ubuntu之路——day8.5 学习率衰减learning rate decay
在mini-batch梯度下降法中,我们曾经说过因为分割了baby batch,所以迭代是有波动而且不能够精确收敛于最小值的
因此如果我们将学习率α逐渐变小,就可以使得在学习率α较大的时候加快模型训练速度,在α变小的时候使得模型迭代的波动逐渐减弱,最终收敛于一个较小的区域来得到较为精确的结果
首先是公式1学习率衰减的标准公式:

其中decay rate即衰减率,epoch-num指的是遍历整个训练集的次数,α0是给定的初始学习率
其次是公式2指数衰减公式:
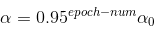
其中,0.95是一个小于1的初始值,可以指定
接下来公式3,k是一个常数:
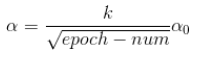
公式4,t是mini-batch的大小:
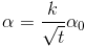
公式5:
离散下降法,每经过一定的迭代次数,指定更低的α即可
公式6:
手动下降法,适用于在小数据集上分步骤实验,可以随时指定α
ubuntu之路——day8.5 学习率衰减learning rate decay的更多相关文章
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- pytorch learning rate decay
关于learning rate decay的问题,pytorch 0.2以上的版本已经提供了torch.optim.lr_scheduler的一些函数来解决这个问题. 我在迭代的时候使用的是下面的方法 ...
- ubuntu之路——day8.4 Adam自适应矩估计算法
基本上讲,Adam就是将day8.2提到的momentum动量梯度下降法和day8.3提到的RMSprop算法相结合的优化算法 首先初始化 SdW = 0 Sdb = 0 VdW = 0 Vdb = ...
- mxnet设置动态学习率(learning rate)
https://blog.csdn.net/xiaotao_1/article/details/78874336 如果learning rate很大,算法会在局部最优点附近来回跳动,不会收敛: 如果l ...
- ubuntu之路——day11.7 end-to-end deep learning
在传统的数据处理系统或学习系统中,有一些工作需要多个步骤进行,但是端到端的学习就是用一个神经网络来代替中间所有的过程. 举个例子,在语音识别中: X(Audio)----------MFCC----- ...
- ubuntu之路——day8.1 深度学习优化算法之mini-batch梯度下降法
所谓Mini-batch梯度下降法就是划分训练集和测试集为等分的数个子集,比如原来有500W个样本,将其划分为5000个baby batch,每个子集中有1000个样本,然后每次对一个mini-bat ...
- ubuntu之路——day8.3 RMSprop
RMSprop: 全称为root mean square prop,提及这个算法就不得不提及上篇博文中的momentum算法 首先来看看momentum动量梯度下降法的过程: 在RMSprop中: C ...
- ubuntu之路——day8.2 深度学习优化算法之指数加权平均与偏差修正,以及基于指数加权移动平均法的动量梯度下降法
首先感谢吴恩达老师的免费公开课,以下图片均来自于Andrew Ng的公开课 指数加权平均法 在统计学中被称为指数加权移动平均法,来看下面一个例子: 这是伦敦在一些天数中的气温分布图 Vt = βVt- ...
随机推荐
- centOS学习part5:oracle 11g安装之环境准备
0 前几篇依次向大家介绍了centOS的基本安装以及常用软件的安装配置,接下来我们将挑战的是oracle 11g的安装配置.与之前安装的软件不一样的是,由于oracle并非开源免费软件(需要向orac ...
- org.springframework.dao.DuplicateKeyException: 问题
转自:https://blog.51cto.com/chengxuyuan/1786938 org.springframework.dao.DuplicateKeyException: a diffe ...
- Android gradle用exclude排除引用包中的dependency引用
项目突然编译不通过,报如下错误 FAILURE: Build failed with an exception. * What went wrong: Execution fai ...
- 用D3.js画树状图
做项目遇到一个需求,将具有层级关系的词语用树状图的形式展示它们之间的关系,像这样: 或者是这样: 上面的图片只是样例,跟我下面的代码里面用的数据不同 网上有很多这种数据可视化展示的js控件,我这里选择 ...
- 安装opencv出现的问题
ImportError: DLL load failed***** 1,pip uninstall opencv-python 卸载2,pip install opencv-contrib-pytho ...
- 基于335X的Linux网口驱动分析
基于335X的linux网口驱动分析 一. 系统构成 1. 硬件平台 AM335X 2. LINUX内核版本 4.4.12 二. 网口驱动构架(mdio部分) mdio网口驱动部分 使用 总线.设 ...
- 虚拟机搭建IKUAI软路由
1.登录爱快软路由的官网下载镜像(支持ISO ,GHO),这里采用iso安装 2.选择好后开机(选择数字编号1,回车) 3.输入“y”回车,程序自动安装 4.安装成功后如图 5.设置IP 6.绑定网卡 ...
- USB之基本协议和数据波形1
============= 本系列参考 ============= <圈圈教你玩USB>.<Linux那些事儿之我是USB> 协议文档:https://www.usb.or ...
- (Linux基础学习)第四章:Linux系统中的日期和时间介绍和ntpdate命令
第1节:日期和时间1.Linux的两种时钟:系统时钟:由Linux内核通过CPU的工作频率进行的硬件时钟:主板2.相关命令date 显示和设置系统时间hwclock,clock 显示硬件时钟-s,-- ...
- oracle添加序列
原文地址 http://blog.itpub.net/24099965/viewspace-1116923/ 1.创建.删除 create sequence seq_newsId increment ...