验证 .NET 4.6 的 SIMD 硬件加速支持的重要性
SIMD 的意思是 Single Instruction Multiple Data。顾名思义,一个指令可以处理多个数据。
.NET Framework 4.6 推出的 Nuget 程序包 System.Numerics.Vectors 里面的 Vector`1 类型是有硬件加速功能的。这个硬件加速功能就是指即时编译的时候根据硬件环境选用一些 SIMD 的指令让程序运行更快。
这个硬件加速功能的威力可以用下面的方式得到验证。
用单线程的程序重复 10000000H 个单精度浮点数的加法。加法的每一个输入都是引用类型,输出也必须获取值的引用。
VB 2017 程序:
动态获取当前硬件支持一组算多少个单精度浮点数的加法,然后分组计算。Release x64 编译,优化代码(反编译验证没有优化掉循环),取消整数溢出检查(为了跟 c# 执行时间一样)。
VB
Imports System.Numerics
Module Program
Sub Main()
Const TotalDataSize = &H1000_0000
Dim watch As New Stopwatch
Dim groupSize = Vector(Of Single).Count
Dim groupCount = TotalDataSize / groupSize
Console.WriteLine($"每组数据的大小:{groupSize} (1:不优化,4:SSE2 优化,8:AVX2 优化)
一共要处理 {groupCount} 次数据以完成测试。")
Console.WriteLine("计时开始!")
watch.Start()
Dim groupA(groupSize - ), groupB(groupSize - ) As Single
Dim vecA As New Vector(Of Single)(groupA), vecB As New Vector(Of Single)(groupB), vecResult As Vector(Of Single)
For i = To groupCount
vecResult = vecA + vecB
Next
watch.Stop()
Console.WriteLine($"计时结束。用时:{watch.ElapsedMilliseconds} 毫秒。")
Console.ReadKey()
End Sub
End Module
VC++ 2017程序:
用循环 0x10000000 次的 for 循环,Release x64 编译,禁止优化(开优化不管循环多少次都是 0 毫秒,肯定是把循环优化掉了)。
C++
#include "stdafx.h"
#include <iostream>
#include "NotOptimizedNativeCodes.h" const int TotalDataSize = 0x10000000; #pragma unmanaged void NativeTest()
{
float groupA[] = { }, groupB[] = { }, *groupResult;
for (size_t i = ; i < TotalDataSize; i++)
{
float result = groupA[] + groupB[];
groupResult = &result;
}
} #pragma managed using namespace System;
using namespace System::Diagnostics; int NotOptimizedNativeCodes::Program::main(array<System::String ^> ^args)
{
auto watch = gcnew Stopwatch();
std::cout << "每组数据的大小:" << << "(1:不优化,4:SSE2 优化,8:AVX2 优化)" << std::endl <<
"一共要处理" << TotalDataSize << " 次数据以完成测试。" << std::endl;
Console::WriteLine(L"计时开始!");
watch->Start();
NativeTest();
watch->Stop();
std::cout << "计时结束。用时:" << watch->ElapsedMilliseconds << " 毫秒。" << std::endl;
Console::ReadKey();
return ;
} int main(array<System::String ^> ^args)
{
NotOptimizedNativeCodes::Program::main(args);
}
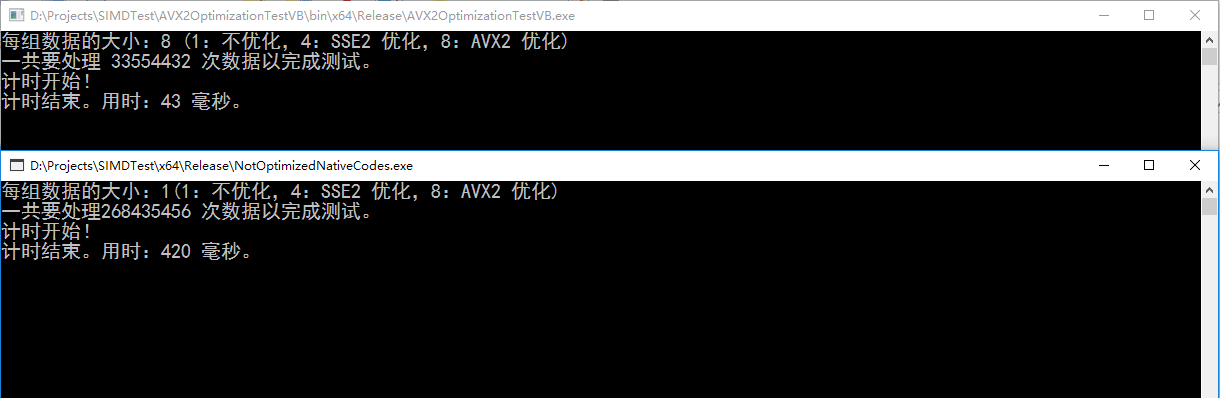
执行结果(CPU 是 i5 6400,有 AVX2 指令集)
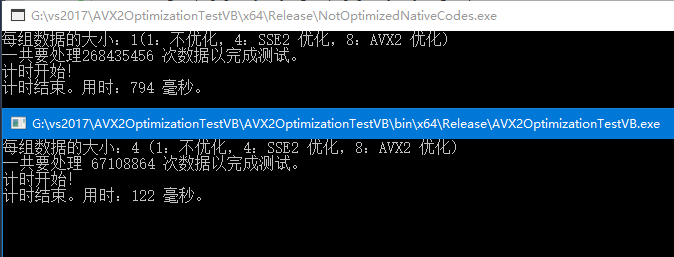
使用 i7 3632QM (没有 AVX2 但是有 SSE2)
验证 .NET 4.6 的 SIMD 硬件加速支持的重要性的更多相关文章
- 【视频开发】【CUDA开发】FFMPEG硬件加速-nvidia方案
1.目标 <1>显卡性能参数: <2>方案可行性: 2.平台信息 2.1.查看当前显卡信息 命令: lspci |grep VGA 信息: 01:00.0 VGA com ...
- CSS硬件加速的好与坏
本文翻译自Ariya Hidayat的Hardware Accelerated CSS: The Nice vs The Naughty.感谢Kyle He帮助校对. 每个人都痴迷于60桢每秒的顺滑动 ...
- FortiGate 硬件加速
FortiGate 硬件加速 来源 https://wenku.baidu.com/view/07749195a1c7aa00b52acb63.html 硬件加速 来源 https://blog.cs ...
- FFmpeg再学习 -- 硬件加速编解码
为了搞硬件加速编解码,用了一周时间来看 CUDA,接下来开始加以总结. 一.什么是 CUDA (1)首先需要了解一下,什么是 CUDA. 参看:百度百科 -- CUDA 参看:CUDA基础介绍 参看: ...
- Chromium硬件加速渲染的UI合成过程分析
在Chromium中.Render端和WebGL端绘制出来的UI终于是通过Browser端显示在屏幕上的.换句话说.就是Browser端负责合成Render端和WebGL端的UI.这涉及到不同Open ...
- 【并行计算-CUDA开发】【视频开发】ffmpeg Nvidia硬件加速总结
2017年5月25日 0. 概述 FFmpeg可通过Nvidia的GPU进行加速,其中高层接口是通过Video Codec SDK来实现GPU资源的调用.Video Codec SDK包含完整的的高性 ...
- 【并行计算与CUDA开发】英伟达硬件加速编解码
硬件加速 并行计算 OpenCL OpenCL API VS SDK 英伟达硬件编解码方案 基于 OpenCL 的 API 自己写一个编解码器 使用 SDK 中的编解码接口 使用编码器对于 OpenC ...
- ffmpeg实现dxva2硬件加速
这几天在做dxva2硬件加速,找不到什么资料,翻译了一下微软的两篇相关文档.这是第二篇,记录用ffmpeg实现dxva2. 第一篇翻译的Direct3D device manager,链接:http: ...
- 用CSS开启硬件加速来提高网站性能
国外一篇文章,有点意思,转载过来,准备尝试下~ 中文地址:http://www.cnblogs.com/rubylouvre/p/3471490.html 原文地址:http://blog.teamt ...
随机推荐
- ping测试网络
https://jingyan.baidu.com/article/ac6a9a5e109d5f2b653eacbc.html 百度百科:https://baike.baidu.com/item/pi ...
- sass编译命令
sass编译一个文件的方式 sass xx.scss:xx.css 这种方式只能编译一次,要是想一直监控编译,只要有保存更改就会立即编译,那么就需要下面这条命令了 sass --watch xx.sc ...
- C++ TUTORIAL - MEMORY ALLOCATION - 2016
http://www.bogotobogo.com/cplusplus/memoryallocation.php Variables and Memory Variables represent st ...
- 28.Docker介绍与目录
快速的部署和启动 docker的启动是毫秒级的.一分钟可移动几百个上千个docker的容器 docker和虚拟机的区别 虚拟机在里面独立运行完整的操作系统.资源上时间上都需要多. docker容器级别 ...
- [WIP]webpack入门
创建: 2019/04/09 安装 npm install --save-dev webpack # 最新版 npm install --save-dev webpack@<version&g ...
- 简单介绍Git两种拉取代码的方式
first: 1.通过git clone 命令克隆git库中的项目 注意:通过 git clone方式克隆的代码会在服务器上自动建一个与git库名相同的文件夹,所以有两种思路,第一种就是直接在wwwr ...
- lightoj 1074【spfa判负环】
题意: 给你一幅图,dis(u->v)的权值就是(w[v]-w[u])*(w[v]-w[u])*(w[v]-w[u]),所以有可能是负的,给你n个询问,给出最短路,长度<3或者不可达输出& ...
- [Xcode 实际操作]九、实用进阶-(8)实现App的Setting设置:添加和读取程序的配置信息
目录:[Swift]Xcode实际操作 本文将演示如何实现添加和读取程序的配置信息. 在项目文件夹[DemoApp]上点击鼠标右键->[New File]创建一个设置束文件 ->[Sett ...
- pycharm中模块matplolib生成图表出现中文乱码解决方法
在python文件中加入如下两行 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中 ...
- EasyUI/TopJUI可编辑表格的列根据返回数据判断是使用 combobox 还是 numberbox
这两天研究了一下topjui的可编辑表格edatagrid,想在每一列的后面根据返回的数据判断是使用 combobox 还是 numberbox,期间遇到了一些坑,下面实现代码,需要的朋友可以参考一下 ...