Scrapy 增量式爬虫
Scrapy 增量式爬虫
https://blog.csdn.net/mygodit/article/details/83931009
https://blog.csdn.net/mygodit/article/details/83896412
https://blog.csdn.net/qq_39965716/article/details/81073015
一、定义
二、原理
spider构造的第一个Request请求经由引擎交给了Scheduler,Scheduler中构造一个request对象,并将这个对象存入一个Scheduler的队列中,入队之前会生成一个对应的,唯一的指纹,下一个request对象入队之前,会先比对指纹是否已经存在,以此来达到request对象去重的目的。
Scheduler中Request对象的初始化属性,其中dont_filter表示不去重,默认是False。所以scrapy框架默认是去重的。
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
Rquest
爬虫组件Spider中,负责构造request对象是 start_requests(self) 函数。Spider构造的request对象修改了dont_filter属性。
源码如下:
def start_requests(self):
cls = self.__class__
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Scrapy去重的原理
Scrapy去重原理是通过sha1()加密request对象的url,method,body属性生成一个十六进制的40位随机字符串,称为指纹。将每个request对象对应的唯一指纹保存到Scheduler队列中,下次请求时,通过对比指纹,来达到request对象去重的目的。
生成指纹集合的源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
存储在Scheduler中的reqeust队列,是放在内存上的,如果服务器关闭,或者重启,内存中的缓存就会清空,下次请求就会继续访问原来发送过的请求。
增量式爬虫的意义就是将reques队列持久化存储,以此来达到永久性的缓存。
对此需要用到scrapy_redis(需要pip install scarpy_redis),将request对象的队列和指纹集合存储的位置替换成redis。如下图所示:
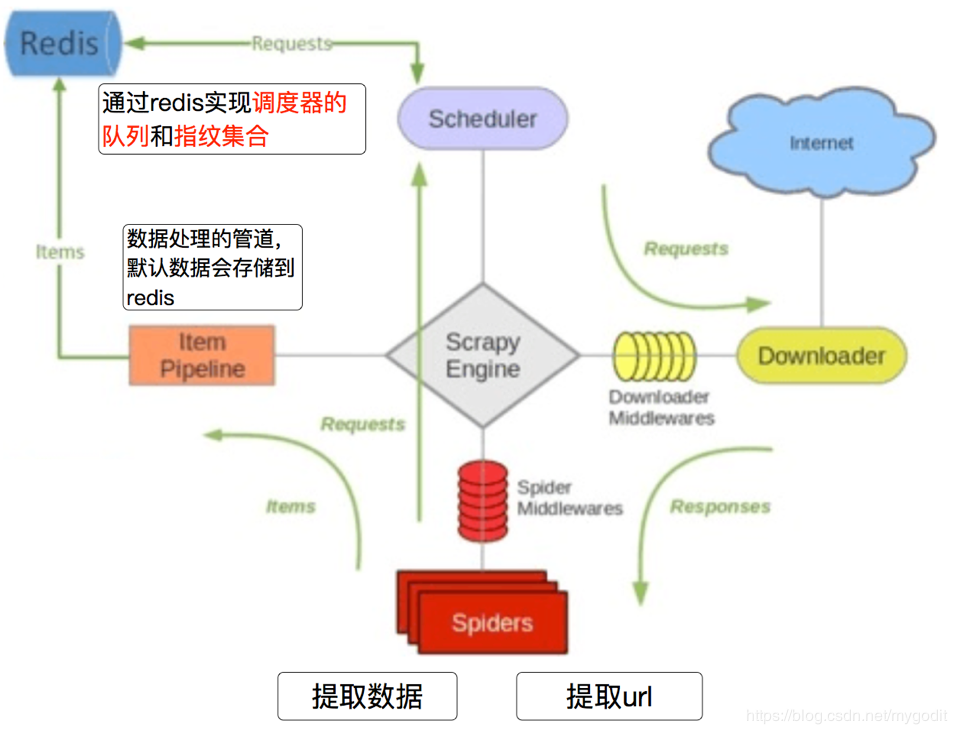
只需要在settings.py文件中添加一些配置,就能实现持久化去重的效果:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True # 添加redis链接
REDIS_URL = "redis://127.0.0.1:6379" # 或者使用下面的方式
# REDIS_HOST = "127.0.0.1"
# REDIS_PORT = 6379 # 在pipeline中添加存储信息的scrapy_redis管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
Scrapy 增量式爬虫的更多相关文章
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 增量式爬虫 Scrapy-Rredis 详解及案例
1.创建scrapy项目命令 scrapy startproject myproject 2.在项目中创建一个新的spider文件命令: scrapy genspider mydomain mydom ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- 爬虫---scrapy分布式和增量式
分布式 概念: 需要搭建一个分布式的机群, 然后在每一台电脑中执行同一组程序, 让其对某一网站的数据进行联合分布爬取. 原生的scrapy框架不能实现分布式的原因 调度器不能被共享, 管道也不能被共享 ...
- 爬虫 crawlSpider 分布式 增量式 提高效率
crawlSpider 作用:为了方便提取页面整个链接url,不必使用创参寻找url,通过拉链提取器,将start_urls的全部符合规则的URL地址全部取出 使用:创建文件scrapy startp ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- Scrapy 框架 增量式
增量式: 用来检测网站中数据的更新情况 from scrapy.linkextractors import LinkExtractor from scrapy.spiders import Crawl ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [三] 配置式爬虫
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 上一篇介绍的基本的使用方式,虽然自由度很高,但是编写的代码相对还是挺多.于是框 ...
- 增量式PID计算公式4个疑问与理解
一开始见到PID计算公式时总是疑问为什么是那样子?为了理解那几道公式,当时将其未简化前的公式“活生生”地算了一遍,现在想来,这样的演算过程固然有助于理解,但假如一开始就带着对疑问的答案已有一定看法后再 ...
随机推荐
- HTTP 与TCP/IP 、Socket区别(一)
网络由下往上分为: 物理层-- 数据链路层-- 网络层-- IP协议 传输层-- TCP协议 会话层-- 表示层和应用层-- HTTP协议 1.TCP/IP连接 手机能够使用联网功能是因为手机底层实现 ...
- 获取Request.Form所有内容
string wwww = ""; for (int i = 0; i < Request.Form.Count; i++) { ...
- socket粘包现象加解决办法
socket粘包现象分析与解决方案 简单远程执行命令程序开发(内容回顾) res = subprocess.Popen(cmd.decode('utf-8'),shell=True,stderr=su ...
- 1.1.Task Queue
任务队列是一种跨线程.跨机器工作的一种机制. 任务队列中包含称作任务的工作单元.有专门的工作进程持续不断的监视任务队列,并从中获得新的任务并处理. celery通过消息进行通信,通常使用一 ...
- 虚拟机之 搭建discuz论坛
1.下载 mkdir /data/www cd !$ wget http://download.comsenz.com/DiscuzX/3.2/Discuz_X3.2_SC_GBK.zip 2.解压 ...
- Wcf调用方式
C#动态调用WCF接口,两种方式任你选. 写在前面 接触WCF还是它在最初诞生之处,一个分布式应用的巨作. 从开始接触到现在断断续续,真正使用的项目少之又少,更谈不上深入WCF内部实现机制和原理去 ...
- OK6410 tftp下载内核、文件系…
飞凌官方提供了一键下载烧写linux的方式,相对来说比较方便,但是对于开发来说不够灵活,因此这篇文章把tftp相关的点介绍一下,整理下其中遇到的一些问题. 一键烧写本质上是启动位于SD卡中的Uboot ...
- idea写中文到mysql乱码
idea中中文写入到mysql乱码 参考如下链接: https://segmentfault.com/q/1010000006174975/a-1020000006184639
- 22-从零玩转JavaWeb-代码块
配套详解视频 局部代码块与初始化代码块 面向对象-静态代码块 代码块总结 组合关系与类的加载 静态代码块及字段初始化练习 一.什么是代码块 在类中或方法当中 使用{}括起来的一段代码 就称它是一个代码 ...
- inux php pdo mysql 扩展
今天在本机部署了一个pdo项目,发现一些问题,真没想到pdo mysql,不容易装啊,哈哈,我说的不容易,是因为php5.3以前版本,yum源里面根本没有.部署后就报,Undefined class ...