oracle 查询及删除表中重复数据
create table test1(
id number,
name varchar2(20)
);
insert into test1 values(1,'jack');
insert into test1 values(2,'jack');
insert into test1 values(3,'peter');
insert into test1 values(4,'red');
insert into test1 values(5,'green');
insert into test1 values(6,'green');
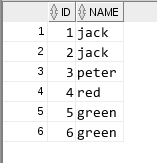
一 查询表中重复数据
1. 使用exists
select a.* from test1 a where exists (
select name from
( select name ,count(*)
from test1
group by name
having count(*)>1
) b
where a.name = b.name
);

2 join on
select a. * from test1 a
join (
select name ,count(*) from test1
group by name
having count(*)>1
) b
on a.name = b.name;
3 in
select a.name from test1 a
where a.name in
(
select name from test1
group by name
having count(*)>1
);
4 使用rowid 查询得到重复记录里,第一条插入记录后面的记录
select * from test1 a where rowid != (select min(rowid) from test1 b where b.name = a.name);
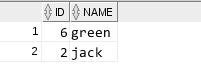
5 使用rowid查询得到重复记录里,最后一条记录之前插入的记录
select a.* from test1 a where rowid !=(select max(rowid) from test1 b where a.name=b.name);

6 使用rowid 查询得到 不重复的记录和重复记录里最后插入的一条记录
select a.* from test1 a where rowid =(select max(rowid) from test1 b where a.name=b.name);
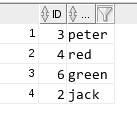
7 使用rowid 查询得到不重复的记录和重复记录里最先插入的记录
select * from test1 a where rowid = (select min(rowid) from test1 b where b.name = a.name);
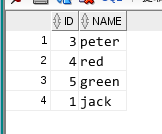
删除 所有重复不保留任何一条
delete from test1 a where exists ( select name from (select name ,count(*) from test1 group by name having count(*)>1) b where a.name = b.name);
delete from test1 a where a.name in (select name from test1 group by name having count(*)>1);
删除重复记录里,第一条重复记录后面插入的记录
delete from test1 a where rowid !=(select min(rowid) from test1 b where b.name = a.name);

删除先前插入的重复记录,保留最后插入的重复记录
delete from test1 a where rowid !=(select max(rowid) from test1 b where a.name=b.name);
oracle 查询及删除表中重复数据的更多相关文章
- 查询和删除表中重复数据sql语句
1.查询表中重复数据.select * from peoplewhere peopleId in (select peopleId from people group by ...
- mysql 查询及 删除表中重复数据
CREATE TABLE `test` ( `id` INT(20) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) NULL DEFAULT NULL, `a ...
- ROWID面试题-删除表中重复数据(重复数据保留一个)
/* ROWID是行ID,通过它一定可以定位到r任意一行的数据记录 ROWID DNAME DEPTNO LOC ------------------ ------------------------ ...
- sqlite 删除表中重复数据(亲测可用)
例子:表名 Paper .通过字段PaperID查找重复数据. 1 --查询某表中重复的数据 select * from Paper group by PaperID having co ...
- sql记录去重(SQL查询或者删除表中重复记录)
.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select*from people where peopleIdin (select peopleIdfrom peopl ...
- MySQL 数据库删除表中重复数据
采集数据的时候,由于先期对页面结构的分析不完善,导致采漏了一部分数据.完善代码之后重新运行 Scrapy,又采集了一些重复的数据,搜了下删除重复数据的方法. N.B. 删除数据表的重复数据时,请先备份 ...
- Oracle通过ROWID删除表中重复记录
-- 1 通过ROWID删除T1表里重复的记录 SELECT ROWID,A,B--DELETE FROM T1WHERE ROWID IN ( SELECT RD FROM ( ...
- oracle查询、删除表中相同的数据
delete FROM tablename a WHERE rowid > ( SELECT min(rowid) FROM tablename b WHERE b.id = a.id and ...
- SQL Server中删除表中重复数据
方法一:利用游标,但要注意主字段或标识列 declare @max integer,@id integer open cur_rows fetch cur_rows into @id,@max beg ...
随机推荐
- python 日志模块工具类
#!/usr/bin/env python # -*- coding: utf-8 -*- import logging # logName 日志中的某个格式化的字段名,logFile生成的日志文件名 ...
- NSTimeZone时区
前言 NSTimeZone 表示时区信息. 1.NSTimeZone 时区的创建 NSTimeZone *zone1 = [[NSTimeZone alloc] init]; // 根据时区名称创建 ...
- JDK、JRE、JVM三者关系
一.JDK.JRE.JVM三者的关系 JDK包含了JRE和JVM,JRE包含了JVM,其中JRE中没有javac 附一张官网的详细图: 二.RIA RIA(富客户端):能完成浏览器无法完成的功能,它是 ...
- [Swift]八大排序算法(五):插入排序
排序分为内部排序和外部排序. 内部排序:是指待排序列完全存放在内存中所进行的排序过程,适合不太大的元素序列. 外部排序:指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存 ...
- docker镜像的创建
获得更多资料欢迎进入我的网站或者 csdn或者博客园 昨天讲解了docker的安装与基本使用,今天给大家讲解下docker镜像的创建的方法,以及push到Docker Hub docker安装请点击右 ...
- 我的csdn博客地址
呆雁 持续的谦虚与努力 http://blog.csdn.net/u013539183
- MongDB from execCommand not master
count failed: not master{ , "errmsg" : "not master" } at src/mongo/shell/query.j ...
- github上传Python被识别为css--解决
在项目根目录新建文件.gitattributes 添加如下: *.css linguist-language=python把.css结尾的文件识别为python语言
- Python3之时间模块time & datetime & calendar
一. 简介 python 提供很多方式处理日期与时间,转换日期格式是一个常见的功能. 时间元组:很多python函数用一个元组装起来的9组数字处理时间. python中时间日期格式化符号: %y 两位 ...
- SDUT OJ 数据结构实验之二叉树三:统计叶子数
数据结构实验之二叉树三:统计叶子数 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Problem Descr ...