【flume】5.采集日志进入hbase
设置我们的flume配置信息
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License. # The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent' agent1.sources = r1
agent1.channels = c1
agent1.sinks = s1 # For each one of the sources, the type is defined
agent1.sources.r1.type = exec
#tail -F /home/oss/cloud_iom/ktpt/iom-cloud-service/logs/iom-app-debug.log
agent1.sources.r1.command = tail -F /home/oss/cloud_iom/ktpt/iom-cloud-service/logs/iom-app-debug.log # The channel can be defined as follows.
#agent.sources.seqGenSrc.channels = memoryChannel
agent1.sources.r1.channels = c1 # Each sink's type must be defined
agent1.sinks.s1.type = hbase2 agent1.sinks.s1.table = iom_app_debug
agent1.sinks.s1.columnFamily = log
agent1.sinks.s1.serializer = org.apache.flume.sink.hbase2.RegexHBase2EventSerializer
#agent1.sinks.s1.serializer.regex = \\[(.*?)\\]\\ \\[(.*?)\\]\\ \\[(.*?)\\]\\ \\[(.*?)\\] #Specify the channel the sink should use
agent1.sinks.s1.channel = c1 # Each channel's type is defined.
agent1.channels.c1.type = memory # Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
agent1.channels.c1.capacity = 100
这个脚本配置好,设置启动命令,使用nohup是为了之后采集器自己后期自动运行
nohup flume-ng --conf hadoop/flume/conf -f hadoop/flume/conf/flume-conf.properties -n agent1 -Dflume.root.logger=DEBUG,console &
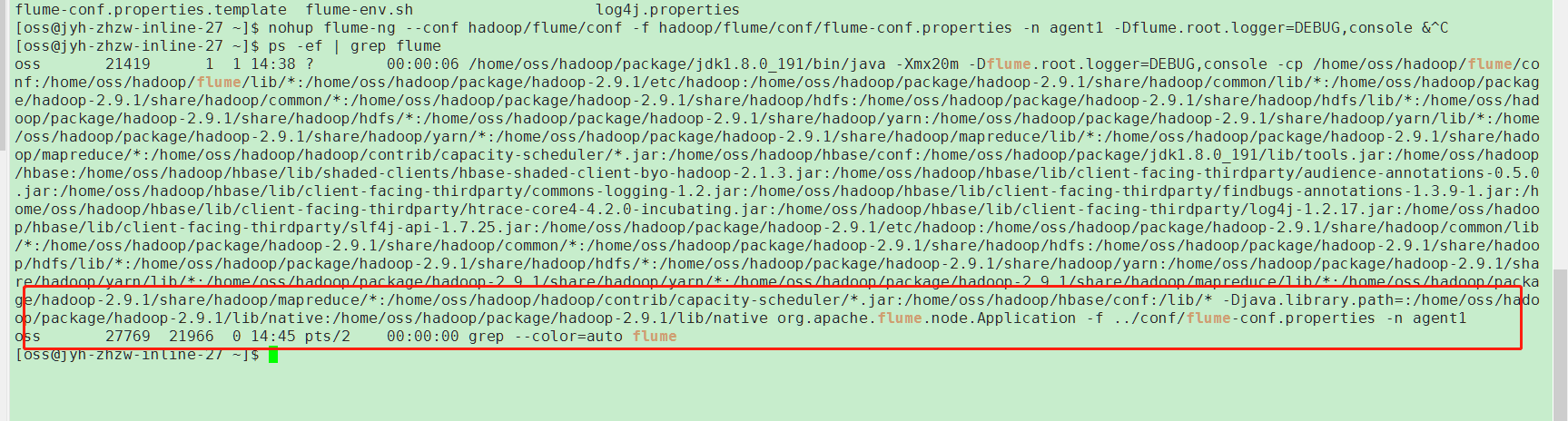
我的flume目录:

采集截图

日志文件截图
当然,这里是按行进行采集的(用的tail -F),但是shell脚本可以自己定义,只要type配置的是exec,后面sink对象也可以自己配置
第一步数据采集,第二步应该是想想如何进行数据分析,当然这样采集的数据直接分析的可能性也不太大,而且数据杂乱无序,我们还需要定义相应的逻辑先对数据进行清洗,然后再采集进去
这里这样采集是有问题的,正确的做法应该是
1.flume采集数据进入hdfs
2.MapReduce对采集进入的数据进行数据清洗,整理数据
3.MapReduce分析数据,解析入库进入hbase,或者直接保存到hdfs
4.sqoop 迁移数据到对应的数据库(mysql,Oracle)
5.根据解析之后的数据,查询Oracle制作报表图像,分析趋势,预测,或者定位问题关系
【flume】5.采集日志进入hbase的更多相关文章
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- Flume线上日志采集【模板】
Flume线上日志采集[模板] 预装软件 Java HDFS Lzo/Lzop 系统版本 Flume 1.5.0-cdh5.4.0 系统流程图 flume-env.sh配置文件 export JAVA ...
- Flume采集日志
角色 Source 数据来源 (exec, kafka, http…)Channel 数据通道 (memory,file,jdbc)Sink 数据目的地 (kafka,hdfs,es…) Agent ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 基于Flume的美团日志收集系统(一)架构和设计【转】
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 采用Flume实时采集和处理数据
它已成功安装Flume在...的基础上.本文将总结使用Flume实时采集和处理数据,详细过程,如下面: 第一步,在$FLUME_HOME/conf文件夹下,编写Flume的配置文件,命名为flume_ ...
- flume学习(三):flume将log4j日志数据写入到hdfs(转)
原文链接:flume学习(三):flume将log4j日志数据写入到hdfs 在第一篇文章中我们是将log4j的日志输出到了agent的日志文件当中.配置文件如下: tier1.sources=sou ...
- 转:基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- 深入浅出ES6教程『async函数』
大家好,本人名叫苏日俪格,大家叫我 (格格) 就好,在上一章节中我们学到了Symbol & generator的用法,下面我们一起来继续学习async函数: async [ə'zɪŋk]:这个 ...
- springMVC Controller 参数映射
springMVC 对参数为null或参数不为null的处理 - 小浩子的博客 - CSDN博客https://blog.csdn.net/change_on/article/details/7664 ...
- js中const,var,let区别与用法(转)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_36784628/article/d ...
- PostgreSQL 登录时在命令行中输入密码
有时候需要设置定时任务直接执行 sql 语句,但是 postgresql 默认需要人工输入密码,以下命令可以直接在命令行中直接填入密码 PGPASSWORD=pass1234 psql -U MyUs ...
- Leetcode: 24 Game
You have 4 cards each containing a number from 1 to 9. You need to judge whether they could operated ...
- Flutter 中AlertDialog确认提示弹窗
import 'package:flutter/material.dart'; import 'dart:async'; enum Action { Ok, Cancel } class AlertD ...
- openresty开发系列24--openresty中lua的引入及使用
openresty开发系列24--openresty中lua的引入及使用 openresty 引入 lua 一)openresty中nginx引入lua方式 1)xxx_by_lua ---> ...
- jmeter中特殊的时间处理方式
需求: 1.获取当前时间的年月日时分秒毫秒 2.生成上一个月的随机某天的一个时间 3.生成一个年月日时分秒毫秒的一个时间戳 1.__time : 获取时间戳.格式化时间 ${__time(yyyy-M ...
- Dart中的类型转换总结:
1.Dart中数组转换为字符串:join var a=[1,2,3,4]; var str=a.join(',');
- linux安装qt
1.下载run文件 2../运行 3.修改配置文件 sudo gedit /etc/profile 添加如下: port QTDIR=/home/rainbow/zhuxy/soft/Qt5.9.0/ ...