之后的pCTR值会被高估【$p' + (1-p')/n > 1$】。这对于一般的CTR排序影响不大,但对于DSP这类有强烈的保距需求的场景,需要将pCTR校准回对采样前的估计。
对于LR、FM等用logistics function做处理的模型,可以得到
$p' = \frac{p}{n + p -np} = \frac{1}{1 + e^{-(w^Tx + b)}}$
两者化简可得
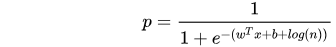
因此可以计算出校准后的bias: $b' = b + log(n)$
参考: http://d0evi1.com/ctr-smooth/ http://www.flickering.cn/%E6%95%B0%E5%AD%A6%E4%B9%8B%E7%BE%8E/2014/06/lda%E6%95%B0%E5%AD%A6%E5%85%AB%E5%8D%A6%E8%AE%A4%E8%AF%86betadirichlet%E5%88%86%E5%B8%83/
伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生。
二项分布:重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。
二项分布概率:
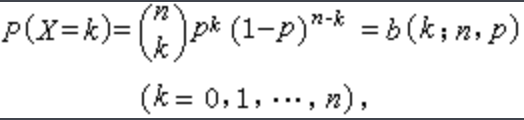
beta分布:beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。beta分布的定义域是(0,1),与概率的范围是一致的。它有两个正值参数,称为形状参数,一般用$\alpha$ 和 $\beta$表示。
Beta分布的均值是: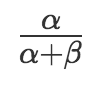
方差是: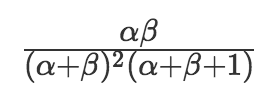
以后再看吧~~~
负样本采样及bias校准、ctr平滑的更多相关文章
- 4 关于word2vec的skip-gram模型使用负例采样nce_loss损失函数的源码剖析
tf.nn.nce_loss是word2vec的skip-gram模型的负例采样方式的函数,下面分析其源代码. 1 上下文代码 loss = tf.reduce_mean( tf.nn.nce_los ...
- c#解析XML文件来获得pascal_voc特定目标负样本
近期在做船仅仅识别方面的事情,须要大量的负样本来训练adaboost分类器. 我从网上下载到一个pascal_voc的数据集.须要找到不包括船仅仅的那些复制出来. 数据集特点 对于每一个图片有一个xm ...
- 归纳学习(Inductive Learning),直推学习(Transductive Learning),困难负样本(Hard Negative)
归纳学习(Inductive Learning): 顾名思义,就是从已有训练数据中归纳出模式来,应用于新的测试数据和任务.我们常用的机器学习模式就是归纳学习. 直推学习(Transductive Le ...
- 【项目】百度搜索广告CTR预估
-------倒叙查看本文. 6,用auc对测试的结果进行评估: auc代码如下: #!/usr/bin/env python import sys def auc(labels,predicted_ ...
- KDDCUP CTR预测比赛总结
赛题与数据介绍 给定查询和用户信息后预测广告点击率 搜索广告是近年来互联网的主流营收来源之一.在搜索广告背后,一个关键技术就是点击率预测-----pCTR(predict the click-thro ...
- 美团DSP
https://blog.csdn.net/LW_GHY/article/details/71455535 ADX出价调整, 预估ctr抽样后调整还原 2. 动态调整报价在DSP的报价环节,点击率预估 ...
- DSSM在召回和粗排的应用举例
0.写在前面的话 DSSM(Deep Structured Semantic Models)又称双塔模型,因其结构简单,在推荐系统中应用广泛:下面仅以召回.粗排两个阶段的应用举例,具体描述下DSSM在 ...
- GAN笔记——理论与实现
GAN这一概念是由Ian Goodfellow于2014年提出,并迅速成为了非常火热的研究话题,GAN的变种更是有上千种,深度学习先驱之一的Yann LeCun就曾说,"GAN及其变种是数十 ...
- DLNg序列模型第二周NLP与词嵌入
1.使用词嵌入 给了一个命名实体识别的例子,如果两句分别是“orange farmer”和“apple farmer”,由于两种都是比较常见的,那么可以判断主语为人名. 但是如果是榴莲种植员可能就无法 ...
随机推荐
- Python+Selenium框架设计篇之-简单介绍unittest单元测试框架
前面文章已经简单介绍了一些关于自动化测试框架的介绍,知道了什么是自动化测试框架,主要有哪些特点,基本组成部分等.在继续介绍框架设计之前,我们先来学习一个工具,叫unittest. unit ...
- nyoj 题目20 吝啬的国度
吝啬的国度 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 在一个吝啬的国度里有N个城市,这N个城市间只有N-1条路把这个N个城市连接起来.现在,Tom在第S号城市, ...
- 在iBatis中操作Blob数据类型
这里的Blob数据类型指的是保存了文本的blob数据类型 直接读取blob类型存储的文本,可能会出现乱码,所以需要读取完后进行手动转码 这里使用ibatis作为持久层 SELECT urlconten ...
- 【bzoj3217】ALOEXT 替罪羊树套Trie树
题目描述 taorunz平时最喜欢的东西就是可移动存储器了……只要看到别人的可移动存储器,他总是用尽一切办法把它里面的东西弄到手. 突然有一天,taorunz来到了一个密室,里面放着一排可移动存储器, ...
- java根据开始时间结束时间计算中间间隔日期
public static void main(String[] args) throws Exception { String beginDate = "2016-07-16"; ...
- 2 - Django基础
一.Django流程 Django是使用python编写的web框架,遵守MTV设计思想. 实现原理: 1,浏览器发起请求. 2,Django根据URL Conf指向view(Views) 3,vie ...
- 2017-2018-2 20179204《网络攻防实践》第十一周学习总结 SQL注入攻击与实践
第1节 研究缓冲区溢出的原理,至少针对两种数据库进行差异化研究 1.1 原理 在计算机内部,输入数据通常被存放在一个临时空间内,这个临时存放的空间就被称为缓冲区,缓冲区的长度事先已经被程序或者操作系统 ...
- pat 甲级 1072. Gas Station (30)
1072. Gas Station (30) 时间限制 200 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue A gas sta ...
- [AGC06D] Median Pyramid Hard (玄学)
Description 现在有一个N层的方块金字塔,从最顶层到最底层分别标号为1...N. 第i层恰好有2i−1个方块,且每一层的中心都是对齐的. 这是一个N=4的方块金字塔 现在,我们首先在最底层填 ...
- codechef AUG17 T5 Chef And Fibonacci Array
Chef has an array A = (A1, A2, ..., AN), which has N integers in it initially. Chef found that for i ...