[神经网络]一步一步使用Mobile-Net完成视觉识别(四)
1.环境配置
2.数据集获取
3.训练集获取
4.训练
5.调用测试训练结果
6.代码讲解
本文是第四篇,下载预训练模型并训练自己的数据集。
前面我们配置好了labelmap,下面我们开始下载训练好的模型。
http://download.tensorflow.org/models/object_detection/ssdlite_mobilenet_v2_coco_2018_05_09.tar.gz
下载下来解压,然后我们配置下pipeline文件
需要改动的地方有
num_classes:这个是我们的分类数,我们只有red和blue就填2
batch_size:这里我填的是2,batch_size过大,每次放入内存中训练的数据就会越多,如果你的内存不够大且数据量比较小,就填小点,我的是8G内存,图片也不过一两千张。
initial_learning_rate:学习速率,可以不修改。
fine_tune_checkpoint:输入我们下载的模型的ckpt文件的绝对路径
label_map_path:配置好的labelmap的绝对路径
tf_record_input_reader的input_path:填之前生成好的tfrecord文件的绝对路径
我的配置为以下文件:
model {
ssd {
num_classes: 2
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
feature_extractor {
type: "ssd_mobilenet_v2"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
truncated_normal_initializer {
mean: 0.0
stddev: 0.0299999993294
}
}
activation: RELU_6
batch_norm {
decay: 0.999700009823
center: true
scale: true
epsilon: 0.0010000000475
train: true
}
}
use_depthwise: true
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
truncated_normal_initializer {
mean: 0.0
stddev: 0.0299999993294
}
}
activation: RELU_6
batch_norm {
decay: 0.999700009823
center: true
scale: true
epsilon: 0.0010000000475
train: true
}
}
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.800000011921
kernel_size: 3
box_code_size: 4
apply_sigmoid_to_scores: false
use_depthwise: true
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.20000000298
max_scale: 0.949999988079
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.333299994469
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 0.300000011921
iou_threshold: 0.600000023842
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.990000009537
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 3
}
classification_weight: 1.0
localization_weight: 1.0
}
}
}
train_config {
batch_size: 2
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
optimizer {
rms_prop_optimizer {
learning_rate {
exponential_decay_learning_rate {
initial_learning_rate: 0.00400000018999
decay_steps: 800720
decay_factor: 0.949999988079
}
}
momentum_optimizer_value: 0.899999976158
decay: 0.899999976158
epsilon: 1.0
}
}
fine_tune_checkpoint: "/home/xueaoru/models/research/ssdlite_mobilenet_v2_coco_2018_05_09/model.ckpt"
num_steps: 200000
fine_tune_checkpoint_type: "detection"
}
train_input_reader {
label_map_path: "/home/xueaoru/models/research/car_label_map.pbtxt"
tf_record_input_reader {
input_path: "/home/xueaoru/models/research/train.record"
}
}
eval_config {
num_examples: 60
max_evals: 10
use_moving_averages: false
}
eval_input_reader {
label_map_path: "/home/xueaoru/models/research/car_label_map.pbtxt"
shuffle: true
num_readers: 1
tf_record_input_reader {
input_path: "/home/xueaoru/models/research/test.record"
}
}
在models/research目录下执行以下命令:
python object_detection/model_main.py \
--pipeline_config_path=/home/xueaoru/models/research/ssdlite_mobilenet_v2_coco_2018_05_09/pipeline.config \
--num_train_steps=200000 \
--sample_1_of_n_eval_examples=25 \
--alsologtostderr \
--model_dir=/home/xueaoru/models/research/car_data
其中pipeline_config_path为之前配置好的pipeline的绝对路径
num_train_steps为训练步数
sample_1_of_n_eval_examples为每多少个验证数据抽样一次
alsologtostderr输出std错误信息
model_dir输出训练过程中的数据的存放文件夹
执行完以上命令之后,基本上训练就开始了,我们只需要通过tensorboard来看看训练效果就可以了
tensorboard --logdir car_data
打开输出的地址:
就可以看到训练效果啦
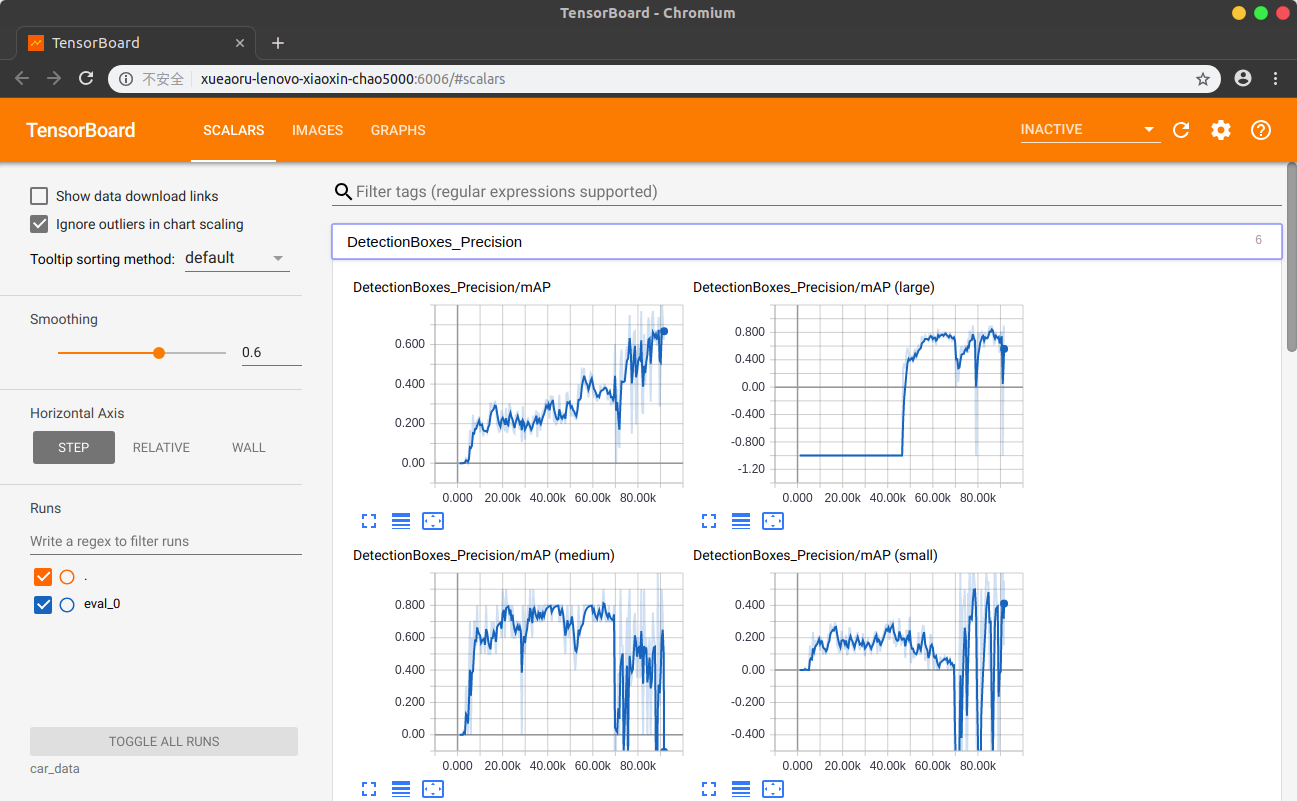
等到差不多收敛了,我们就可以输出我们的模型了
命令行输入以下命令:
python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path /home/xueaoru/models/research/ssdlite_mobilenet_v2_coco_2018_05_09/pipeline.config --trained_checkpoint_prefix /home/xueaoru/models/research/car_data/model.ckpt-87564 --output_directory /home/xueaoru/models/research/inference_graph_v2
配置基本上跟上面差不多,改改路径即可。
然后我们就在inference_graph_v2目录下拿到了训练后的模型了。
[神经网络]一步一步使用Mobile-Net完成视觉识别(四)的更多相关文章
- 一步一步理解word2Vec
一.概述 关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术.词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的 ...
- 如何一步一步用DDD设计一个电商网站(十二)—— 提交并生成订单
阅读目录 前言 解决数据一致性的方案 回到DDD 设计 实现 结语 一.前言 之前的十一篇把用户购买商品并提交订单整个流程上的中间环节都过了一遍.现在来到了这最后一个环节,提交订单.单从业务上看,这个 ...
- 如何一步一步用DDD设计一个电商网站(十三)—— 领域事件扩展
阅读目录 前言 回顾 本地的一致性 领域事件发布出现异常 订阅者处理出现异常 结语 一.前言 上篇中我们初步运用了领域事件,其中还有一些问题我们没有解决,所以实现是不健壮的,下面先来回顾一下. 二.回 ...
- NLP(二十九)一步一步,理解Self-Attention
本文大部分内容翻译自Illustrated Self-Attention, Step-by-step guide to self-attention with illustrations and ...
- 如何一步一步用DDD设计一个电商网站(九)—— 小心陷入值对象持久化的坑
阅读目录 前言 场景1的思考 场景2的思考 避坑方式 实践 结语 一.前言 在上一篇中(如何一步一步用DDD设计一个电商网站(八)—— 会员价的集成),有一行注释的代码: public interfa ...
- 如何一步一步用DDD设计一个电商网站(八)—— 会员价的集成
阅读目录 前言 建模 实现 结语 一.前言 前面几篇已经实现了一个基本的购买+售价计算的过程,这次再让售价丰满一些,增加一个会员价的概念.会员价在现在的主流电商中,是一个不大常见的模式,其带来的问题是 ...
- 如何一步一步用DDD设计一个电商网站(十)—— 一个完整的购物车
阅读目录 前言 回顾 梳理 实现 结语 一.前言 之前的文章中已经涉及到了购买商品加入购物车,购物车内购物项的金额计算等功能.本篇准备把剩下的购物车的基本概念一次处理完. 二.回顾 在动手之前我对之 ...
- 如何一步一步用DDD设计一个电商网站(七)—— 实现售价上下文
阅读目录 前言 明确业务细节 建模 实现 结语 一.前言 上一篇我们已经确立的购买上下文和销售上下文的交互方式,传送门在此:http://www.cnblogs.com/Zachary-Fan/p/D ...
- 如何一步一步用DDD设计一个电商网站(六)—— 给购物车加点料,集成售价上下文
阅读目录 前言 如何在一个项目中实现多个上下文的业务 售价上下文与购买上下文的集成 结语 一.前言 前几篇已经实现了一个最简单的购买过程,这次开始往这个过程中增加一些东西.比如促销.会员价等,在我们的 ...
- 如何一步一步用DDD设计一个电商网站(五)—— 停下脚步,重新出发
阅读目录 前言 单元测试 纠正错误,重新出发 结语 一.前言 实际编码已经写了2篇了,在这过程中非常感谢有听到观点不同的声音,借着这个契机,今天这篇就把大家提出的建议一个个的过一遍,重新整理,重新出发 ...
随机推荐
- Bootstrap 栅栏布局中 col-xs-*、col-sm-*、col-md-*、col-lg-* 区别及使用方法
(1)概括 一句话概括:根据显示屏幕宽度的大小,自动的选用对应的类的样式. (2)关键字段 1.col是column简写:列: 2.xs是maxsmall简写:超小, ...
- 非常实用的Sublime插件集合 – sublime推荐必备插件
插件介绍 ***PackageControl*** 功能:安装包管理 简介:sublime插件控制台,提供添加.删除.禁用.查找插件等功能 使用方法: 1.安装好控制台,如有不能正常调用 Packag ...
- django中的ORM与 应用与补充
目录 django中的ORM与 应用与补充 ORM与数据的对应关系 ORM 常用字段 ORM 其他字段 自定义字段 字段参数 Model Meta参数 常用13中查询(必会) 单表查询的双下划线应用 ...
- Programming Ruby 阅读笔记
在Ruby中,通过调用构造函数(constructor)来创建对象 song1=Song.new("Ruby") Ruby对单引号串处理的很少,除了极少的一些例外,键入到字符串字面 ...
- linux bg和fg命令
linux下我们如果想一个任务或者程序还后台执行可以使用&,实际上linux还提供了其他任务调度的命令. bg将一个在后台暂停的命令,变成继续执行 fg将后台中的命令调至前台继续运行 jobs ...
- JS高级学习历程-7
[面向(基于)对象] 1 创建对象 在php里边,需要先找到一个类别,在通过类创建具体对象 在javascript里边,可以直接创建具体对象,后期可以再给对象丰富许多属性或方法. 1. 字面量方式创建 ...
- [Java]HashSet的工作原理
概述 This class implements the Set interface, backed by a hash table (actually a HashMap instance). It ...
- codeforces772C
给一段序列,给你去掉所有数字的顺序,输出每去掉一个数,当前联通的子序列的最大值. 倒着来,每次插入一个数,然后求联通的最大值,线段树每个节点标记一下,区间的左右是否插入了数字,还有如果有数字从左边/右 ...
- 练习三十二:用python实现:按相反的顺序输出列表的每一位值
用python实现:按相反的顺序输出列表的每一位值 1. 使用list[::-1] list1 = ["one","two","three" ...
- (转)linux dumpe2fs命令
linux dumpe2fs命令 命令名称 dumpe2fs - 显示ext2/ext3/ext4文件系统信息. dumpe2fs命令语法 dumpe2fs [ -bfhixV ] [ -o supe ...